혼동 행렬이란? - 모델 진단에 사용되는 지표와 활용 방안 알아보기 Part 1

모델 진단에 사용되는 지표와 활용 방안에 대해 궁금하신가요?
모델 평가 지표는 모델 개발자 및 사용자가 모델의 성능을 이해하고 비교할 수 있게 해주어, 모델 개선을 위한 방향을 제시해 줍니다. 선택한 평가 지표는 모델의 특성과 목표에 따라 달라질 수 있으므로, 문제의 본질과 목표를 고려하여 적절한 평가 지표를 선택해야 합니다.
관련 블로그글 확인하기
모델 진단에 활용되는 지표
슈퍼브 큐레이트에서 제공하는 (또는 성능 평가에 사용되는) 주요 지표는 아래와 같습니다.
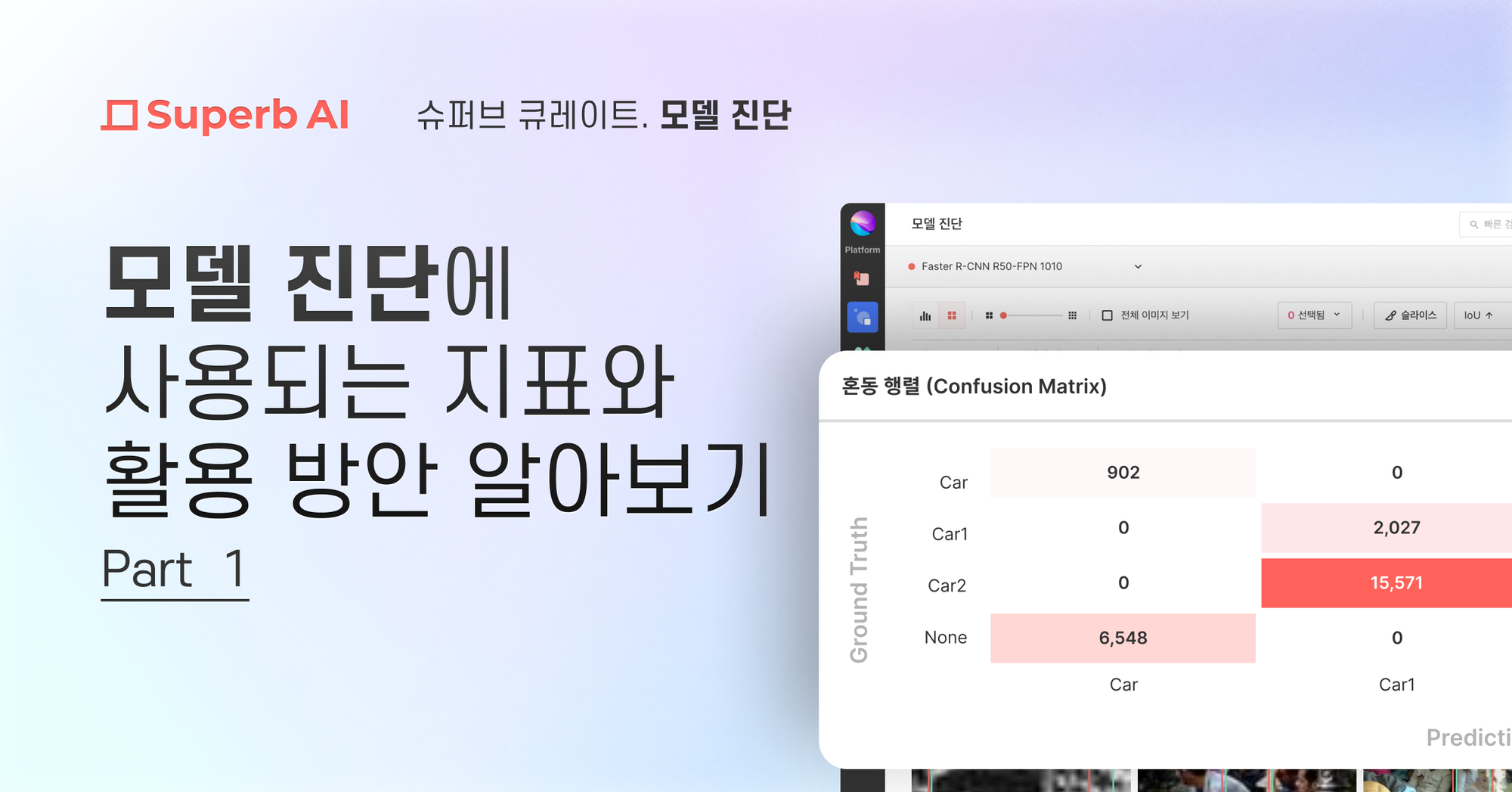
1. 혼동 행렬 (Confusion Matrix)
학습된 AI 모델의 성능을 평가하기 위해 가장 기본이 되는 표입니다. 가로, 세로 중 한 쪽에는 정답 데이터(Ground Truth)에 해당하는 클래스를, 다른 한쪽에는 모델의 예측에 해당하는 클래스를 표시합니다.
