수 십만 장의 데이터를 분석해 학습용 데이터를 선별해야 할 때: Auto-Curate "What to Label"


그렇다고 해서 이 과정을 절대 소홀히 할 수 없습니다. 자칫 잘못된 데이터나 불필요한 데이터를 모델 학습에 사용하게 되면 결과적으로 모델 성능이 저하되고, 성능을 올리기 위해서는 결과적으로 다시 데이터 품질을 검토해야 하기 때문입니다. 학습에 도움이 되지 않는 데이터를 무작정 라벨링하면 시간과 돈 낭비 또한 발생하게 되죠.
데이터의 품질과 데이터 수량, 다양성, 그리고 모델의 궁극적인 목표를 통해 원본 데이터를 분석하여, 어떤 데이터가 의미가 있고 어떤 데이터가 불필요한지 먼저 따져본 후에, 분석 결과를 바탕으로 학습할 데이터셋를 선별하여 의미있는 데이터만 먼저 라벨링 하는 것이 가장 효율적인 방법일 것입니다.
슈퍼브 큐레이트에서 원본 데이터의 경향성을 먼저 파악한다면, 의미있는 데이터만 선별하여 가공할 수 있습니다. 불필요한 데이터를 골라 냄으로써 가공 과정에서 발생하는 인적, 물적 리소스 또한 절감할 수 있습니다. 다음은 리소스 절감을 위해 슈퍼브 플랫폼에서 실행할 수 있는 간단한 레시피 입니다.
💻레시피 케이스 1.
학습할 데이터를 최소 수량으로 시작하는 방법
(feat. 라벨링 비용을 50% 이상 줄이는 비법)
🧐이런 분께 추천해요
- 최소한의 리소스 투입으로 유의미한 데이터셋 라벨링과 모델 학습을 하고 싶은 분
- 라벨링 작업 시작 전, 원본 데이터의 편향성을 분석하고 싶은 분
🚩 목표 세우기
- 보유 데이터의 경향성을 파악하여, 편향성을 최소화한 학습 데이터셋로 라벨링하기
[추천] 75% 적은 데이터로도 비교군과 비슷한 성능 달성한 흥미로운 실험을 확인해 보세요.
👉큐레이트 워크플로우 자세히 보기
1. 데이터셋 생성하기
1) 슈퍼브 플랫폼 좌측 상단에 위치한 [Curate]를 클릭하여 슈퍼브 큐레이트 첫 화면을 확인하세요.
2. 데이터셋 업로드 하기
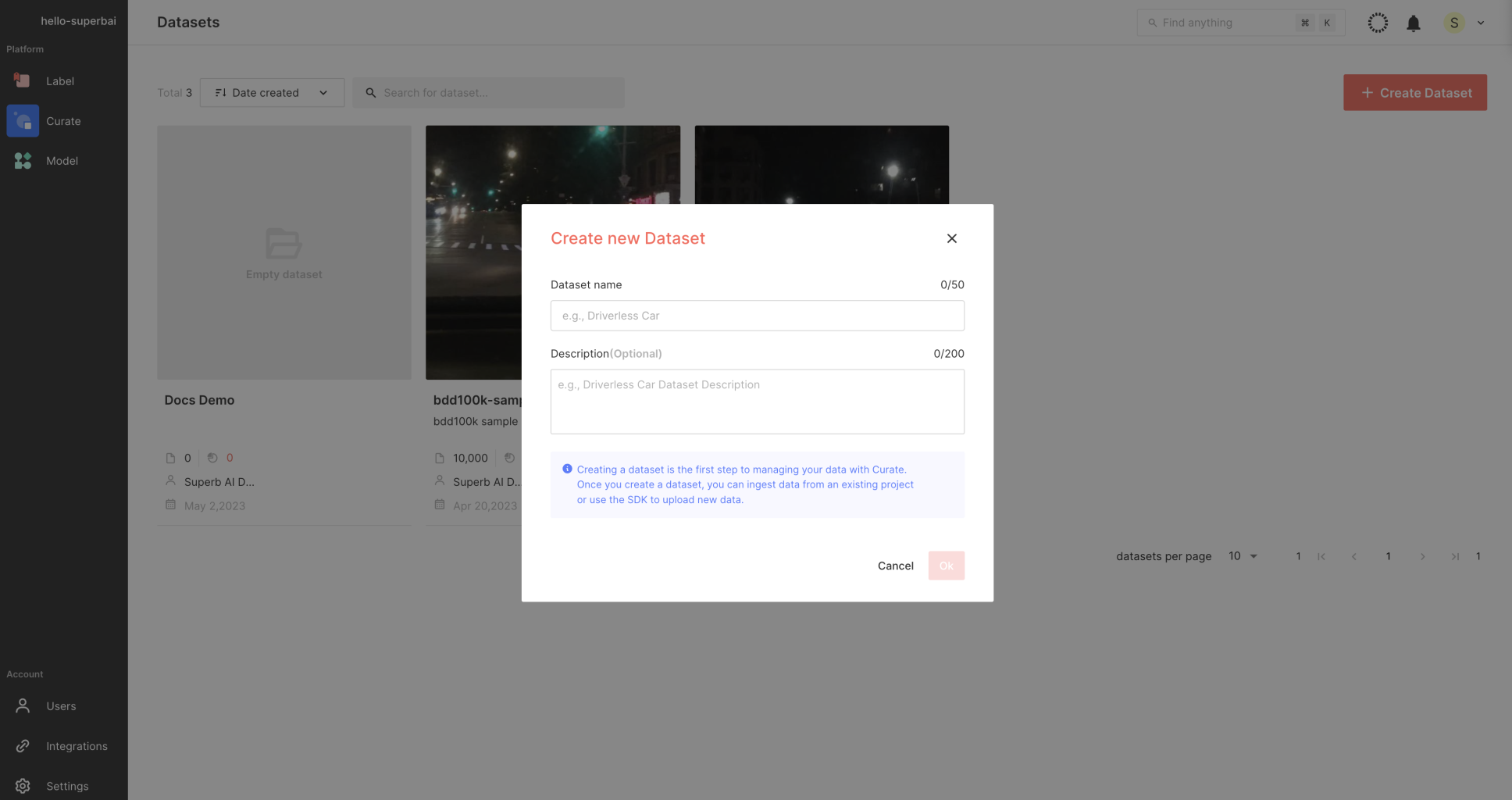
