[VFM 개념] 비전 AI의 기술적 도전과 미래 방향
2025년 비전 AI의 핵심 화두: 동적 아키텍처, 3D 공간 이해, 월드 모델. VFM의 최신 기술 동향과 산업별 적용 전략을 상세 분석했습니다.

2024년, OpenAI의 GPT-4V가 시각적 추론 능력을 선보이며 충격을 안겼습니다. 구글의 제미나이(Gemini)는 비디오를 이해하고 분석하는 능력을 과시했죠. 하지만 정작 산업 현장에서는 여전히 "고양이와 개를 구분하는" 수준의 AI가 대부분입니다. 왜 이런 격차가 발생했을까요?
답은 간단합니다. 지금까지의 비전 AI는 '작업별 전문가'를 양성하는 데 집중했기 때문입니다. 이미지 분류 전문가, 객체 탐지 전문가, 세그멘테이션 전문가... 마치 의료 분야에서 각 신체 부위별로 전문의가 있는 것처럼, AI도 극도로 세분화되어 발전해왔습니다.
하지만 현실은 그렇게 단순하지 않습니다. 제조 현장의 품질 검사 AI는 단순히 불량품을 찾는 것에 그치지 않고, 불량의 유형을 분류하고, 발생 위치를 정확히 표시하며, 심각도를 평가하고, 원인을 추론해야 합니다. 이 모든 작업을 위해 각각 다른 AI 모델을 운영한다면? 비용과 복잡성은 기하급수적으로 증가합니다.
최근 메타의 SAM 2(Segment Anything Model 2)가 비디오 전체에서 객체를 추적하는 능력을 선보이고, 마이크로소프트의 플로렌스-2(Florence-2)가 비전 작업과 비전 언어 작업을 통합 처리할 수 있는 성과를 달성한 것은 우연이 아닙니다. 시장은 이미 "하나의 모델이 모든 것을 처리하는" 통합 비전 AI 시대로 빠르게 전환하고 있습니다.
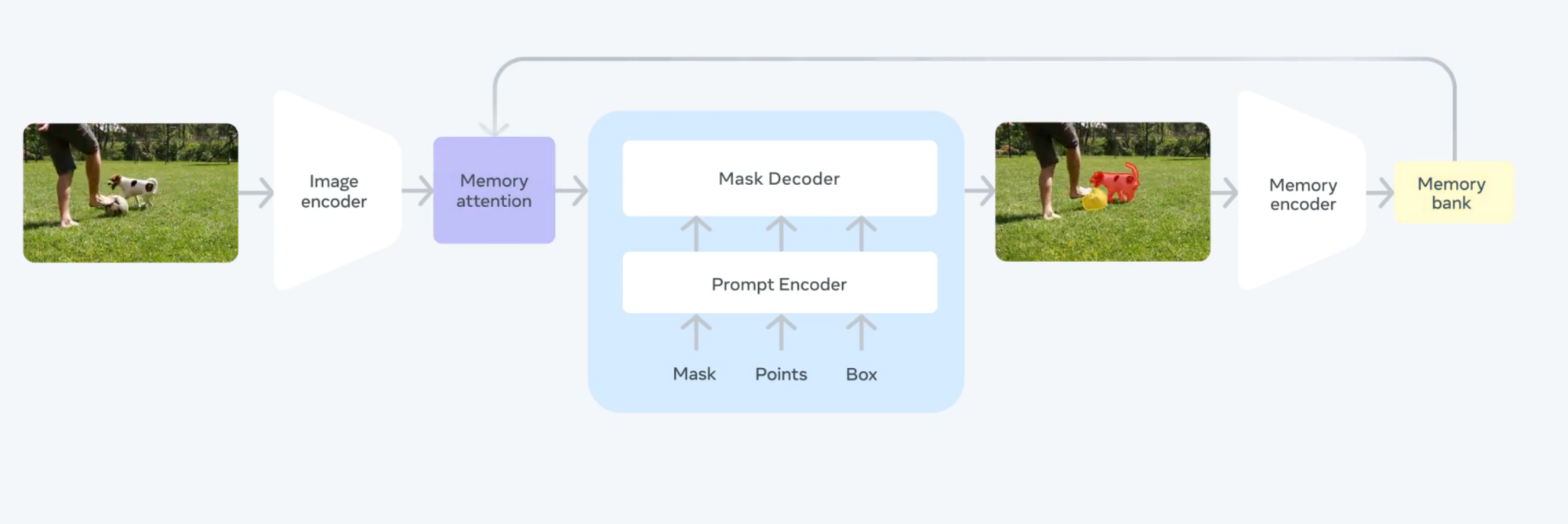
메타의 SAM 2
이러한 변화의 중심에는 비전 파운데이션 모델(Vision Foundation Model, VFM)이 있습니다. VFM은 단순히 여러 기능을 하나로 묶은 것이 아닙니다. 시각적 정보를 이해하는 방식 자체를 근본적으로 재정의하고, 다양한 작업 간의 시너지를 극대화하는 새로운 패러다임입니다.
