환각 현상의 원인과 해결책


생성형 AI가 실제로 존재하지 않거나 사실이 아닌 정보를 사실인 것처럼 말하는 환각 현상(Hallucination)은 이제 사용자들에게 더 이상 낯설지 않다. OpenAI의 GPT-4.0과 Google의 Gemini 등 더 커진 모델 사이즈와 훈련 데이터로 무장한 신버전 모델이 출시되고 많은 성능 개선이 이루어지면서 생성형 AI은 더 이상 터무니없는 답변을 하지 않게 되었고, 환각 현상은 초기 생성형 AI이 보여준 하나의 재미있는 해프닝으로 마무리되는 듯했다.
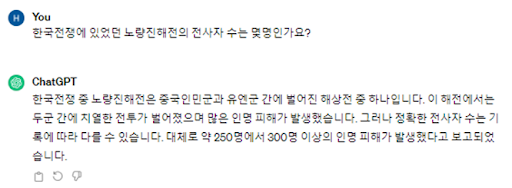
그러나 여전히 챗GPT를 비롯한 많은 생성형 AI 서비스들이 존재하지 않는 사실을 꾸며내거나 부정확한 정보를 제공하는 등 환각 현상에 취약한 모습을 보이고 있다. 예를 들어 ‘한국전쟁에서 있었던 노량진 해전’과 같이 그럴듯하지만 역사적 배경이 전혀 다른 두 가지 사건을 포함하는 모순된 질문을 하는 경우, 챗GPT는 여전히 해당 사건이 실존하는 사건인 듯 가정하고 답변을 내뱉을 뿐만 아니라 250에서 300명이라는 근거도 출처도 알 수 없는 숫자까지 제시한다.
이러한 환각 현상을 외재적 환각(Extrinsic Hallucination)이라고 한다. 외재적 환각은 콘텐츠 소스에서 확인할 수 없는 아웃풋을 생성하는 환각 현상의 한 유형이이며, 출처를 알 수도 없고 반박할 수도 없다는 특징이 있다. 생성형 AI의 매개변수(Parameter)가 늘어나고 성능이 향상되었음에도 불구하고 생성형 AI은 여전히 꽤나 높은 빈도로 상식과 맞지 않는 말을 그럴듯하게 지어내는 외재적 환각 현상을 보인다.
그러나 환각 현상의 진짜 심각한 문제는 위의 예시처럼 완전한 허구에 근거한 터무니없는 답변이 아니라 어느 정도 사실에 근거하고 있지만 잘못된 정보를 제공하여 사용자를 매우 교묘하게 속이는 경우다. 이처럼 답변의 근거가 되는 컨텐츠 소스와 모순되는 아웃풋을 생성하는 유형의 환각을 내재적 환각(Intrinsic Hallucination)이라고 한다.
내재적 환각은 입력된 정보와 생성된 정보가 다른 경우에 발생한다. 예를 들어 ‘최초의 에볼라 바이러스 백신은 2019년 FDA 승인을 받았다’는 내용을 학습한 AI가 실제 출력한 문장에서는 ‘최초의 에볼라 백신은 2021년 승인됐다’고 답하는 것이다. 이처럼 사전에 학습된 내용을 사실과 다르게 전달하는 것이 내재적 환각이다.
이처럼 교묘한 내재적 환각 현상은 생성형 AI의 확산을 막는 치명적인 장애물이다. 사용자들은 생성형 AI가 제공하는 답변이 어떤 데이터에 근거하고 있으며 정확한지 일일이 검증할 수 없기 때문이다. 따라서 명확한 소스에 근거한 정확한 답변이 필요한 비즈니스와 학술 연구 등 전문 분야에서 생성형 AI 도입 및 활용은 사실상 불가능하다.
이처럼 생성형 AI 기술의 발전에도 불구하고 환각 현상은 여전히 극복되지 않고 있으며 생성형 AI의 고질적인 문제로 남아있다. 이러한 환각 현상은 도대체 어떤 이유로 발생하고 어떻게 극복될 수 있을까?
1. 생성형 AI의 작동 원리
생성형 AI의 환각 현상은 크게 데이터에 의한 것과 학습 및 추론 과정에서 발생하는 것 두 가지로 나누어 볼 수 있다. 이는 생성형 AI의 작동 원리를 살펴보면 쉽게 알 수 있는데, 챗GPT나 Google의 Gemini를 비롯한 대부분의 생성형 AI은 방대한 텍스트 데이터를 사전 학습(Pre-training)한 뒤에 이전 단어에 기반해 다음 단어를 순방향 예측하는 자기회귀(AR, Auto Regressive) 방식으로 작동한다.

2. 환각 현상의 원인
이처럼 생성형 AI는 훈련 데이터를 바탕으로 문맥에서 다음에 나올 가능성이 높은 단어를 예측하고, 이를 바탕으로 가장 적합한 답변을 생성하기 때문에 훈련 데이터와 학습 및 추론 방식에 많은 영향을 많이 받을 수밖에 없는 것이다. 구체적으로 생성형 AI 환각 현상의 원인은 다음과 같이 크게 두 가지로 나누어 볼 수 있다.
1) 데이터에 의한 환각
우선 데이터에 의한 환각은 생성형 AI가 불충분하거나 편향 혹은 결함이 있는 데이터로 훈련된 경우에 발생한다. 이러한 데이터에 의한 환각은 생성형 AI 환각 현상의 대부분을 차지하는데, 이는 대부분의 경우 완벽한 데이터셋(Dataset)을 확보하기가 어렵기 때문이다.
2) 학습 및 추론에 의한 환각
다음으로는 학습 및 추론에 의한 환각이 있다. 위에서 설명했듯이 생성형 AI는 입력된 단어와 시퀀스에 의한 자기회귀 알고리즘을 통해 다음 단어를 예측한다. 이 과정에서 생성형 AI은 인코더와 디코더라는 구조를 활용하여 인간과 같이 가장 가능성이 높은 답변을 예측해낸다. 그러나 본질적으로 생성형 AI은 인간과 다르게 자신이 생성하는 내용을 이해하지 못하기 때문에 엉뚱한 답변이 환각으로 출력되는 경우가 발생한다.
3. 환각현상의 해결책
이처럼 환각 현상은 다양하고 복잡한 원인에 의해 발생하기 때문에 아쉽게도 환각 현상을 없애기 위한 단 하나의 해결책은 현재로서는 존재하지 않는다. 이에 따라 다양한 방법들이 융합되어 시도되고 있는데, 대표적인 방법으로는 생성형 AI 훈련 데이터 품질을 향상시키는 방법 뿐아니라 프롬프트 엔지니어링(Prompt Engineering)과 검색증강생성(RAG, Retrieval Augmented Generation) 그리고 여러 생성형 AI을 연결하는 에이전트(Agent)를 활용하여 환각현상과 잘못된 정보를 줄이는 방법등이 있다. 이러한 방법을 통칭하여 LLM 오케스트레이션(LLM Orchestration)이라고 부른다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.