생성형 AI의 원리와 활용


삼성전자에서 자체 개발한 생성형 AI ‘삼성 가우스(Samsung Gauss)’가 탑재된 세계 최초의 AI 스마트폰 갤럭시24가 출시된 지 얼마 되지 않아 OpenAI가 영상 생성형 AI ‘소라(SORA)’를 출시하면서 생성형 AI는 연일 사람들을 충격에 빠뜨리고 있다. 이처럼 기업들이 거대한 자본력이 기술력과 데이터에 결합하면서 생성형 AI의 활용 분야는 넓어지고 있고 성능은 향상되고 있다.

생성형 AI의 성장세는 인공지능 업계 전체의 성장을 견인하고 있다고 해도 과언이 아니다. 미국의 조사 기관 Grand View Research의 최신 보고서에 따르면, 글로벌 생성형 AI 시장은 2022년 101.4억 달러에서 2023년부터 2030년에 이르기까지 매년 평균 35.6%씩 성장하여 1,093.7억 달러(약 150조) 규모로 성장할 것으로 예상된다.

기술을 올바르게 활용하기 위해서는 특성을 제대로 이해하는 것은 매우 중요하다. 따라서 생성형 AI 시대에 생성형 AI의 강점과 약점 그리고 활용 잠재성과 한계점을 명확히 알기 위해서는 생성형 인공지능의 특징을 이해할 필요가 있다. 도대체 생성형 AI는 기존의 머신러닝/딥러닝 기반 인공지능 모델과 어떤 점이 다르며 어떠한 특성을 가지고 있을까? 지금부터 생성형 AI의 원리를 파헤쳐 보자.
생성형 AI의 특징
생성형 AI는 기존의 머신러닝/딥러닝 기반 모델과 마찬가지로 심층신경망(DNN)과 통계학과 같은 핵심 원리를 활용하지만, 목적과 학습 방식 그리고 모델의 크기의 측면에서 매우 다르다.
1. 활용 목적
기존 머신러닝/딥러닝 기반 모델은 주어진 데이터를 학습하고 특정 작업을 수행하기 위한 패턴을 찾는 것에 중점을 두는 반면, 생성형 AI는 주어진 데이터로부터 새로운 데이터를 생성하고, 예측하는 것에 특화되어 있다.
즉, 기존의 머신러닝/딥러닝 알고리즘은 주어진 패턴에 따라 새로운 테스크를 수행하는 데에 중점을 두는 반면, 생성형 AI는 데이터를 생성하는 데에 더욱 중점을 둔다. 이러한 특성 덕분에 생성형 AI는 또한 데이터 부족한 상황에서도 효과적으로 작동할 수 있는데, 이는 생성형 AI가 기존의 머신러닝 모델보다 데이터의 의존도가 낮기 때문에 가능한 일이다.
2. 모델의 학습방식

생성형 AI는 주로 라벨링 되지 않은 데이터를 활용한 비지도 학습(Unsupervised Learning)을 사용하여 데이터의 분포를 학습하는데, 이러한 방식은 데이터 간의 관계를 파악하고 새로운 데이터를 생성하는 데에 도움이 된다. 반면, 기존의 머신러닝/딥러닝 방식의 모델은 지도 학습(Supervised Learning), 준지도 학습(Semi-supervised Learning) 혹은 강화 학습(Reinforcement Learning)과 같은 다양한 학습 방식이 적용될 수 있다.
3. 모델의 크기와 활용 범위
생성형 AI 모델은 일반적으로 매우 큰 모델이다. 생성형 AI를 구성하는 아키텍처는 수천억 개에서 수조 개에 이르는 매개변수(parameter)와 레이어로 구성되어 있으며, 수백만 또는 수십억 개의 가중치를 가진다. 이처럼 거대한 생성형 AI는 데이터로부터 학습하고, 새로운 데이터를 생성하는 데 필요한 복잡한 패턴을 파악하는 데에 특화되어있다.
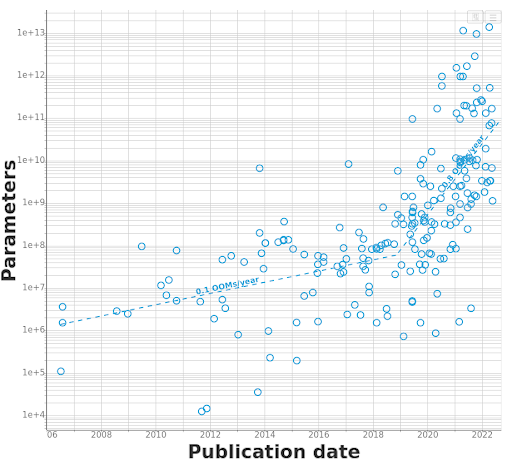
기존의 머신러닝/딥러닝 기반 모델은 생성형 AI와 비교하면 모델의 크기가 작은 편에 속한다. 또한 대부분의 기존 모델은 특정 작업을 수행하기 위해 설계된 반면, 생성형 AI는 글쓰기, 이미지 생성, 멀티 모달 등 다양한 작업에 활용될 수 있다.
4. 무작위성
기존의 딥러닝 및 머신러닝 모델은 주로 입력 데이터에 대해 고정된 방식으로 동작한다. 물론 기존의 모델에도 랜덤성이 활용되지만, 이는 보통 학습 초기화나 데이터 증강 등의 단계에서 한정적으로 도입된다. 한 번 설계된 모델은 일관된 예측을 하며, 정확도(Precision)과 민감도(Recall) 등 성능과 정확도를 측정하는 지표 역시도 명확하다.
반면에 생성형 AI가 생성해 내는 결과물은 그때그때 다르다. 예를 들어, 생성된 이미 지나 텍스트의 세부 사항은 랜덤한 요소에 의해 결정되고, 우리는 생성형 AI가 어떠한 과정을 거쳐 결과물을 생성해 내는지 알 수 없다. 따라서 생성형 AI의 정확도나 성능을 측정하는 기준 또한 상대적으로 불명확하고 난해할 수밖에 없다.
생성형 AI, 어떻게 활용할까?
생성형 AI의 등장은 기술 혁신과 산업 패러다임의 변화를 불러왔다. 이제 우리는 이 혁신적인 기술을 어떻게 활용할 것인지에 대한 질문에 직면하게 되었다. 생성형 AI의 활용 방안은 다양한 산업 분야에 걸쳐 있으며, 이에 대한 흥미로운 전망과 가능성이 제시되고 있다.
생성형 AI는 큰 모델 사이즈와 발전된 기술력 덕분에 기존의 머신러닝/딥러닝 기반 모델과는 다르게 비교적 적은 양의 데이터만으로도 놀라운 결과를 만들어낼 수 있다. 그뿐만 아니라 기존의 인공지능 모델이 한두 가지의 테스크만 수행하도록 한정되어 있는 것과 비교하여 거의 모든 테스크에 응용이 가능하다. 그러나 결과가 일정하지 않다는 무작위성과 성능 측정의 기준이 상대적으로 모호하다는 점은 사용 시 주의해야 할 점이다.
생성형 AI는 다양한 산업 분야에서 혁신적인 변화를 가져오고 있으며 이러한 변화는 우리의 삶을 더 편리하고 안전하게 만들어주는 데 큰 기여를 하고 있다. 앞으로도 더 많은 분야에서 생성형 AI의 활용이 확대될 것으로 예상되는 만큼 생성형 AI에 대한 올바른 이해와 활용법 숙지가 중요하다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |
