데이터 웨어하우스와 데이터 레이크의 차이를 아시나요

클라우드 빅3는 모두 알다시피 Microsoft사의 MS Azure, Amazon사의 AWS, Google사의 Google Cloud. 그런데, 2021년 뉴욕 거래소에 상장한 클라우드 기반 소프트웨어 회사가 하나 있는데, 현재 시총은 92조원이나 됩니다. 바그 주인공은 바로 2012년에 설립된 SNOWFLAKE입니다. ‘클라우드 사업은 빅테크 기업만의 소유물’이라는 업계의 시각이 있죠. 도대체 어떻게 된 일인지 차근차근 알아가 보도록 해요!
우선 클라우드의 종류에 대해 간단히 짚고 넘어갈게요. 사용자의 권한에 따라 On-Premise,Iaas, PaaS, SaaS (권한이 적은 순으로 나열) 이렇게 4가지로 구분됩니다. (On-premise는 클라우드 제품이 아닙니다! 기존 레거시 컴퓨팅 형태를 지칭하는 용어이죠) 보통 빅테크 업체는 IaaS나 PaaS를 중심으로 사업을 전개해나가고 있습니다. 반면, 스타트업은 SaaS를 중심으로 사용자 니즈에 버티컬하게 개발된 제품을 서비스하는 데요. 그래서 SaaS가 가장 대중적인 클라우드 제품이라고 불리기도 하죠.

그럼 스노우플레이크의 서비스는 어떤 형태일까요. 스노우플레이크는 SaaS 기반의 데이터 웨어하우스 서비스를 제공합니다. 스노우플레이크는 이미 빅3의 클라우드에 저장된 어마어마한 양의 데이터를 관리 및 시각화에 집중하는 거죠. 좀 더 버티컬한 성격을 띄고 있습니다.
이제는 마케터가 모르는 변수들끼리의 상관관계도 파악해서 비즈니스를 해야하는 시대가 온 만큼, 데이터를 제대로 처리하고 시각화하는 것은 비즈니스에서 필수가 되어버렸습니다.
특히, 여러 플랫폼의 데이터를 수집하면, 데이터 형태가 다른 경우가 있는데, 이를 데이터 사일로 현상이라고 합니다. 이 현상으로 인해 정확한 데이터 처리가 어려워지고 의미가 없어지기도 하죠.
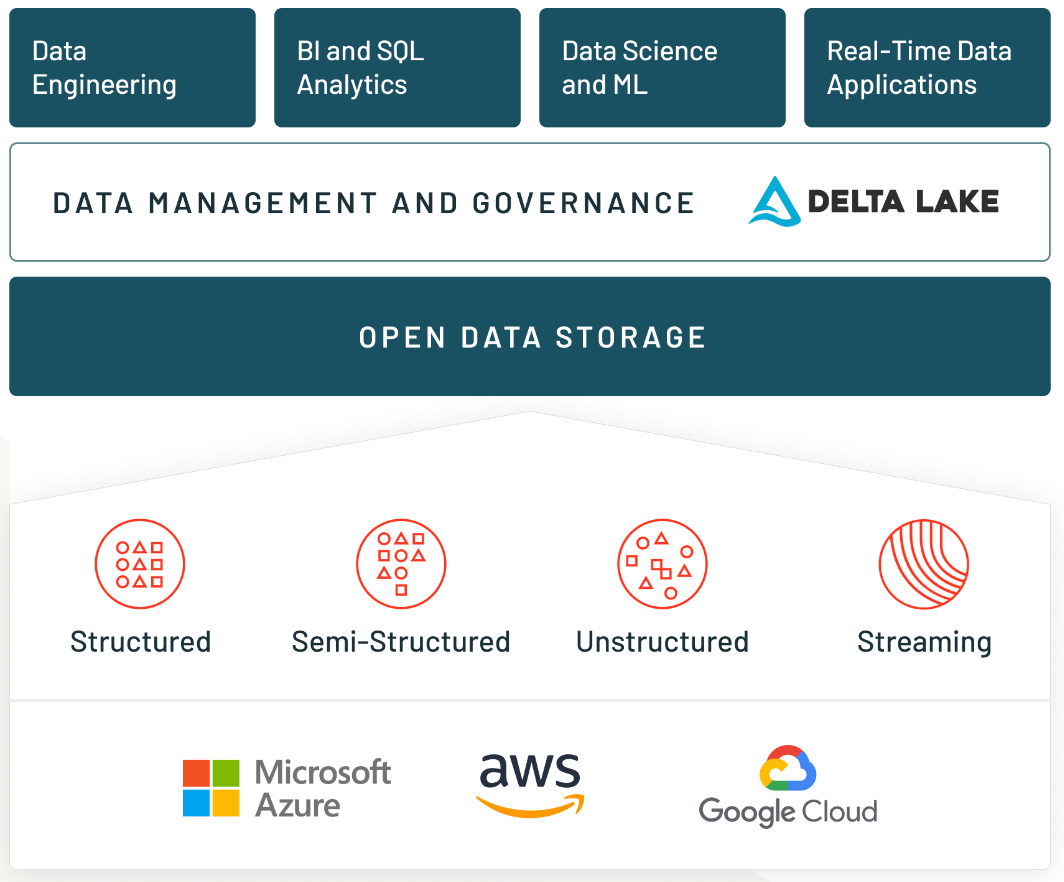
이러한 페인포인트 해결을 위해 스노우플레이크는 데이터 웨어하우징, 데이터 레이크, 데이터 엔지니어링, 데이터 사이언스, 데이터 애플리케이션을 개발할 수 있는 종합적인 클라우드 데이터 플랫폼을 지원합니다.
