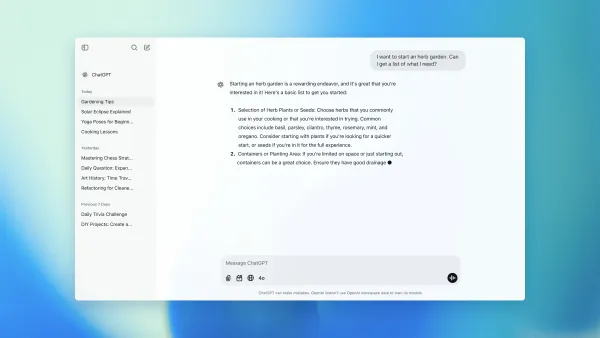
방대한 정보 홍수 속에서 신뢰할 수 있는 답변을 찾기 어렵다면? Perplexity AI가 해결책입니다. 실시간 웹 검색과 AI를 결합한 이 혁신적인 '앤서 엔진'은 ChatGPT와 달리 최신 정보에 기반한 정확한 답변과 출처를 제공합니다. 이 글에서는 Perplexity의 기본 사용법부터 학문, 수학, 글쓰기 등 특화된 검색 모드, Pro 버전의 고급 기능, 그리고 연구, 콘텐츠 제작, 데이터 분석에 활용하는 실용적인 방법까지 모두 알려드립니다.






![[현장] 영상에서 '맥락' 읽고 바이브 코딩으로 '데이터 시각화'... 진보하는 산업 AI](/content/images/size/w600/2025/05/250515_----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------...---------------------------------------------------AI_0.jpg)

![[스페셜리포트] 스마트비전 기술 트렌드 : AI와 함께 진화하는 제조의 눈](/content/images/size/w600/2025/05/250513_--------------------------------------------AI-------------------------------0.png)







![[TECH온앤오프] '혼잡을 넘어서다' AI가 바꾼 야구장의 풍경은?](/content/images/size/w600/2025/04/250428_-TECH----------------------------------AI----------------------------_.png)



