생성형 AI를 똑똑하게 해주는 검색증강생성(RAG)이란?


올해 초 삼성전자는 자사 데이터와 기술력을 활용해 자체 개발한 생성형 AI ‘Samsung Gauss’의 출시를 발표했다. 한 발 나아가 Samsung Gauss를 소형화 및 반도체화 한 임베디드 AI를 탑재하여 자동 동시통역 등의 서비스를 제공하는 세계 최초의 AI 스마트폰 갤럭시24를 출시하기도 했다.

생성형 AI의 활용이 늘어나면서 관련 기술에 대한 투자 및 연구 역시 활발해지고 있는 요즘, 이처럼 막대한 자본력과 방대한 양의 데이터를 확보한 거대 기업들은 LLM(초거대언어모델)을 자사 데이터를 활용해 지속적으로 미세조정(Fine-tuning)한 ‘맞춤형 LLM’을 개발하여 자체적인 AI 생태계를 구축해 가고 있다.
그러나 자본력과 데이터 확보에 한계를 가지고 있는 대다수의 기업들에게 있어서 오픈소스 LLM을 활용한 자체 LLM 개발은 요원한 일이다. 그렇다면 고가의 GPU와 방대한 양의 데이터 없이도 성능 좋고 보안 걱정 없는 맞춤형 LLM을 개발하고 업무 및 서비스에 활용할 수는 없을까? 그 답은 바로 검색증강생성(RAG)에 있다.
1. 검색증강생성(RAG, Retrieval Augmented Generation)이란?
RAG란 검색증강생성이라는 말에서도 알 수 있듯이, LLM이 참조할 수 있는 별도 정보원을 제공하여 환각 현상(Hallucination)을 방지하고 LLM의 답변 품질을 개선하기 위한 기법이다.
RAG를 적용함으로써 기업들은 LLaMA2와 같이 오픈소스로 제공되는 LLM에 자체 데이터를 미세조정하는 과정을 거치지 않고서도 성능 좋은 LLM의 보안 및 성능을 크게 개선하여 사용할 수 있다. 예를 들어 RAG 기법을 적용한 GPT-3.5-Turbo 모델은 그것을 적용하지 않은 동일한 모델에 비해 특정 분야에 관해 자세하고 전문성 있는 답변을 제시할 수 있다.
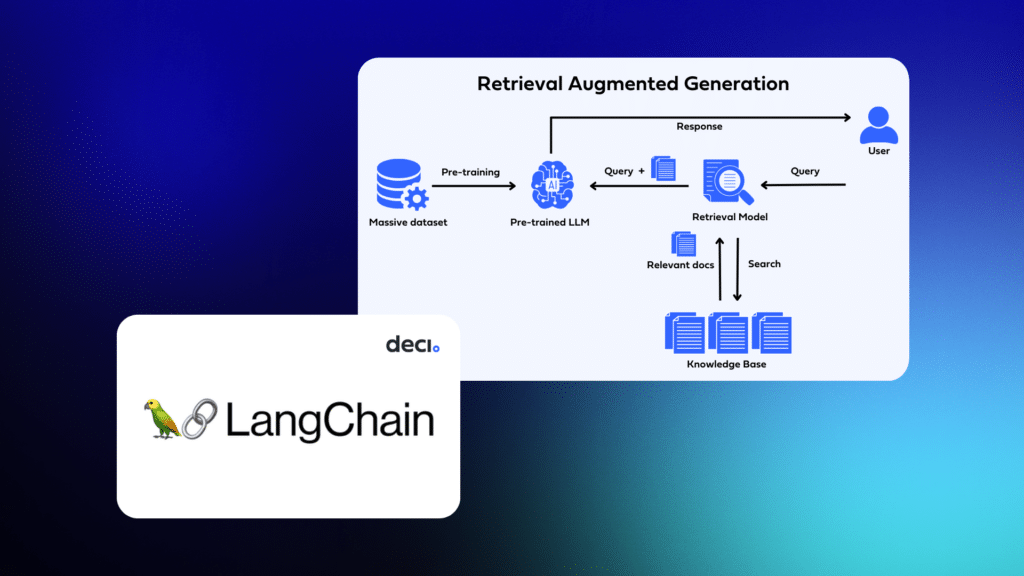
이때 LLM에 벡터 DB를 연동하고 프롬프트 엔지니어링을 적용하는 과정을 통해 LLM에서 생성된 텍스트의 품질을 향상시키고 특정 주제에 대한 더욱 정확하고 자세한 정보를 제공할 수 있게 해주는데, 생성형 언어 모델을 별도로 미세조정하는 과정은 많은 학습(Training) 및 추론(Inference)에 많은 시간과 계산 리소스를 필요로 하는데, RAG는 상대적으로 적은 노력과 시간만으로도 타 모델 대비 동일하거나 더욱 뛰어난 성능을 자랑하는 시스템을 구축할 수 있다는 장점이 있다.
2. 벡터 DB(Vector DB)
벡터 DB란 RAG 시스템에서 LLM이 정보를 효율적으로 저장하고 참조할 수 있는 데이터베이스다. 이 벡터 DB에는 사전에 LLM에게 제공하고자 하는 문맥(Context)를 저장할 수 있는데, 이를 위해서는 자연어와 같은 비정형 데이터(Unstructured Data)로 된 문서를 -1과 1사이의 실수로 바꾸어주는 임베딩(Embedding)이라는 과정이 필요하다.

