슈퍼브 레시피 데이터 라벨링 인력, 유저 리포트 분석으로 '성과'를 만드는 관리 전략 🔍 대규모 라벨링 프로젝트에서는 수많은 작업자들의 업무 현황을 실시간으로 파악하고, 결과물의 품질을 일관되게 유지하는 것이 매우 중요합니다. 그런데 작업자의 라벨링 결과물과 진행 상황을 일일이 확인하며 관리한다면 얼마나 비효율적일까요? 챙겨야 할 것들이 많은 대규모 라벨링 프로젝트라면 관리자가 진행 상황을 파악하거나 오류를 사전에 방지하는 데 한계가 있고 비효율적일 것입니다. 또한 수작업으로 발생할 수
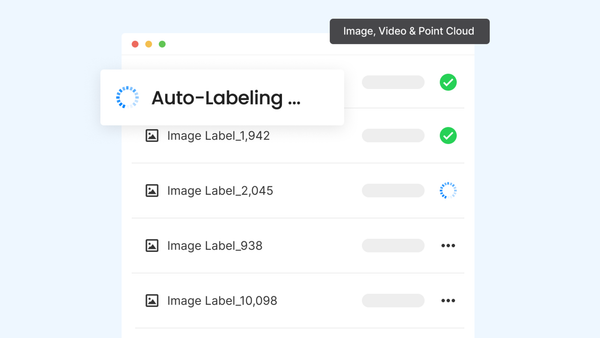
슈퍼브 레시피 오토라벨 X 비식별화 X 제로 모델: 대규모 데이터 자동 라벨링, 최적의 솔루션👩🏻🔧 대규모 데이터셋을 다룰 때 가장 먼저 부딪히는 과제는 바로 '라벨링'입니다. 수천 장 이상의 이미지나 영상 데이터를 수작업으로 라벨링하는 데에는 엄청난 시간과 비용이 들죠. 예를 들어, 자동차 부품 제조 기업에서 부품의 불량 여부를 학습시키기 위한 데이터 1만 장을 사람이 일일이 라벨링한다면 최소 몇 주에서 길게는 몇 달이 걸릴
슈퍼브 레시피 생산성 UP!💁 소규모 제조 기업을 위한 고성능 AI, 단기간에 구축하는 비법 제조 산업에서 제한된 예산과 인력만으로 고성능 AI 모델을 구축하는 것은 많은 기업이 직면한 현실적인 고민입니다. 특히 머신비전 솔루션을 대체하거나 공정 자동화를 추진하고자 하는 기업, 또는 자체적으로 AI 개발 역량을 내재화하려는 제조 기업이라면, AI 도입의 전 과정을 하나하나 구축하는 데 필요한 많은 인력과 시간이 부담스러울 수밖에 없죠. 이러한 상황에서 소규모 팀과
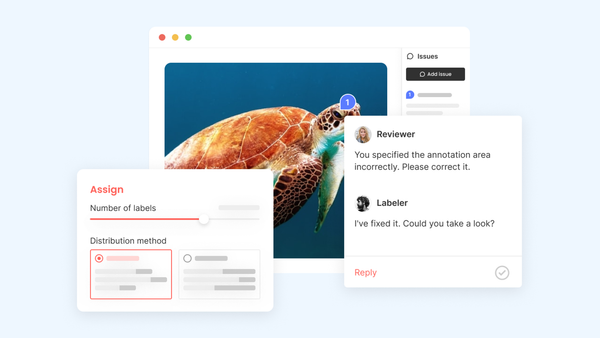
슈퍼브 레시피 라벨링 검수 완벽 정리: ✅ 효율적인 검수 프로세스로 데이터 품질 극대화하기 데이터 품질은 AI 모델의 성능을 결정하는 중요한 부분 중의 하나입니다. 아무리 적절한 데이터를 선별하고, 정교한 모델을 설계하더라도, 학습 데이터가 정확하지 않다면 기대한 성능을 얻기 어렵습니다. 데이터 구축 과정은 데이터를 수집하고 라벨링 하는 것에서 끝나지 않습니다. 오토라벨링을 적용하여 빠르고 자동화된 라벨링이 되었더라도 모든 객체가 정확하게 라벨링 되었는지 검토해야 하고, 여러 명의
슈퍼브 레시피 모델 학습을 위한 데이터셋 구축 💡Tip : 업로드부터 커스텀 오토라벨링까지 한 번에 끝내기 AI 모델 개발 과정에서 가장 큰 어려움은 어디서 시작해야 하고 어떤 순서로 진행해야 할지 결정하는 데 있습니다. 특히, 초기 단계인 데이터 구축 단계에서는 대량의 데이터를 효율적으로 관리하고 라벨링 하는 작업이 필수적이며, 이는 막대한 시간과 비용이 소요되는 과정입니다. 데이터 관리와 라벨링은 AI 모델 학습의 핵심 요소로, 이 과정의 효율성과 정확성은 최종
슈퍼브 레시피 수 십만 장의 데이터를 분석해 학습용 데이터를 선별해야 할 때: Auto-Curate "What to Label" 💡수십만 장의 데이터를 분석, 정제하여 학습용 데이터를 선별해야 하는 작업이 주어졌습니다.이 작업은 예상보다 많은 시간과 노력을 요구합니다. 특히 비정형 데이터 분석 시, 고려해야 할 요소가 너무 많습니다. 물론 메타 데이터로 접근해 볼 수 있습니다만, 아쉽게도 메타 데이터로만으로는 비정형 데이터의 다양성과 복잡성을 다 파악하기 어렵습니다.예를 들어, 촬영 시간에 대한