'가성비' 좋은 LLM을 직접 만들어보자: PEFT를 활용한 LLM 경량화 테크닉


LLM 거대화 트렌드는 이제 언어 모델 개발의 새로운 표준이 되었다. 언어 모델의 데이터 학습에 있어서 가중치(weight)와 편향(bias)을 조정해 주는 매개변수(parameter)의 수와 모델이 학습하는 말뭉치(corpus)의 양이 많을수록 일반적으로 언어 모델의 성능은 뛰어난 것으로 알려져 있기 때문에 빅테크 기업들은 경쟁적으로 더 많은 양의 GPU와 리소스를 투입하여 최대한 큰 사이즈의 모델을 만드는 것에 혈안이 되어있다.

그러나 일반 사용자들이 감당할 수 없을 정도로 막대한 모델 훈련 비용은 LLM의 치명적인 단점이자 진입장벽이 되고 있다. 예를 들어 GPT-4와 같은 초거대언어모델(LLM)은 매우 뛰어난 성능을 자랑하는 반면 방대한 양의 훈련 데이터와 천문학적인 미세조정(Fine-tuning) 비용이라는 고질적인 문제를 안고 있다. 1750억 개의 매개변수(parameter)를 가진 GPT-3 이후의 초거대언어모델(LLM)은 미세조정에만 수천억 원이라는 천문학적인 비용이 들어가기 때문이다.
상황이 이렇다 보니 사전학습된 언어 모델의 소스코드가 공개된다고 하더라도 스타트업이나 개인이 공개된 모델에 추가 학습용 텍스트 데이터를 파인튜닝하여 태스크와 용도에 맞게 커스터미이징 하는 것은 거의 불가능했다. 이러한 문제점을 해결하기 위해 언어 모델 개발자들은 모델 사이즈를 줄이면서 LLM의 성능을 비슷하게 유지하기 위한 방법들을 고심하기 시작했다.
이번 글에는 LLM의 모델 성능을 거의 동일하게 유지하면서 PEFT(Parameter Efficient Fine-Tuning)의 개념을 알아보고 이를 적용하기 위한 대표적인 기법인 LoRA(Low Rank Adaption)와 양자화(quantization)에 대해 알아보자.
1. PEFT(Parameter Efficient Fine-Tuning)이란?
PEFT는 적은 매개변수 학습만으로 빠른 시간에 새로운 문제를 효과적으로 해결하는 미세조정 방법을 지칭한다. 수천억 개 이상의 매개변수를 가진 초거대언어모델(LLM)도 사실상 적은 파라미터만 조절하여 유사한 성능을 낼 수 있다는 연구결과가 있었는데, 이를 기반으로 PEFT 방법론 연구가 활발히 진행되고 있다.
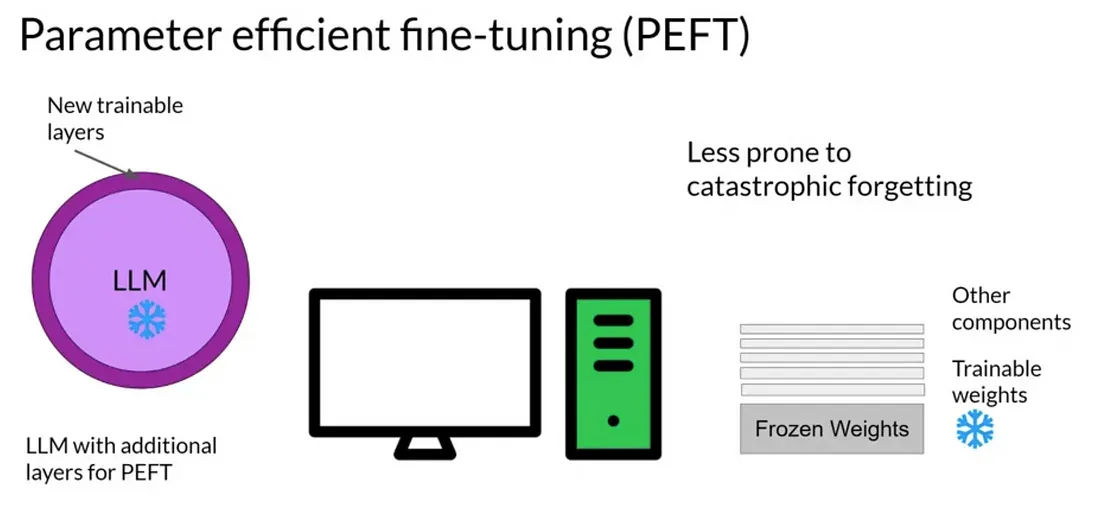
PEFT의 중요한 특징은 전체 모델을 조정하는 것보다 적은 계산 자원과 데이터만을 사용한다는 점이다. 이는 다양한 언어와 도메인의 데이터에 모델을 적용할 때 특히 유용하며, 각 도메인 또는 언어별로 작은 체크포인트만 로컬에 저장하면 효율적으로 작동한다. 다운로드나 업데이트의 제한이 있는 환경에서도 모델의 다양성을 유지하는 데 큰 도움이 된다.
PEFT는 또한 다양한 태스크에 모델을 신속히 적용하고자 하는 연구자나 개발자에게 유용하다. 기존에 학습된 LLM 위에 추가적인 레이어를 덧붙여 미세조정하는 것으로 새로운 작업에 대한 모델 적용 및 평가가 가능하다.
LoRA(Low Rank Adoption)
LoRA(낮은 순위 적응)는 PEFT 방법론 중 하나로, 대부분의 매개변수 가중치는 원래대로 유지하되 일부만 미세조정하는 방식을 사용한다. 이렇게 함으로써 훈련 비용과 컴퓨팅 리소스를 절약하면서도 특정 작업의 성능을 향상시킬 수 있다.