모델의 성능을 평가할 검증 데이터셋 (Validation Set)에 대해서, 정답 데이터 값과 모델 예측(Model Prediction) 값을 비교하며 표 안에 숫자를 기입합니다.
예를 들어, 10장의 사진 중에서:
- Good(실제 양품) 6개, 그중 AI 모델이 5개를 정확히 맞히고 1개는 불량품으로 잘못 분류
- Not Good(실제 불량품) 4개, 그중 AI 모델이 2개를 정확히 맞히고 2개는 양품으로 잘못 분류
…인 경우에는 혼동 행렬 값은 아래와 같습니다.
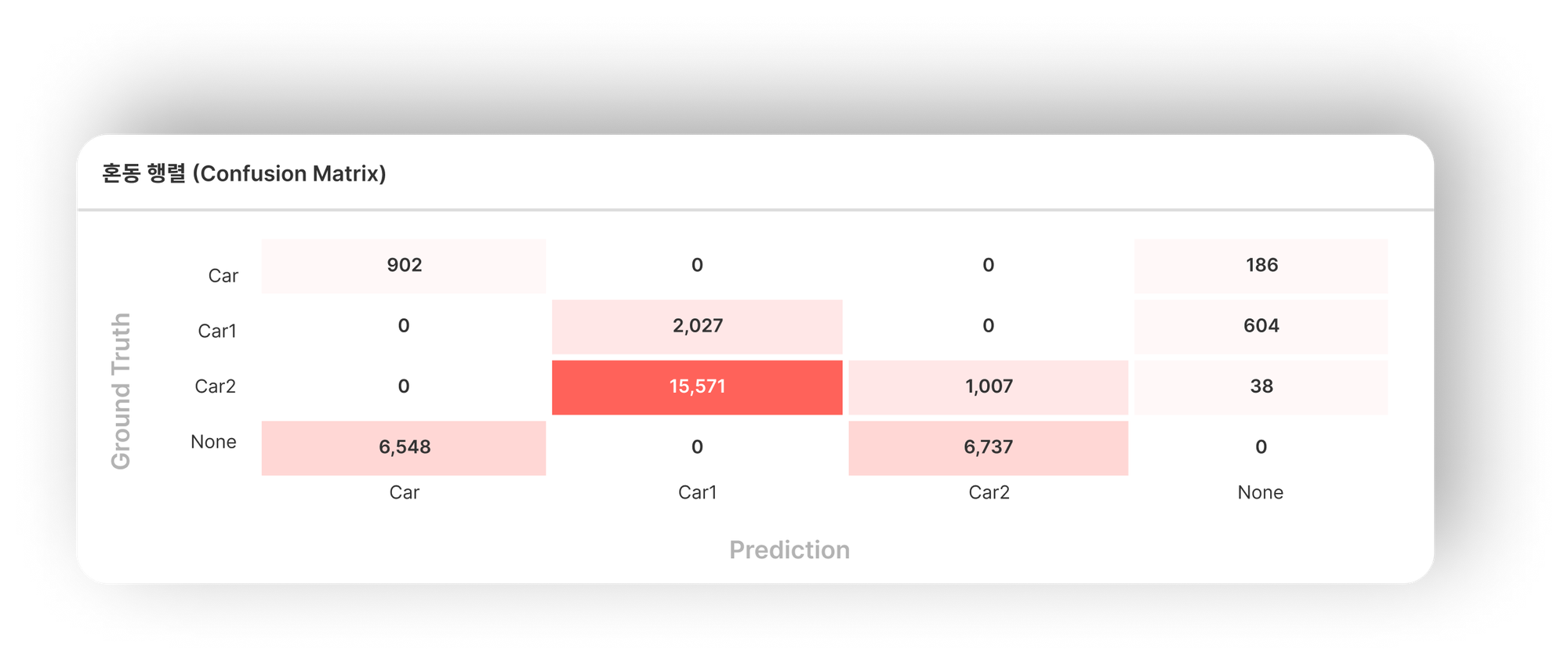
다른 예시로, 여러 장의 사진 속에
- 자동차가 5번 등장하는데, 그중에서 AI 모델이 그중 3번은 정확하게 맞추고, 한번은 사람이라고 잘못 인식하고, 한번은 아예 인식을 못 한 경우,
- 사람이 4번 등장하는데, 그중에서 AI 모델이 2번 정확하게 맞추고, 두 번은 탐지하지 못한 경우,
- 그리고 마지막으로, 아무런 사물이 없는 위치에 자동차와 사람이 있다고 각각 한 번씩 착각하여 예측한 경우
…에는 혼동 행렬 값은 아래와 같습니다.