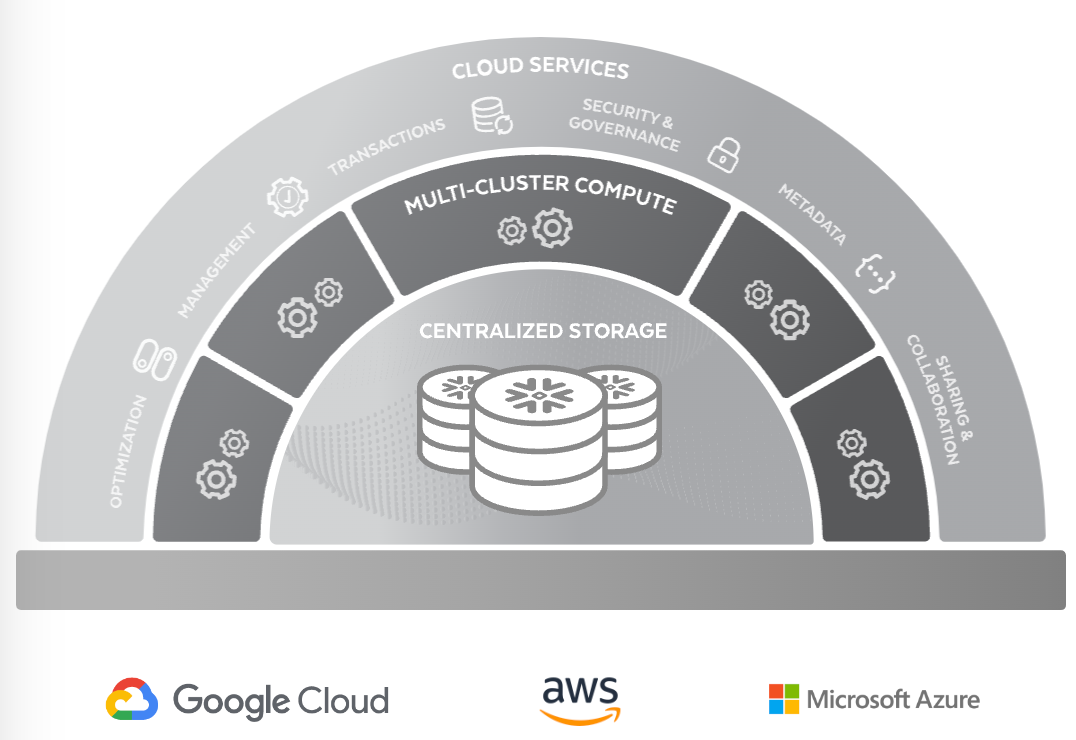
이 서비스 구조는 크게 3가지로 나뉘어요. 1) 통합 스토리지 2) 버추얼 웨어하우스 3) 클라우드 서비스 레이어 1단계에서 모든 데이터가 저장되고, 2단계에서 각 데이터의 종류/크기에 맞추어 데이터 처리를 진행합니다.이 때 사용자가 전처리를 수행하기에 신뢰도가 높은 데이터가 만들어집니다. 3단계에선 데이터 관리 작업을 자동하여 전반적인 인프라를 자동으로 관리하여 운영 인력을 줄입니다.
그 다음으로 DATABRICKS에 대해 알아볼게요 :)

아직 상장 전이지만 이미 기업 가치가 32조 원 정도로 평가받고 있습니다. 특히 a16z, alphabet 등의 투자를 받기도 했습니다. 데이터브릭스의 기업 가치는 왜 높은지, 앞서 말한 SNOWFLAKE와는 어떤 점이 다른지에 대해 탐구해보도록 해요.
우선, 데이터를 보관하는 방법과 목적에 따라 DATABRICKS와 SNOWFLAKE가 구분됩니다.
여기서 조금 헷갈릴 수 있으니 조심하세요!
- SNOWFLAKE: DATA WAREHOUSE -> 정형 데이터를 목적에 맞게 꺼내 쓸 수 있도록 잘 정리한 창고
- DATABRICKS: DATA LAKE-> 정형/반정형/비정형 데이터를 모두 꺼내쓸 수 있게끔 보관한 매우 큰 창고
다시 말해, 웨어하우스는 빠른 성능/고효율(데이터 분석)에 집중하고, 데이터레이크는 방대한 볼륨/저비용(데이터 저장/처리) 에 집중하죠. 전자는 이미 신뢰성이 높은 데이터의 business intelligence(BI), 시각화 기능을 제공한다면, 후자는 머신러닝, 빅데이터, 데이터 스트리밍 기능을 제공합니다. 보통의 대규모 조직은 각 목적에 맞게 웨어하우스와 레이크를 사용합니다. 모든 데이터는 레이크에 저장되지만, 각 목적에 맞게 각 팀에 맞게 여러 채널의 웨어하우스를 활용하는 거죠.