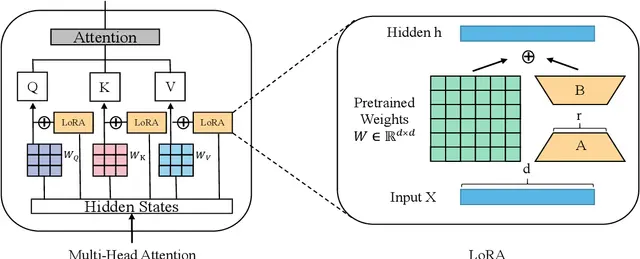
LoRA 작동 원리를 간략히 설명하면, 행렬의 차원을 'r'만큼 축소 후 원래 크기로 복원하는 것과, 은닉층 'h'에 특정 값을 추가하여 출력을 조절하는 것이 핵심이다. 이를 통해 원하는 출력값을 얻을 수 있게 된다.
양자화(Quantization)
양자화 역시 PEFT의 한 방법론으로, 언어 모델의 매개변수를 실수형에서 정수형으로 바꾸어 비트 수를 줄이는 과정을 말한다. 예컨대 32비트 부동 소수점 형태의 매개변수를 8비트 정수로 변환하는 것과 같이 비트 수를 감소시켜서 모델 사이즈를 줄이는 방식이다.
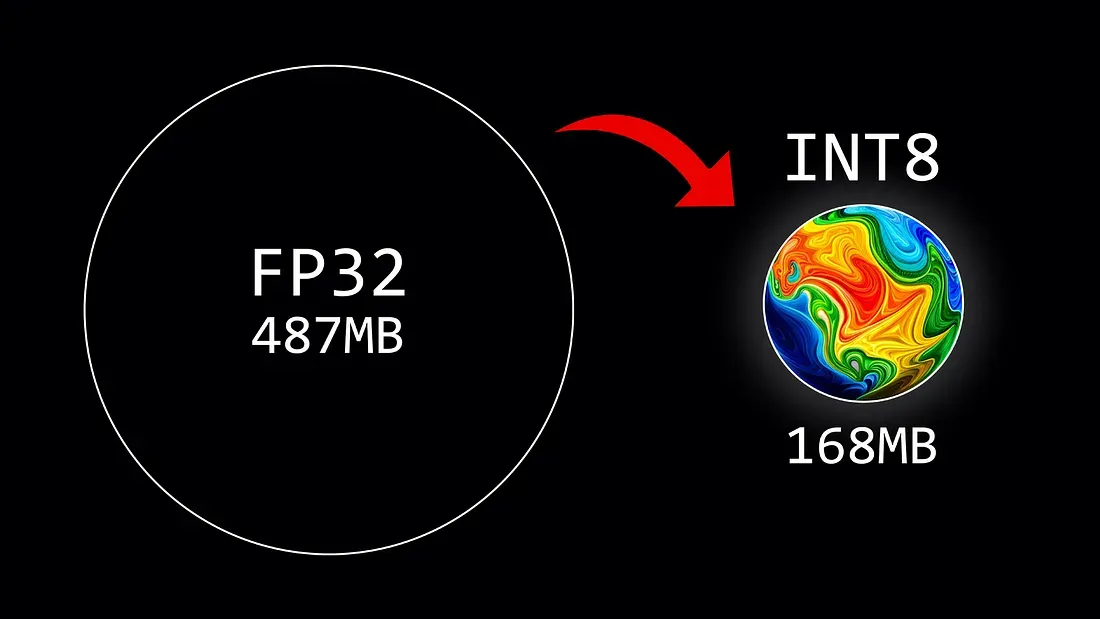
양자화된 언어 모델은 크기가 줄어들며, 계산의 효율성이 향상된다. 비트 수를 N배로 줄이면 곱셈의 복잡도는 NxN로 감소하게 되며, 이에 따라 float32를 사용하는 대신 int8을 사용하면 모델의 크기가 1/4로 줄어들고, 추론(inference) 속도와 메모리 사용량도 두 배에서 네 배까지 효율적으로 작동하게 된다.
2. PEFT 사용 시 주의사항
PEFT 기법을 사용한 모델은 훈련 시 필요한 GPU, 시간 등의 비용을 크게 절감해 주는 장점이 있다. 그러나 PEFT는 만능은 아니며, 사용 시 아래와 같은 점들을 고려할 필요가 있다.
- 성능 저하 가능성: PEFT의 목적은 훈련 및 계산 비용을 줄이면서도 성능을 유지하는 것이지만, 매개변수의 일부만을 조정하여 활용하기 때문에 원래 모델과 동일한 성능을 보장하지 않는다. 따라서 PEFT는 어디까지나 가성비 모델이라는 점을 염두에 두고 사용 전에 철저한 모델 평가가 필요하다 .
- 태스크에 따른 적합성: PEFT가 모든 태스크에 적합한 것은 아니다. 예로, 법률이나 의료와 같이 정확한 전문 지식이 요구되는 분야에서는 PEFT의 적용이 부적절할 수 있다. 이와 같이 정확성이 요구되는 태스크에서는 초거대언어모델(LLM)의 모든 파라미터를 필요로 할 수 있다.
- 하이퍼파라미터 조정: PEFT 적용 시 사용되는 하이퍼파라미터에 따라 성능이 크게 변할 수 있다. 최적의 성능을 위해 기초 모델에 대한 충분한 이해와 다양한 실험 및 조정이 필요하다는 사실을 인지할 필요가 있다. PEFT 방법론을 적용하기 위해서는 자연어 처리에 대한 이해와 모델링 경험이 필요하다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.