저널 슈퍼브에이아이 ZERO, CVPR 2026 퓨샷 객체 탐지 챌린지 1위 슈퍼브에이아이가 CVPR 2026 퓨샷 객체 탐지 챌린지에서 1위를 차지했습니다. 산업 특화 비전 파운데이션 모델 '제로(ZERO)'로 20개 산업 도메인 평균 mAP 53.9를 기록하며, 작년 4위에서 1년 만에 오른 한국 기업 최초의 우승입니다.
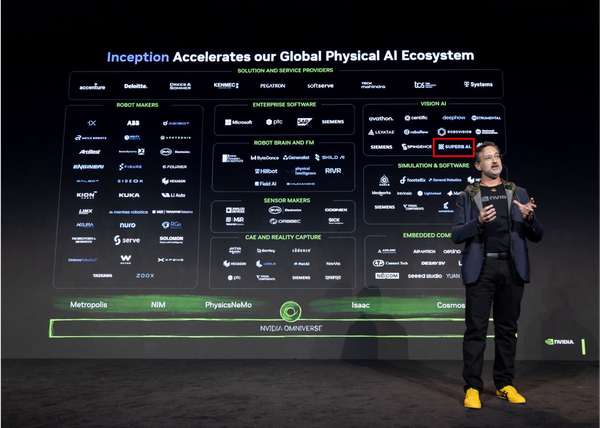
저널 젠슨 황 GTC 타이베이 2026 키노트에 등장한 슈퍼브에이아이, 엔비디아가 선택한 산업용 비전 AI 파트너 젠슨 황 엔비디아 CEO의 GTC 타이베이 2026 키노트 파트너 에코시스템에 슈퍼브에이아이가 이름을 올렸습니다. NVIDIA Inception, 피지컬 AI 에코시스템 파트너, VSS 블루프린트까지, 엔비디아가 선택한 산업용 비전 AI 파트너십의 의미를 정리합니다.
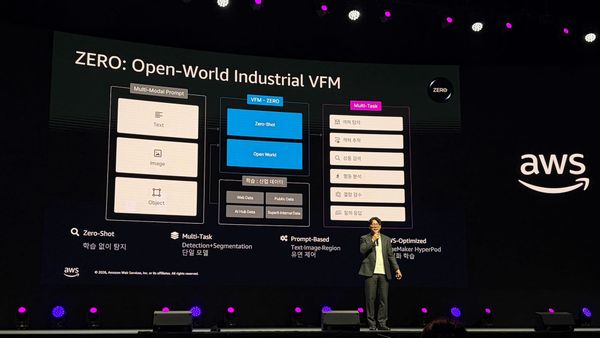
저널 H200 32장으로 비전 AI 파운데이션 모델 8개월 만에 학습한 방법 — AWS 서밋 서울 2026 발표 슈퍼브에이아이는 AWS SageMaker HyperPod에서 NVIDIA H200 32장으로 산업 특화 비전 파운데이션 모델 '제로(ZERO)'를 단 8개월 만에 학습 완료했습니다. 400만 장 데이터 파이프라인, FSx 병목 해결, Flexible Training Plan으로 비용 40% 절감한 실전 노하우를 공개합니다.
저널 수동 관제를 넘어 자율 관제로: AI 영상관제의 다음 진화 CCTV는 늘었지만 사람이 모니터를 보는 수동 관제 방식은 한계에 도달했습니다. 영상관제는 수동 관제에서 지능형 관제, 그리고 자율 관제로 진화하고 있습니다. 슈퍼브에이아이의 비전 파운데이션 모델 ‘제로(ZERO)’와 AI 영상관제 솔루션 ‘슈퍼브 VA’가 만드는 자율형 영상 관제 시스템을 소개합니다.
저널 [AI Tech 2026] 제조·물류·건설 현장의 AX(AI 전환)를 이끄는 비전 AI 실전 사례 단순히 현장을 '보던' 비전 AI가 공정을 분석하고 위험을 예방하며 불량을 잡아내는 '두뇌'로 진화하고 있습니다. 표준공정 자동 추출(SOP), 제로샷 안전관제, MLOps 기반 불량 검사까지, 슈퍼브에이아이의 산업 AX 적용 사례를 소개합니다.
저널 제조 현장의 안전·품질·공정 혁신: 2026 AWS 컨퍼런스 비전 AI 도입 사례 안전 사고 제로, 불량률 감소, 공정 효율화를 위한 제조 현장 Vision AI 도입 사례. 2026 AWS 컨퍼런스에서 슈퍼브에이아이가 발표한 지속 가능한 스마트팩토리 AI 시스템(MLOps) 구축 가이드를 만나보세요.
저널 비전 AI 도입의 딜레마, SI형 vs 기성품 솔루션 완전 분석 산업용 비전 AI 도입 시 겪게 되는 SI(맞춤형)와 기성품 벤더 사이의 양극화 딜레마. 정확도와 배포 속도를 모두 잡는 완벽한 해결책은 무엇일까요? 파운데이션 모델(VFM)과 데이터 중심 AI로 전사적 확장에 성공하는 비전 AI 전략을 지금 확인해 보세요.