지금까지 VFM 개념 1, 2, 3편을 통해 비전 파운데이션의 기초 개념에 대해 설명해 드렸는데요.


그렇다면 VFM은 어떤 기술적 도전을 극복하며 진화하고 있을까요? 대규모 비전 모델의 효율성 문제, 극도로 다양한 시각 데이터의 통합 학습, 그리고 언어와 비전의 최적 융합점 찾기 등 해결해야 할 과제가 산적해 있습니다.
이번 편에서는 이러한 도전 과제들과 함께, 최신 통합 모델들의 혁신적인 해결 방안을 상세히 살펴보겠습니다.
작업별 모델에서 통합 모델로: 비전 AI의 패러다임 전환
과거의 컴퓨터 비전은 각 작업마다 별도의 모델이 필요했습니다. 이미지 분류를 위한 ResNet, 객체 탐지를 위한 YOLO, 세그멘테이션을 위한 Mask R-CNN... 마치 요리마다 다른 조리기구를 사용해야 하는 것처럼 비효율적이었죠.
하지만 최신 비전 파운데이션 모델들은 하나의 통합 모델로 다양한 작업을 동시에 수행합니다. 이는 단순히 여러 모델을 하나로 합치는 것이 아니라, 시각적 이해의 근본적인 접근 방식을 재정의하는 것입니다.
통합 접근법의 두 가지 핵심 전략
I/O 통합 접근법은 입력과 출력을 표준화하여 다양한 작업을 하나의 프레임워크로 처리합니다. 모든 비전 작업을 "이미지 입력 → 구조화된 출력"이라는 공통 패턴으로 변환하는 것이죠. 이를 통해 분류, 탐지, 세그멘테이션 등 서로 다른 작업들이 동일한 아키텍처 내에서 처리될 수 있습니다.
기능 통합 접근법은 모델 내부에서 다양한 작업에 필요한 기능들을 모듈화하고 공유합니다. 마치 스위스 군용 칼처럼, 필요에 따라 적절한 기능을 선택적으로 활성화합니다. 이러한 접근법은 각 작업이 서로의 학습 결과를 활용할 수 있게 하여, 전체적인 성능 향상을 이끌어냅니다.
SAM 2의 입력 방식
현재 직면한 기술적 도전 과제
1. 대규모 비전 모델의 스케일링 법칙과 효율성 문제
언어 모델의 경우 파라미터 수가 증가하면 성능이 예측 가능하게 향상되는 스케일링 법칙이 잘 확립되어 있습니다. 하지만 비전 모델은 이야기가 다릅니다.
비전 데이터의 고차원성과 공간적 복잡성 때문에, 단순히 모델 크기를 키운다고 성능이 선형적으로 향상되지 않습니다. 특정 임계점(보통 10억 파라미터 근처)을 넘어서면 성능 향상 대비 계산 비용이 급격히 증가하는 현상이 관찰됩니다. 이는 효율적인 아키텍처 설계와 학습 방법의 혁신이 필요함을 시사합니다.
2. 비전 데이터의 이질성과 다양성 관리 방법
텍스트와 달리 이미지 데이터는 극도로 이질적입니다. 의료 영상의 미세한 조직 패턴, 위성 사진의 거시적 지형 정보, 제조 현장의 결함 이미지, 일상 사진의 복잡한 장면 구성 등은 각각 완전히 다른 특성을 가집니다.