1) [Create Dataset]을 눌러 데이터셋을 생성하고 원본 데이터를 업로드 하세요.
(자세한 방법을 알고 싶다면?)
2) 슈퍼브 라벨을 통해 이미지 데이터 업로드하기
* 슈퍼브 라벨에 데이터가 업로드 되어 있지 않다면? (업로드 방법 확인하기)
3) SDK로 이미지 데이터 업로드 하기
(1) 슈퍼브 큐레이트 SDK를 이용하여, 많은 양의 이미지 데이터를 편리하게 업로드할 수 있습니다. SDK 설치 후 진행할 수 있습니다.
(2) SDK 사용하기 문서를 통해 순서에 따라 데이터를 업로드하세요.
[안내] SDK 업로드에 어려움이 있으신가요? 추가 도움이 필요하시다면 아래 문의를 남겨 주세요.
3. 스캐터뷰 기능으로 데이터 경향성 확인하기
1) 스캐터뷰의 '썸네일 뷰'로 시각적 유사도에 따른 이미지 분포 및 경향성을 한 눈에 확인합니다. 데이터가 분포되어 있는 형태에서 멀리 떨어져 있을 수록 Edge Case (희귀 케이스)이며, 군집의 밀도가 낮을 수록 유사한 이미지 수량이 적다는 것을 의미합니다.
예시로, 모양이 비슷한 ‘4’와 ‘7’ 이미지가 서로 가까운 위치에 있는 것이 보입니다. 상대적으로 밀도가 낮은 군집을 확인하면 Edge case (부족한 데이터 혹은 저품질의 데이터 등)의 경향과 종류도 확인할 수 있습니다.
스캐터뷰 만으로도 이렇게 많은 부분을 빠르게 파악할 수 있어 향후 어떤 데이터를 더 수집해야 할 지, 어떤 데이터를 학습에 포함해야 할지 등 필요한 다음 작업을 수행할 수 있습니다.
4. 라벨링할 데이터 자동 선별하기 (Auto-Curate & What to Label)
1) 화면 우측 중간에 위치한 [Auto-Curate]를 클릭합니다.
2) Auto-Curate의 [Curate What to Label]을 클릭합니다.
3) 오토 큐레이트(Auto-Curate)기능 원본 데이터의 시각적 특징의 희소성, 균형된 분포 등을 고려하려 라벨링할 데이터를 선별합니다. 이러한 기준은 선택한 데이터가 데이터셋를 대표하고 효과적인 학습 모델을 구축하는 데 사용할 수 있는 지 확인하는 데 도움이 됩니다.