이때 자연어로 구성된 단어와 문장을 0과 1의 이진수가 아닌 -1과 1 사이의 실수로 변환하는 이유는 입력값(검색어)와의 유사도를 계산하여 가장 관련도가 높은 문장을 답변으로 제시할 수 있게 설계하기 위함이다. 이러한 과정을 거쳐 구축된 벡터 DB는 활용하여 생성된 텍스트를 보완하거나 확장하는 데 사용된다.
3. 프롬프트 엔지니어링(Prompt Engineering)
다른 여러 LLM 활용 기법들과 마찬가지로 프롬프트 엔지니어링은 RAG를 구성하는 매우 중요한 요소중 하나이다. 프롬프트 엔지니어링은 LLM이 생성하게 될 텍스트에 대한 프롬프트를 설계하고 조정하는 프로세스인데, 프롬프트 엔지니어링을 통해 RAG 설계자는 LLM에게 역할을 지정하고, 사전에 제공한 벡터 DB의 문맥에 맞게 사용자가 원하는 답변을 생성해 내도록 유도할 수 있다.
4. LLM과의 연동
앞에서 살펴보았듯이 기본적으로 RAG는 LLM과의 연동을 전제로 한다. 이때 GPT와 같은 기존의 성능 좋은 모델을 연동하거나, 자사 도메인에 특화된 LLM을 자체적으로 제작하여 연동할 수 있다. 또한 비교적 매개변수(parameter)가 적은 소형 LLM(sLLM, small LLM)을 추가적으로 연동하는 등 다양한 아키텍처를 고려해 볼 수도 있다.
대안으로서 RAG의 활용 가치
요약하자면, LLM에 RAG는 외부 정보를 담고 있는 벡터 DB를 활용하여 생성된 텍스트를 개선하고 보완하기 위한 기술이며, 이 과정에는 벡터 DB와 프롬프트 엔지니어링이라는 기법이 적용된다. 이러한 일련이 과정을 통해 고가의 GPU나 방대한 양의 데이터 없이도 맞춤형 언어 모델을 개발하고 활용할 수 있게 되는 것이다.
검색 및 생성 모델의 결합 강점을 활용한 RAG는 전통적인 접근법의 제약을 극복하고 더 많은 대화형 에이전트와 챗봇에서 정보 검색 시스템 및 콘텐츠 생성 도구까지 RAG는 다양한 산업 및 사용 사례 범위에서 응용되고 있다. 기존 인프라와 원활하게 통합되고 다양한 도메인에 적용이 가능하므로 LLM 사용 활성화를 위한 좋은 대안이 될 수 있을 것이다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.