이러한 다양성을 하나의 모델로 효과적으로 학습하는 것은 여전히 큰 도전입니다. 도메인별 특화된 지식을 유지하면서도 일반화 능력을 잃지 않는 균형점을 찾는 것이 핵심입니다. 최근 연구들은 도메인 적응형 정규화(Domain-Adaptive Normalization)나 멀티 헤드 어텐션의 선택적 활성화 등의 기법으로 이 문제를 해결하려 시도하고 있습니다.
3. 비전-언어 통합 접근법의 장단점 비교
비전-언어 모델(VLM)의 성공은 언어 정보를 활용한 풍부한 의미 이해를 가능하게 했습니다. 하지만 동시에 새로운 도전도 제기됩니다.
언어 중심 접근법의 장점은 직관적인 프롬프팅, 제로샷 학습 능력, 풍부한 의미 정보 활용입니다. 하지만 단점으로는 언어로 표현하기 어려운 미묘한 시각적 특징(텍스처, 광택, 미세한 형태 차이 등)을 놓칠 수 있다는 점이 있습니다.
비전 중심 접근법의 장점은 순수한 시각적 특징에 집중하여 더 정밀한 인식이 가능하다는 것입니다. 하지만 단점으로는 새로운 개념에 대한 적응이 어렵고, 사용자와의 상호작용이 제한적이라는 점이 있습니다.
최적의 해결책은 두 접근법의 장점을 결합하는 것입니다. 최근 연구들은 작업과 도메인에 따라 언어와 비전 정보의 비중을 동적으로 조절하는 적응형 융합(Adaptive Fusion) 메커니즘을 개발하고 있습니다.
앞으로의 유망한 연구 방향
비전 중심 모델링의 부활 (Vision-Centric Modeling)
'부활'을 넘어 '융합의 최적화' 단계로: 2024년에는 순수 트랜스포머(ViT)의 한계를 보완하기 위해 CNN의 귀납 편향(Inductive Bias)을 '재도입'하는 하이브리드 아키텍처가 주목받았다면, 2025년에는 이를 넘어 '어떻게 가장 효율적으로 융합할 것인가'에 대한 연구가 주를 이룹니다.
동적 아키텍처(Dynamic Architectures): 이제는 고정된 하이브리드 구조를 넘어, 입력 이미지의 복잡도나 특성에 따라 컨볼루션 레이어와 트랜스포머 블록의 사용 비중을 동적으로 조절하는 아키텍처가 활발히 연구되고 있습니다. 이는 계산 효율성을 극대화하며, 간단한 이미지에는 가볍게, 복잡한 이미지에는 깊게 연산을 수행합니다.
3D 및 공간 정보 내재화: 비전 중심 모델링은 이제 2D를 넘어 진정한 3D 공간 이해로 확장되고 있습니다. NeRF(Neural Radiance Fields), 3D 가우시안 스플래팅(3D Gaussian Splatting) 같은 기술과 VFM이 결합하여, 여러 장의 2D 이미지로부터 3차원 장면을 복원하고 그 안에서 객체의 공간적 관계를 추론하는 능력이 비약적으로 발전했습니다. 이는 로보틱스, 자율주행, AR/VR 분야에서 필수적인 기술입니다.
효율적인 멀티태스크 최적화 (Efficient Multitask Optimization)
어댑터(Adapters) 기술의 보편화: '작업별 어댑터'는 이제 연구 단계를 넘어 VFM을 특정 도메인이나 작업에 맞게 미세 조정(Fine-tuning)하는 표준적인 방법론으로 자리 잡았습니다. 특히 LoRA(Low-Rank Adaptation)와 그 변형 기술들은 거대한 VFM의 핵심 파라미터는 그대로 둔 채, 아주 작은 수의 파라미터만 추가하여 학습시키므로 매우 효율적입니다.
조건부 계산(Conditional Computation)의 확장: MoE(Mixture-of-Experts) 아키텍처를 비전 모델에 적용하는 것이 보편화되었습니다. 이는 모델의 특정 부분(전문가)만 선택적으로 활성화하여, 모델의 전체 크기는 키우면서도 추론 시의 계산 비용은 낮게 유지하는 혁신을 가져왔습니다. Google의 Gemini 모델이 대표적인 예시입니다.