4) Auto-Curate에서 라벨링을 원하는 데이터 수량을 조정할 수 있습니다. 최적의 학습용 데이터 수량은 라벨러 수, 프로젝트 기간, 데이터 및 어노테이션 종류 등 다양한 변수로 인해 프로젝트마다 상이합니다. 처음부터 수량을 조정하기 어려울 경우 아래 추천 수량을 통해 진행해 봅니다. 저희는 여기에서 데이터 수량의 25%인 17,500장으로 진행해 보았습니다.
5) Auto-Curate가 실행되면 라벨링할 데이터를 선별한 슬라이드(Slice)가 자동으로 생성됩니다. 라벨링할 데이터가 선별된 슬라이스의 이름을 지정하여 구분해 주세요.
(슬라이스(Slice)가 무엇인 지 생소하다면 ? 슬라이스에 대한 기본 개념 알아보기)
6) 모든 단계가 완료되면, [Curate] 버튼을 눌러 Auto-Curate를 시작하세요.
⏱ 17,500장 (총 70,000장의 데이터 중 25%) Auto-Curate의 경우, 약 10분 소요되었습니다.
5. 리포트 다운로드를 통해 선별한 데이터셋 파악하기
1) 선별한 데이터의 경향성을 정량적으로 파악할 수 있는 리포트도 확인해 봅니다. 무작위로 선별한 데이터셋 대비 얼마나 균형적으로 데이터가 선별 되었는지 확인할 수 있습니다. 물론 두 세트의 데이터는 동일한 수량입니다.
Auto-Curate된 데이터셋이 더 많은 유형의 데이터 군집을 포함한 것을 확인할 수 있습니다. 또한 전체 데이터셋에 많이 등장하는 유형 (Dense Cluster)와 비교적 적게 등장하는 유형(Sparse Cluster) 등도 확인할 수 있습니다. 라벨링 전 데이터 경향성을 미리 파악할 수 있습니다.
6. 슈퍼브 라벨로 선별한 데이터를 보내 라벨링 시작하기
⏱ 17,500장 (총 70,000장의 데이터 중 25%) Send to Label의 경우, 약 30분 소요되었습니다.
1) Auto-Curate의 “What to label”로 생성된 슬라이스를 선택합니다.
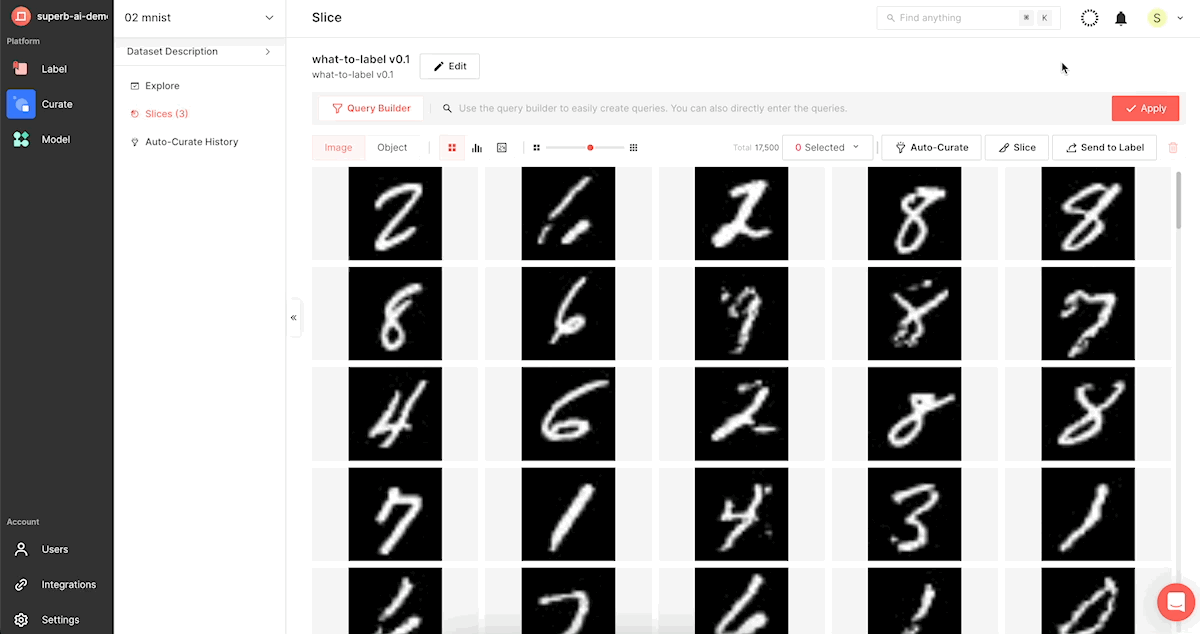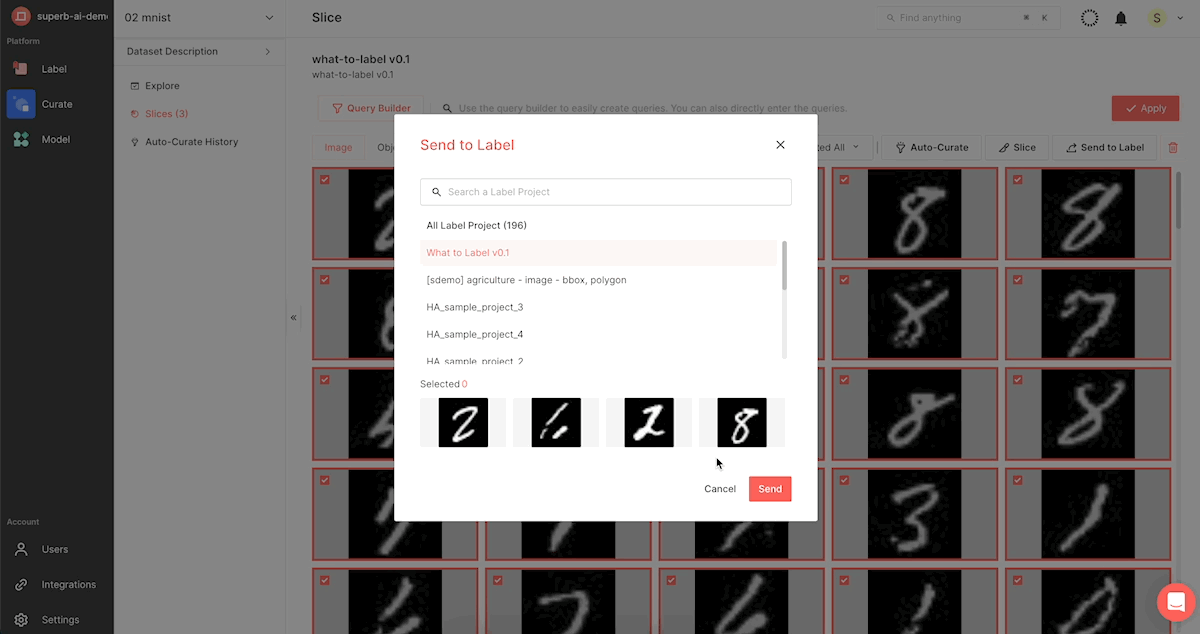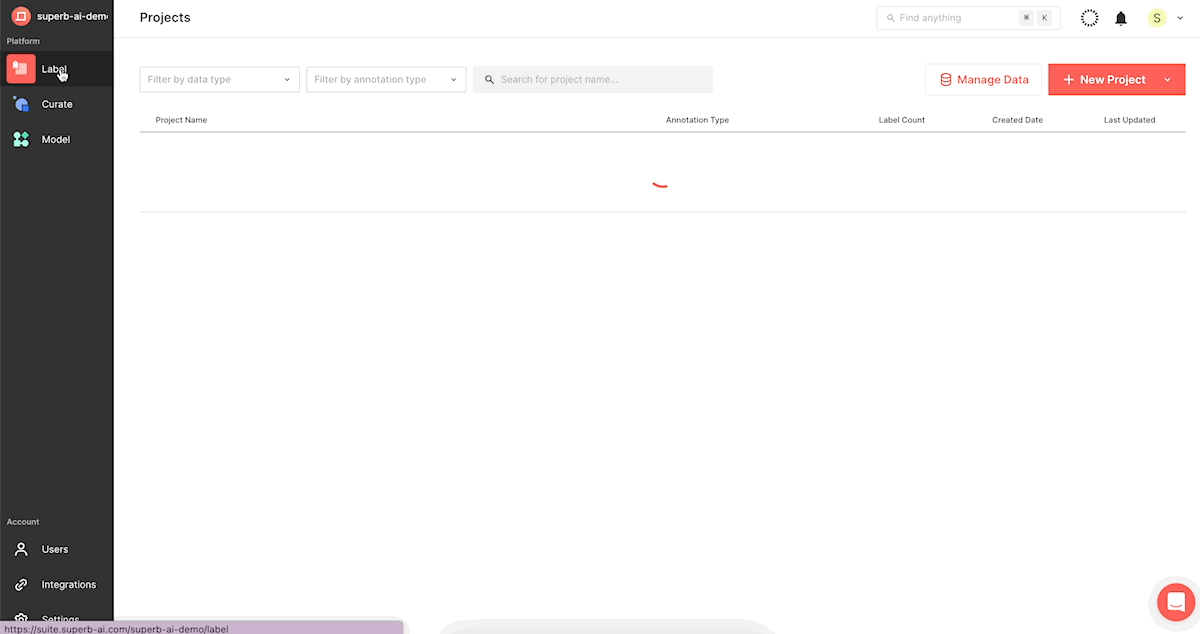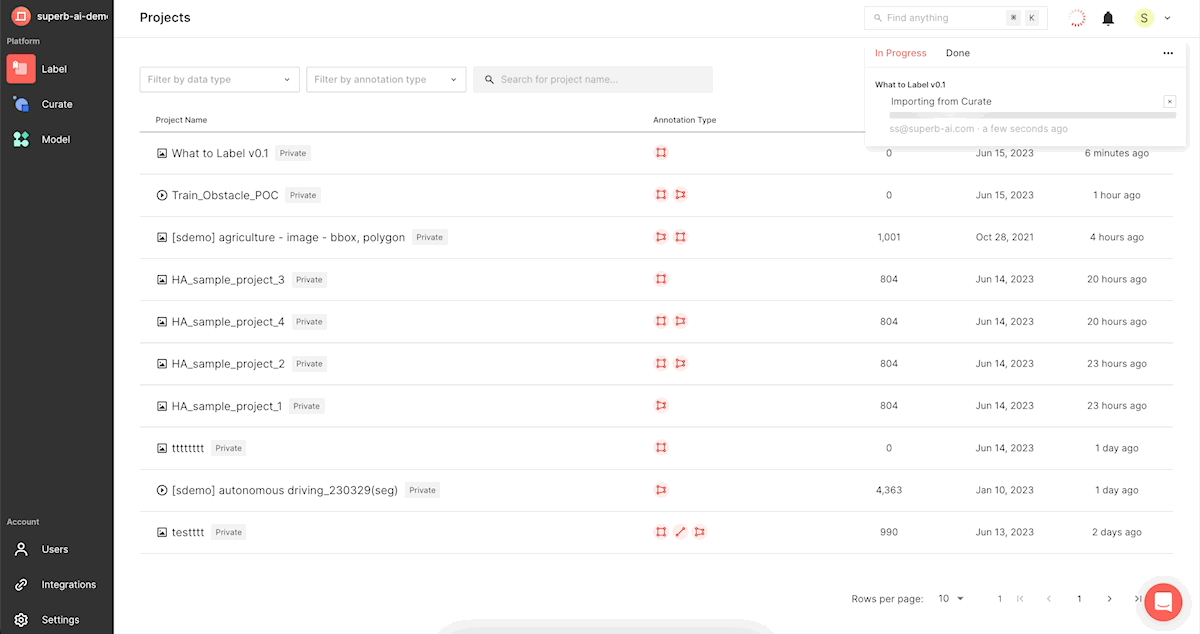
