AI가 창조할 수 있는 비밀: 생성형 AI 이해하기


생성형 AI가 주목을 받으면서 '생성형 AI가 거품이다 아니다' 논쟁도 있지만 개인적으로는 OpenAI의 성공과 ChatGPT를 사용하는 개인과 기업들, 그리고 의료 국방 제조 등 여러 분야에서 AI를 이용한 시도, 혁신이 이뤄지고 있는 모습들을 보면 단순히 거품에 거치지 않을 것이라는 생각이다.
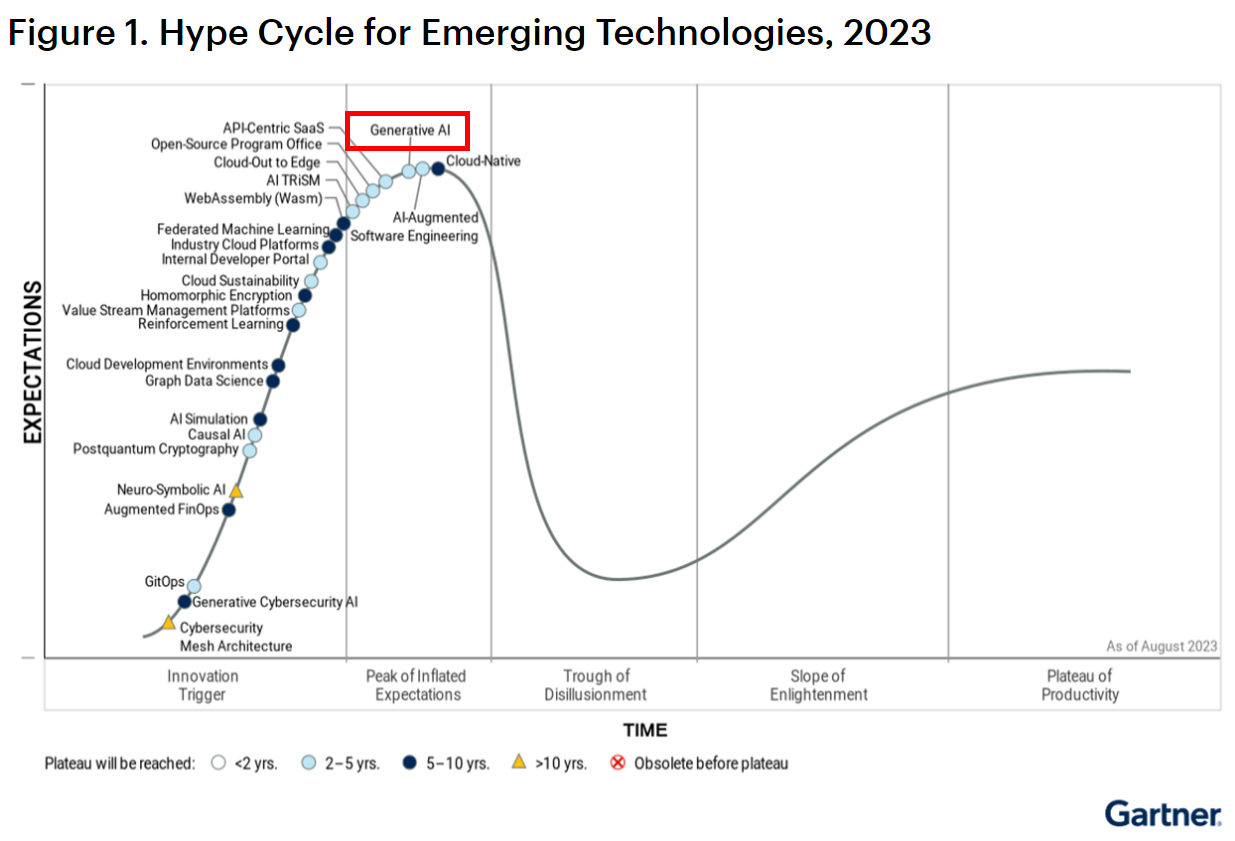
가트너의 2023년 Hype Cycle에 따르면 현재 생성형 AI는 기대감 최고 단계 (Inflated Expectations) 단계에 있으며 향후 2~5년 동안 혁신을 주도하며 대중화될 것으로 기대되고 있다.
그렇다면 이렇게 주목받고 있는 생성형 AI(Generative AI)는 무엇일까? 생성형 AI가 앞으로 가져올 변화와 활용법 등을 짐작하기 위해서는 먼저 생성형 AI의 개념을 이해하는 것이 필요할 것이다. 이번 글에서는 생성형 AI의 기본개념과 High-Level에서의 작동방식, 그리고 위험요인, 응용 분야 등에 대해 이야기하고자 한다.
생성형 AI란 무엇인가?