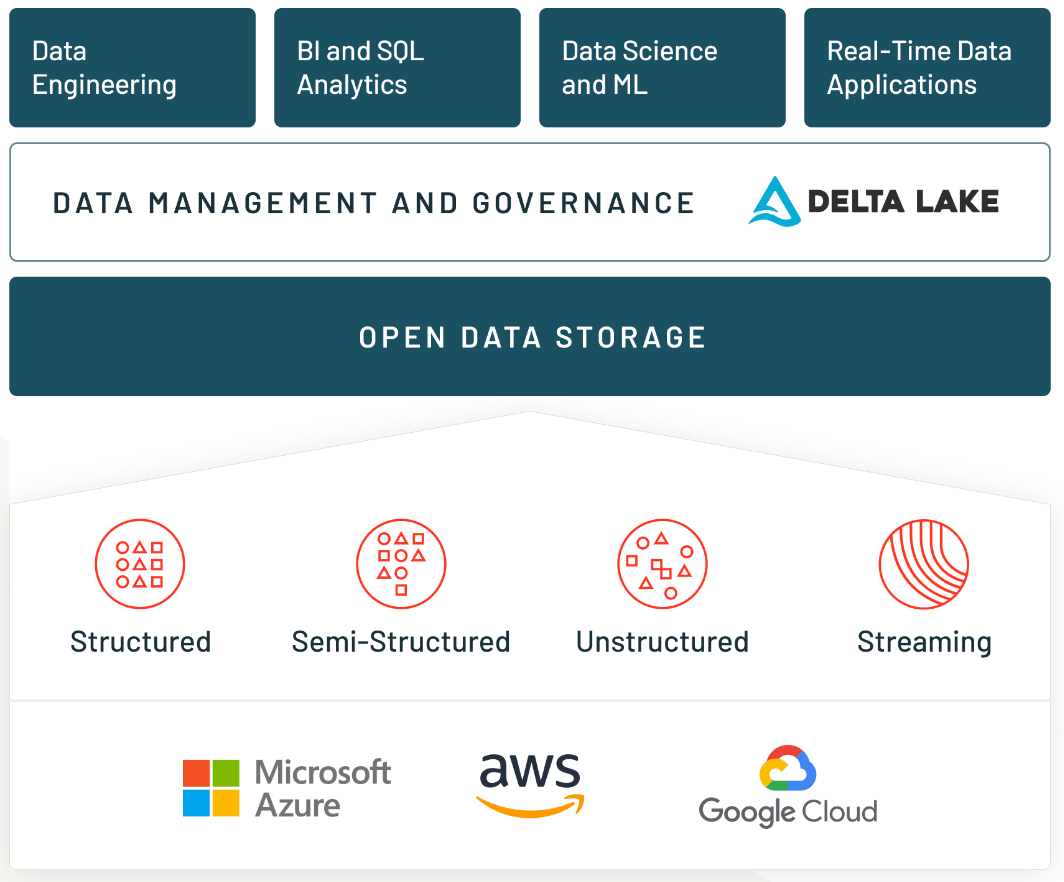
DATABRICKS의 DElTA LAKE는 대규모 데이터를 쉽게 가져오고 통합합니다. 대규모 메타 데이터들을 관리하고, 실시간 데이터를 기존에 저장된 레거시 데이터들과 통합해주는 기능 등이 있습니다.
그리고 빅데이터 시장에서의 오픈 소스 프로젝트의 역사(?)를 간단히 알면 좋은데요. 이 시장은 오픈 소스 전략이 메인인데, 이 중 하둡(Hadoop)과 아파치 스파크(Apache Spark)가 양대산맥입니다.
하둡은 데이터를 일정 기간 동안 모아두고 이후에 분석한다면, 스파크는 데이터를 실시간으로 처리하는 스트리밍 기술을 구현했습니다. 그리고 DATABRICKS는 스파크의 기술로 성장했습니다. 기존 UC버클리 연구팀에서 탄생한 스파크였고, 이들이 2013년에 회사를 창립한 게 바로 데이터브릭스인거죠. 따라서 데이터브릭스의 델타레이크도 오픈 API로 공개된 상태입니다.
오늘은 데이터웨어하우스와 데이터레이크의 차이점을 알아보았습니다. 이 둘은 서로 관련이 있지만 근본적으로 서로 다른 기술입니다. 데이터 레이크는 데이터 웨어하우스보다 더 많은 스토리지 옵션을 제공하고, 더 다양한 사용 사례가 있죠. 또한, 빅테크 기업들의 클라우드 서비스와는 전혀 다른 버티컬한 서비스라는 것도 잊지 마시구요! 더 재밌는 글로 또 찾아뵐게요 :)
| ||
잇린이(IT+린이) 제나팡입니다. 문돌이의 IT 이슈 따라잡기, 함께 할까요? |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.