저널 슈퍼브에이아이 엔비디아 GTC 2026 공식 초청 참가: 물류 현장의 피지컬 AI 혁신 엔비디아 GTC 2026에 공식 초청된 슈퍼브에이아이가 물류 현장의 단절된 OT와 IT를 연결하는 '피지컬 AI' 혁신을 선보입니다. VLM 기반의 지능형 영상 관제로 수동적인 창고 인프라를 능동적인 비즈니스 인사이트로 전환하는 방법을 확인해 보세요.
저널 산업 현장 AI 도입을 가속하는 비전 AI 전략과 파트너십 산업 현장에서 AI가 PoC를 넘어 실제 운영으로 이어지려면 무엇이 필요할까요? AW 2026 미니세미나 발표를 바탕으로 Vision AI, MLOps, 파트너십 전략을 정리했습니다.
저널 [2026 산업지능화 컨퍼런스] 피지컬 AI로의 확장과 현장 도입 전략 2026 산업지능화 컨퍼런스에서 슈퍼브에이아이 이재민 본부장이 발표한 '피지컬 AI' 핵심 내용을 요약합니다. 비전 AI의 단순 인식을 넘어, 로봇이 스스로 공간을 이해하고 행동하는 피지컬 AI 트렌드와 현장 도입을 위한 4단계 성공 전략을 지금 바로 확인해 보세요.
저널 제조 AI는 왜 PoC에서 멈출까? 자율제조 3단계 실행 로드맵 2026 AI 자율제조혁신 컨퍼런스에서 슈퍼브에이아이 이현동 부대표는 제조 AI가 현장에서 멈추는 이유를 데이터의 늪, 배포의 벽, 고도화의 절벽이라는 3단계 병목으로 설명했습니다. 이번 발표를 바탕으로 자율제조로 가기 위한 실행 로드맵과 슈퍼브에이아이의 End-to-End 접근법을 살펴봅니다.
저널 제조업 AI 도입, '현장 노하우'가 반영 안 되면 실패합니다: HITL 도입 가이드 제조업 AI, 무인화가 정답일까요? 현장 전문가의 노하우를 AI에 이식하여 '안전한 자동화'를 만드는 HITL(Human-in-the-Loop) 전략을 소개합니다. 정확도 경쟁을 넘어, 실제 운영 가능한 AI를 설계하는 슈퍼브에이아이의 노하우를 확인해보세요.
저널 피지컬 AI 시대, 품질·생산성의 새로운 기준을 제시하는 SOP 피지컬 AI 시대, 제조 현장을 넘어 물류 패키징과 리테일 매장 관리까지 확장된 슈퍼브에이아이의 SOP 모니터링 기술을 소개합니다. 비전 AI가 정상 작업 흐름을 스스로 학습하여 미세한 공정 이탈을 실시간으로 감지하고, 기업의 노하우를 데이터 자산화하여 품질 균일화와 생산성 향상을 동시에 달성하는 방법을 확인해 보세요.
저널 엔비디아 피지컬 AI 생태계의 핵심 비전 AI 파트너 슈퍼브에이아이 CES 2026에서 젠슨 황이 선언한 '피지컬 AI(Physical AI)' 시대의 개막과 엔비디아의 로보틱스 생태계를 심층 분석합니다. 엔비디아의 핵심 Vision AI 파트너로 선정된 슈퍼브에이아이가 3D 공간 인식, MTMC, 에이전틱 AI 기술을 통해 어떻게 산업 현장을 혁신하고 있는지, 글로벌 P사의 실제 도입 사례와 함께 확인해 보세요.
저널 젠슨 황이 선언한 ‘로보틱스의 챗GPT 시대’, 피지컬 AI의 핵심 파트너 슈퍼브에이아이 CES 2026에서 젠슨 황이 선포한 '피지컬 AI'와 로보틱스의 챗GPT 시대! 현대차 아틀라스, 보스턴 다이내믹스 등 일상과 현장에 적용된 로봇을 비롯해 피지컬 AI 생태계와 파트너십까지 정리해 드립니다.
저널 ⑪ 독일 피지컬 AI 현황: 지멘스, BMW, 그리고 로봇 유니콘의 반격 인더스트리 4.0을 넘어 '행동하는 AI'로. 독일 산업계가 피지컬 AI에 사활을 걸었습니다. 베를린 팩토리의 휴머노이드 실험부터 지멘스의 산업용 메타버스 구현까지, 제조 강국 독일이 보여주는 2025년 로봇 자동화와 스마트 팩토리의 미래를 확인하세요.