이렇게 혼동 행렬을 활용하면, 한눈에 모델의 성능이 어떤지, 그리고 어떤 특정 클래스에 대한 성능이 높고 낮은지 등을 파악할 수 있어서 용이합니다.
예를 들어, 좌측 상단부터 우측 하단까지 이어지는 대각선 상에 위치한 값들은 'True Positive'라고 표현하는, 즉 모델이 예측한 클래스와 정답과 일치하는 경우이고, 이 값들이 높을수록 모델의 성능이 좋다고 할 수 있습니다. 반대로, 이 대각선 상에 위치하지 않은 값들을 참고하여 어느 두 클래스 사이에서 혼동이 많이 일어나는지 확인할 수 있습니다.
2. 정밀도 (Precision)
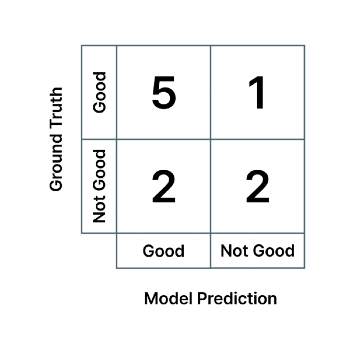
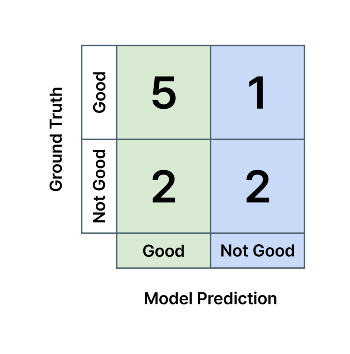
모델이 예측한 클래스와 실제 정답 클래스(정답 데이터 라벨)과 일치하는 비율을 나타냅니다. 예를 들어, 제조업에서 불량품 검수를 하는 분류 AI(Classification AI) 모델이 다음과 같은 혼동 행렬을 가진다고 하면, 모델의 '양품' 검출 정밀도는 5/(5+2) = 0.71, '불량품' 검출 정밀도는 2/(1+2) = 0.67 입니다. 각각 초록색, 파란색 열의 값들을 이용하여 계산합니다.
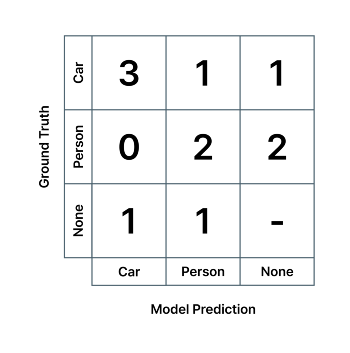
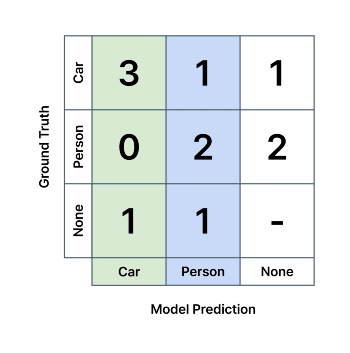
영상 속에 자동차와 사람을 인식하는 검출 AI가 다음과 같은 혼동 행렬을 가진다고 하면, 모델의 Car 클래스에 대한 정밀도는 3/(3+0+1) = 0.75, Person 클래스 검출 정밀도는 2/(1+2+1) = 0.5 입니다. 즉, AI 모델이 자동차와 사람이라고 예측한 것 중 75%와 50%만 실제로 자동차와 사람이였다는 뜻으로, 얼마나 모델의 예측이 '정밀한지' (균일하고 일관적인지)를 나타냅니다. 마찬가지로 각각 초록색, 파란색 열의 값들을 이용하여 계산합니다.