모델 컴포지션(Model Composition)의 부상: 2025년의 새로운 화두는 '모델의 동적 조합'입니다. 이는 사전 학습된 여러 '스킬(skill)' 모듈(예: 색상 판별 모듈, 질감 분석 모듈, 자세 추정 모듈)을 가지고 있다가, 사용자의 복잡한 프롬프트("녹슬고 표면이 거친 파이프를 찾아줘")를 받으면 필요한 스킬 모듈들을 동적으로 조합하여 문제를 해결하는 방식입니다. 이는 진정한 의미의 '범용성'으로 가는 중요한 단계입니다.
자기지도 학습의 진화 (Self-Supervised Learning)
비디오를 넘어 '월드 모델(World Models)'로: 시간적 일관성 학습은 이제 단순히 비디오 프레임 간의 관계를 배우는 것을 넘어, 세상의 물리 법칙과 인과 관계를 학습하는 '월드 모델'로 진화하고 있습니다. OpenAI의 Sora나 Google의 Genie와 같은 모델들은 주어진 이미지나 텍스트 프롬프트로부터 앞으로 일어날 일을 비디오로 생성(예측)합니다. 이는 VFM이 단순한 '인식'을 넘어 '시뮬레이션'과 '예측'의 영역으로 진입했음을 의미합니다.
다중 모달리티(Multi-modality)의 폭발적 확장: 크로스 모달 예측은 이제 텍스트-이미지를 훨씬 뛰어넘습니다. 비디오 + 오디오 + 텍스트 + 깊이 정보 + 로봇의 행동 데이터 등 세상에 존재하는 거의 모든 종류의 데이터를 함께 학습하여, 하나의 개념을 여러 감각으로 동시에 이해하는 방향으로 나아가고 있습니다. 예를 들어, '파도'라는 개념을 시각적 형태, 부서지는 소리, '파도'라는 텍스트, 그리고 파도가 미는 힘(물리적 데이터)과 연결하여 학습합니다.
인간과의 상호작용을 통한 학습 (Human-in-the-loop): 자기지도 학습에 더해, 모델이 애매하거나 확신이 없는 부분을 인간에게 질문하고 피드백을 받아 스스로 개선하는 '능동적 학습(Active Learning)'과 '인간 피드백 기반 강화학습(RLHF)'이 비전 분야에도 본격적으로 도입되고 있습니다. 이는 모델을 더욱 안전하고 사용자의 의도에 맞게 정렬(align)시키는 데 핵심적인 역할을 합니다.
맺으며: 비전 AI의 새로운 지평
비전 파운데이션 모델은 "모든 것을 보고 이해하는 AI"라는 궁극적 목표를 향해 빠르게 진화하고 있습니다. 작업별로 분리되었던 모델들이 하나로 통합되고, 언어와 비전의 경계가 허물어지며, 현실 세계의 복잡성을 다룰 수 있는 진정한 범용 AI로 발전하고 있습니다.
기술적 도전은 여전히 존재합니다. 스케일링의 효율성, 데이터의 이질성, 비전-언어 통합의 균형 등은 앞으로도 지속적인 연구가 필요한 영역입니다. 하지만 통합 모델 아키텍처의 발전, 새로운 학습 방법론의 등장, 그리고 산업 현장에서의 실증을 통해 이러한 도전들은 하나씩 극복되고 있습니다.
슈퍼브에이아이 제로는 이러한 최신 기술을 산업 현장에 적용하여 실질적인 가치를 창출하고 있습니다. 제조, 물류, 안전 관제 등 다양한 분야에서 이미 그 효과를 입증했으며, 앞으로도 지속적인 기술 혁신을 통해 더 안전하고 효율적인 산업 환경을 만들어갈 것입니다.
비전 AI의 미래는 단순히 "보는" 것을 넘어 "이해하고 행동하는" AI로 진화하고 있습니다. 그리고 그 미래는 이미 우리 곁에 와 있습니다.

슈퍼브에이아이 비전 파운데이션 모델 제로에 대한 더 자세한 정보와 도입 문의를 원하시면 아래 내용을 채워주세요. 슈퍼브 전문가들이 바로 연락 드리겠습니다.