저널 ⑩ 미국 빅테크 피지컬 AI 트렌드(2): 테슬라 vs 아마존 전략 분석 2025년 하반기, AI 거품론을 잠재울 '피지컬 AI(Physical AI)'의 시대가 열립니다. 테슬라의 숨 고르기와 Figure AI 연합군의 약진, 아마존의 100만 로봇 군단이 예고하는 노동의 종말, 중국의 거센 추격까지. 디지털 두뇌를 넘어 물리적 현실로 확장된 미국 빅테크의 대재산업화(Re-Industrialization) 전략과 로봇 패권 경쟁의 최전선을 심층 분석합니다.
저널 ⑨ 미국 빅테크 피지컬 AI 트렌드(1): 엔비디아 vs 구글 전략 분석 챗봇을 넘어 '피지컬 AI' 시대로 진입한 미국 빅테크의 동향을 살펴봅니다. 엔비디아의 Cosmos 월드 모델과 구글 Gemini 3의 공간 지능 등, 현실 세계를 장악하기 위한 양대 기업의 핵심 전략과 기술 혁신을 심층 분석합니다.
저널 ⑧ 피지컬 AI 최강자? 엔비디아 코스모스가 로보틱스 훈련 방식을 바꾸다 '피지컬 AI', 로보틱스 훈련 방식을 바꿔버린 엔비디아 코스모스(NVIDIA Cosmos) 2.5를 심층 분석합니다. 실제 사용중인 Skild AI와 Serve Robotics 사례도 같이 소개합니다. '데이터 '생성'을 넘어 '선별'과 '큐레이션'이 왜 피지컬 AI 성공의 핵심인지, 슈퍼브에이아이의 전략과 함께 확인하세요.
저널 ⑦ 피지컬 AI 훈련, '진짜' 데이터가 아닌 '합성 데이터'가 답인 이유 2025년 최대 화두인 피지컬 AI 는 '데이터 격차' 라는 한계에 부딪혔습니다. 이 문제를 해결할 핵심 열쇠인 '합성 데이터' 와 치명적인 'Sim-to-Real(현실 격차)' 문제의 해소 전략을 심층 분석합니다.
저널 ⑥ 구글 Gemini Robotics와 엔비디아 Newton: 피지컬 AI 혁신의 최전선 구글의 Gemini Robotics 1.5, 엔비디아의 Newton 물리엔진과 Isaac GR00T 모델 등 피지컬 AI의 최신 동향을 소개합니다. 산업 현장에 특화된 슈퍼브에이아이의 비전 파운데이션 모델 ZERO와 MLOps 플랫폼이 이러한 글로벌 혁신과 어떻게 맞닿아 있는지 살펴봅니다.
VFM ⑤ 보는 것을 넘어, 행동을 지배하다: 비전 AI에서 피지컬 AI로의 기술 혁명 생성형 AI 다음 혁명은 단연 '피지컬 AI'입니다. 로봇, 자율주행, 스마트팩토리의 핵심인 '보는 능력', 즉 비전 AI 기술이 어떻게 60조 달러 규모의 물리 산업을 혁신하는지, 슈퍼브에이아이의 핵심 전략을 통해 확인해 보세요.
저널 물리적 세계를 위한 지능의 설계: K-AI 기업 슈퍼브에이아이 글로벌 기술 패권의 격전지가 된 피지컬 AI 시대. 대한민국 '독자 AI 파운데이션 모델' 프로젝트의 핵심 사업자로 선정된 슈퍼브에이아이가 LG AI연구원 컨소시엄과 함께 어떻게 데이터 중심 AI 기술로 산업 현장을 혁신하고 AI 주권을 확보하는지 확인해 보세요.
공공·보안 사례 MIT 리포트 분석: 공공기관 AI, 파일럿 단계에서 멈추지 않고 성공하는 법 공공기관 AI 도입 프로젝트의 95%는 왜 성과를 내지 못할까요? MIT 리포트가 밝힌 실패 원인 '학습 격차'를 극복하고, 실제 성공 사례로 검증된 전략·데이터·프로세스 기반의 성공 방정식을 확인하세요.
저널 ④ 성공적인 피지컬 AI 도입 전략: 4단계 실행 로드맵으로 ROI 극대화하기 성공적인 피지컬 AI 도입을 위한 A to Z 가이드. 기업 의사결정권자를 위해 AI 프로젝트 실패 원인을 분석하고, ROI를 극대화하는 4단계 데이터 전략 및 실행 로드맵을 명확하게 제시합니다.



![[AI Tech 2026] 제조·물류·건설 현장의 AX(AI 전환)를 이끄는 비전 AI 실전 사례](https://storage.ghost.io/c/73/74/73741b5e-0bdf-4e6f-9161-743bc6f76d78/content/images/size/w600/2026/05/IMG_7133.JPG)




![[2026 산업지능화 컨퍼런스] 피지컬 AI로의 확장과 현장 도입 전략](https://storage.ghost.io/c/73/74/73741b5e-0bdf-4e6f-9161-743bc6f76d78/content/images/size/w600/2026/03/superb-ai-1.jpeg)