2) 슈퍼브 큐레이트 화면 상단에 위치한 [Send to Label] 을 클릭하세요.
3) 슈퍼브 큐레이트의 이미지 데이터를 보낼 슈퍼브 라벨 프로젝트를 선택하세요. 프로젝트 수가 많다면, 팝업창에서 프로젝트를 검색할 수 있습니다.
[참고] 만약 기존에 생성되어있던 슈퍼브 라벨의 프로젝트가 아닌, 새로운 프로젝트로 데이터를 보내길 원한다면, 먼저 슈퍼브 라벨에서 라벨링 진행할 프로젝트를 세팅하여(데이터 + 어노테이션 타입 등) 생성해야 합니다. 슈퍼브 큐레이트에서는 슈퍼브 라벨의 프로젝트 생성이 불가능합니다.
4) 좌측 상단에 위치한 [Label]을 클릭하여 슈퍼브 라벨로 이동합니다.
- 화면 우측 상단 진행 상황 바를 통해 데이터 업로드가 얼마나 진행되고 있는 지 실시간으로 확인할 수 있습니다.
* 슈퍼브 큐레이트에서 슈퍼브 라벨로 데이터를 보낼 때, 라벨 어노테이션 정보는 함께 보내지지 않습니다.
5) 슈퍼브 라벨에서 프로젝트 세팅을 진행합니다.
- 라벨에서 큐레이트로 데이터를 보냈을 경우, 기존 프로젝트가 아닌 신규 프로젝트로 진행하여 버전을 따로 관리해 보세요.