생성형 AI의 가장 큰 특징은 수많은 데이터셋을 학습해 그를 바탕으로 새로운 데이터를 생성한다는 점이다. 이전 머신러닝 모델이나 딥러닝 모델은 데이터를 학습해 개 또는 고양이 같은 범주형 데이터를 분류하거나(Classification), 집값이나 주가와 같은 수치형 데이터를 예측(Regression)하는 데 주로 사용되었다.
ChatGPT가 기반하는 GPT-3 언어모델은 인터넷, 신문기사, 책 등에서 수집된 약 3000억 개의 토큰으로 텍스트 데이터의 패턴과 관계 등을 학습해 여기에 단어나 문장을 입력하면 이어지는 자연스러운 문장을 생성한다. ChatGPT는 GPT-3에 인간의 질문 의도에 맞게 보다 자연스러운 대화를 할 수 있도록 질문-답변 데이터셋을 추가로 학습시킨(파인튜닝) 모델이다.
생성형 AI 기술은 ChatGPT와 같은 텍스트 생성 모델 뿐만 아니라 이미지, 비디오 등 다양한 미디어를 생성할 수 있는 모델들의 등장으로 이어지고 있다. 가령, DALLE2와 같은 텍스트 투 이미지(Text to Image) 모델은 텍스트를 조건으로 수많은 이미지 데이터셋을 복원하는 과정에서 텍스트와 이미지 데이터의 관계 등을 학습해 텍스트를 넣으면 이미지를 생성할 수 있는 이미지 생성 모델이다.
어떻게 작동하는 걸까?
그렇다면 생성형 AI가 어떻게 작동하는 지 조금 더 자세히 알아보도록 하자.
생성형 AI 모델은 기본적으로 딥러닝 모델을 기반으로 하며 그 안에는 수많은 파라미터를 가진 방정식과 함수들이 존재한다. 데이터셋을 학습하며 이 방정식들의 최적화된 파라미터, 즉 가중치를 찾기 위해 학습하며 엄청난 연산이 이뤄진다. 사실 텍스트 데이터네, 이미지 데이터네 이야기 해도 그 안에는 모든 데이터가 숫자로 변경되어 학습되고 숫자로 내놓은 결과를 다시 텍스트 혹은 이미지 등으로 복원하는 과정이 포함된다.
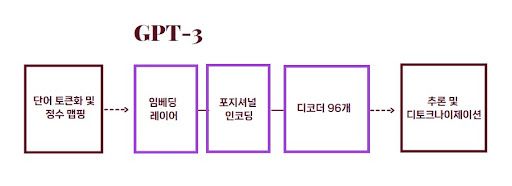
ChatGPT가 기반하는 GPT-3를 대표적으로 뜯어보자. GTP-3 175B는 각 토큰을 임베딩 표현으로 바꿔주는 임베딩 층, 임베딩 표현에 위치 정보를 더하기 위한 포지셔널 인코딩, 그리고 96개의 디코더 블록, 모델의 마지막 출력을 어휘 크기에 맞게 변환해 각 토큰에 대한 확률을 생성하는 Linear & Softmax 레이어로 구성되는데 이들을 통틀어 1750억 개의 파라미터를 학습해야 한다.
텍스트는 토큰화되고 정수로 변경되어 GPT-3의 임베딩에 입력된다. 임베딩 층과 포지셔널 층을 통과한 임베딩 표현은 디코더 층들을 거치면서 점차 그 특징이 학습되는데 각 디코더 층은 서로 다른 가중치를 가지고 있다. 이렇게 디코더 층을 통과한 값은 마지막에 Linear와 Softmax 층을 통과하면서 다음에 올 단어(토큰)에 대한 확률을 생성하는데 이렇게 해서 정답 문장이 나올 확률을 극대화하는 방향으로 가중치를 업데이트하면 학습을 계속한다.
학습이 완료된 모델에 역시 토큰화된 텍스트 데이터를 넣으면 다음에 올 문장이 생성되는 데 이 때 당장 눈앞에 확률이 가장 높게 나오는 토큰들만 순차적으로 선택해 문장을 생성할 수도 있고, 다음에 올 토큰들의 확률 분포에서 랜덤하게 샘플링해 가며 문장을 생성할 수도 있다. 여기서 말하는 토큰은 정확히는 각 토큰에 해당하는 정수들을 의미하는데 이 정수들을 다시 디코딩하면 문장을 생성하는 것처럼 보인다.
이렇게 이전 단어들을 바탕으로 다음에 어떤 단어가 등장할 확률이 높고 그래서 어떤 문장의 등장 확률이 높다는 것을 가르쳤을 뿐인데 마치 알고 있는 지식인 것처럼 유창하게 말할 수 있다니 신기하지 않은가? GPT-3는 그저 확률적으로 높은 문장을 생성했을 뿐인데 말이다.