3. 재현율 (Recall)
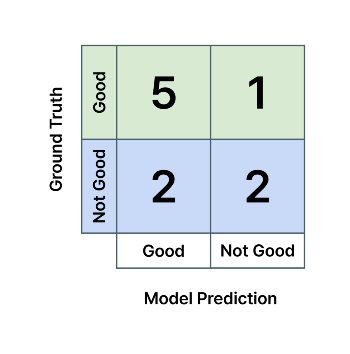
실제 정답 클래스 중 모델이 예측한 클래스와 일치하는 비율을 나타냅니다. 예를 들어, 제조업에서 불량품 검수를 하는 분류 AI 모델이 다음과 같은 혼동 행렬을 가진다고 하면, 모델의 '양품' 검출 재현율은 5/(5+1) = 0.83, '불량품' 검출 재현율은 2/(2+2) = 0.5 입니다. 각각 초록색, 파란색 행의 값들을 이용하여 계산합니다.
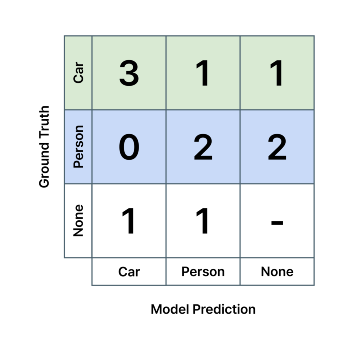
영상 속에 자동차와 사람을 인식하는 검출 AI가 다음과 같은 혼동 행렬을 가진다고 하면, 모델의 Car 클래스에 대한 재현율은 3/(3+1+1) = 0.6, Person 클래스 검출 재현율은 2/(0+2+2) = 0.5 입니다. 즉, AI 모델은 실제 존재하는 자동차와 사람 중 절반만 찾아냈다는 뜻이고, 얼마나 모델의 예측으로 실존하는 객체들을 '재현'해낼 수 있는지를 뜻합니다. 마찬가지로 각각 초록색, 파란색 열의 값들을 이용하여 계산합니다.

모델 진단에 활용되는 용어 설명
여기서 잠깐!
모델의 성능을 평가하고, 모델의 예측 결과를 이해할 때 종종 'True', 'False', 'Positive', 'Negative'라는 용어가 사용되는데, 어떤 의미인지 명확히 이해하는 것이 중요합니다.
1. 'True', 'False' 등의 표현:
- 이 표현들이 단독으로 사용되는 경우는 보통 ‘True’ 또는 ‘False’라는 클래스의 이름을 나타냅니다. 예를 들어, 모델이 True/False 두 개의 클래스 중에서 하나를 선택하여 예측할 때의 'True' 클래스를 말합니다. 모델이 특정 데이터를 'True' 클래스로 분류했다는 것은 이 데이터에 대한 모델의 예측값이 'True'라는 의미입니다.
2. 'Positive', 'Negative' 등의 표현:
- ‘Positive는’ AI 모델이 어떤 값을 출력했을 때를, ‘Negative’는 출력하지 않았을 때를 표현합니다.
3. 'True Positive', 'False Positive' 등의 표현:
- 이렇게 ‘True/False’와 ‘Positive/Negative’가 같이 사용되는 경우는 총 4가지가 있습니다: True Positive, False Positive, True Negative, False Negative.
- 이 표현들은 모델이 어떠한 클래스를 예측하였을 때 (즉, 'Positive'), 이 예측한 클래스가 정확했는지 (정답 데이터 클래스와 일치하는지; 즉 ‘True Positive’) 부정확한지 (정답 데이터 클래스와 불일치하는지, 즉 ‘False Positive’)를 나타냅니다. 반대로, 모델이 특정 클래스 값을 출력하지 않았을 때 (즉, 'Negative'), 이렇게 출력하지 않은 것이 정확한지 (정답 데이터 클래스와 일치하는지; 즉 ‘True Negative’) 부정확한지 (정답 데이터 클래스와 불일치하는지, 즉 ‘False Negative’)를 나타냅니다.
- 예를 들어, AI 모델이 '사람'을 탐지했다고 출력했는데, 해당 위치에 실제로 사람이 있는 경우 (정답 데이터에 사람이 있는 경우) True Positive라고 합니다. 반대로, AI 모델이 '사람'을 탐지했다고 출력했는데, 해당 위치에 실제로 사람이 없는 경우에는 (정답 데이터에 사람이 없는 경우) False Positive라고 하고, 오검출이라고도 합니다.
- 또 다른 예시로, 사진 속 특정 위치에 '사람'이 존재하는데, AI 모델이 이를 탐지하지 못했다면 False Negative라고 하고, 미검출이라고도 합니다. AI 모델이 해당 위치를 다른 클래스로 잘못 예측한 경우 역시, 해당 위치에 존재하는 사람을 탐지하는 데에는 실패했기 때문에 False Negative가 됩니다.
쉬운 이해를 위해, 'Positive'나 'Negative'는 모델이 특정 클래스를 출력하였는지 유무를, 'True'나 'False'는 그 예측의 정확도를 나타내는 것으로 기억하면 좋습니다.
위 혼동 행렬의 예시를 다시 가져와서 설명을 더 해보겠습니다.
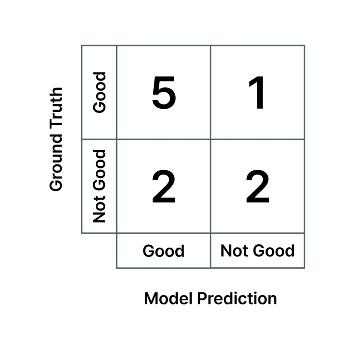
다음과 같은 혼동 행렬을 가지는 분류 AI의 경우, 각 클래스에 대한 FP (False Positive), FN (False Negative)는 다음과 같은 의미를 가집니다.
- 모델의 'Good' 클래스에 대한 False Positive = 실제 불량품인데 모델이 양품이라고 예측
- 모델의 'Good' 클래스에 대한 False Negative = 실제 양품인데 모델이 불량품이라고 예측
- 모델의 'Not Good' 클래스에 대한 False Positive = 실제 양품인데 모델이 불량품이라고 예측
- 모델의 'Not Good' 클래스에 대한 False Negative = 실제 불량품인데 모델이 양품이라고 예측
또 다른 예시로, 다음과 같은 혼동 행렬을 갖는 객체 검출 AI의 경우,
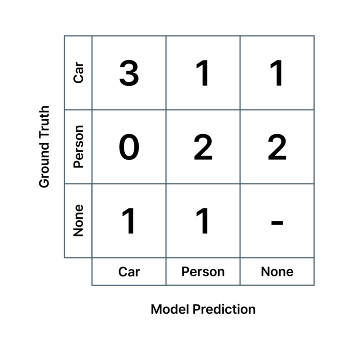
- 정답 데이터에는 아무런 사물이 라벨링 되어 있지 않은 위치에 (정답 데이터가 'None'), 모델이 어떤 객체를 탐지한 경우는 False Positive,
- 정답 데이터에 어떤 사물이 라벨링 되어 있는 위치에 (정답 데이터가 'None'이 아님), 모델이 아무런 객체를 탐지하지 못한 경우는 False Negative 입니다.
정답 데이터, 모델 예측 둘 다 있는 경우에도 두 값이 상이한 경우에 False Positive와 False Negative가 발생합니다.
- 정답 데이터가 'Car' 클래스인데 모델이 'Person' 클래스를 출력한 경우는,
- 모델의 'Car' 클래스에 대한 False Negative이자
- 모델의 'Person' 클래스에 대한 False Positive이며,
- 'Car'/'Person' 클래스 간의 분류 오류(Misclassification)라고도 할 수 있습니다.