주의해야 할 위험요인은?
GPT-3의 학습과정에서 본 것처럼 모델은 학습 데이터에서 배운 내용에 기반함으로 학습 데이터에 있는 편견을 반영할 수 있다. 방대한 데이터셋에서 언어의 패턴과 관계를 학습하는 한편, 특정 데이터셋의 비중이 높거나 폭력이나 인종차별 등의 내용이 포함되어 있다면 이를 생성할 수도 있다.
또한, 방대한 텍스트 데이터를 학습해 블로그도 유창하게 생성하고 이메일도 잘쓰고 코드도 곧잘 생성하지만 이는 확률적으로 높은 문자들을 생성했을 뿐 사실이 아닌 내용이나 모르는 내용도 유창하게 생성할 수 있다는 점을 고려해야 한다.
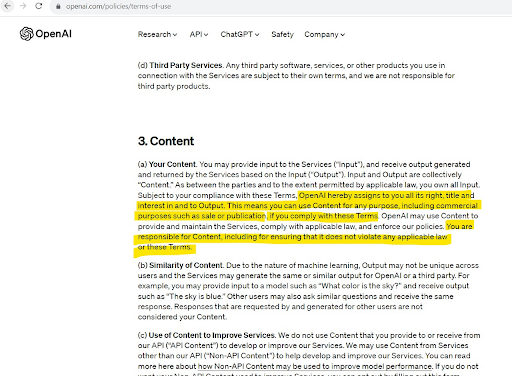
마지막으로 지적재산권 문제인데 ChatGPT나 DALLE2, 미드저니와 같은 생성형 AI 모델들은 사용자가 생성한 결과물에 대해 상업적 이용권리를 부여하고 있다. 하지만 동시에 약관이나 관련 법 준수 등 콘텐츠에 대한 책임 역시 사용자에게 있는 구조여서 애초에 정당한 이용권한이 없는 이미지를 업로드 하거나 모델이 생성한 결과물을 그대로 사용하는 것 등은 주의가 필요하다고 할 수 있다.
다양한 응용분야
ChatGPT가 등장한 이후로 ChatGPT를 추가 데이터셋으로 파인튜닝하거나 API로 데이터를 연동해 다양하게 활용하는 사례가 늘고 있다. 물론 새로운 모델을 만드는 경우도 있지만 이는 구글이나 메타, 몇몇 국내 대기업들에 한정된 이야기고 대부분 거대언어모델(LLM)을 파인튜닝하거나 API로 서비스를 구현하는 경우라 할 수 있다.
광고
광고 분야에서는 옴니콤이나 WPP와 같은 글로벌 에이전시들이 마이크로소프트나 엔비디아 등과 협업하여 클라우드 상에서 브랜드 이미지나 광고 크리에이티브를 보다 효율적으로 생성할 수 있는 파트너쉽을 발표했다. WPP는 엔비디아의 클라우드 상에서 어도비나 Getty Images와 같은 컨텐츠 제공업체의 이미지와 동영상 등을 모델에 파인튜닝해 소속 크리에이터들이 이미지를 효율적으로 제작하도록 한다.
바이오
바이오 분야에서는 항체 디자인이나 치료제 개발에 생성형 AI를 활용하고 있다. 기존 항체 발견 방법은 시간과 자원이 많이 들고 원하는 특성을 일일히 제어하기 힘든데 GPT-3와 같은 생성형 AI에 항원-항체의 상호 작용에 대한 대규모 데이터셋을 학습시켜 특정 항원에 대해 새로운 항체를 생성할 수 있다고 한다.
게임
게임 분야에서는 엔씨소프트가 자체 LLM을 개발했다고 한다. ChatGPT와 비슷한 1000억 개 파라미터가 넘는 모델을 만들어 내부적으로 활용한다고 한다. 게임 제작에는 대사 생성, 캐릭터 제작 및 베리에이션 등 수많은 수작업이 존재하지만 AI 모델을 활용하면 대사나 세계관 등의 텍스트를 빠르게 생성하고 몇 번의 클릭만으로 이미지를 생성해 수정해 사용한다는 것이다.
지금으로써는 생성형 AI의 부정적인 면보다는 이를 활용한 업무 효율 향상, 그리고 사람의 창의성을 도와줄 수 있는 기술로 장점이 커 보인다. 내가 하고 있는 업무나 일상생활에서 생성형 AI를 테스트해보고 효율성이나 창의성에 도움이 되는 부분이 있다면 적극적으로 사용하는 사람이 승자가 될 가능성이 높다. 앞으로 생성형 AI가 어떤 방향으로 발전하고 더 많은 혁신을 가져올 지 지켜보도록 하자.
| ||
마테크와 마케팅 데이터 분석에 대해 이야기 합니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.