[슈퍼브 인사이트] 데모에서는 완벽한데 실제 서비스에서 왜 망가질까요?(나의 AI 에이전트만😂)
에러 없이 틀린 답을 내는 AI 에이전트, 원인은 모델이 아닌 '설계'에 있습니다. AI 에이전트를 위한 분산 시스템 설계 원칙과 피지컬 AI 시대를 주도할 슈퍼브에이아이의 '비전 인텔리전스' 핵심 내용을 확인해 보세요.

![[슈퍼브 인사이트] 완벽한 데모가 위험한 이유.](https://storage.ghost.io/c/73/74/73741b5e-0bdf-4e6f-9161-743bc6f76d78/content/images/size/w2000/2026/07/insight-thumb-2026-04-28.png)
>> 뉴스레터 구독하기
🌟 SUPERB Spotlight
AI 에이전트는 이미 분산 시스템입니다 — 그렇게 설계하지 않았을 뿐
본 글은 Medium의 'Your AI Agent Is Already a Distributed System — You Just Didn’t Design It That Way'를 편집한 것으로 전체 내용은 원글을 참고해 주세요.
프로덕션 AI 에이전트의 장애 원인은 대부분 모델이 아니라 설계에 있습니다.
아이디어를 가지고 AI와 빠르게 만든 AI 에이전트는 데모 환경에서 항상 매끄럽게 작동합니다. 질문을 입력하면 에이전트가 여러 도구를 활용해 정보를 모으고 깔끔한 답변을 내놓죠. 그런데 실제 서비스를 런칭하고 나면 이야기가 달라집니다. 일부 요청이 아무 안내도 없이 중단되거나, 그럴듯해 보이지만 사실과 다른 답변이 생성되기도 합니다. 문제가 어디서 생겼는지 파악조차 어렵습니다. 프로덕션 에이전트 시스템에서 흔하게 벌어지는 일들일 텐데요.
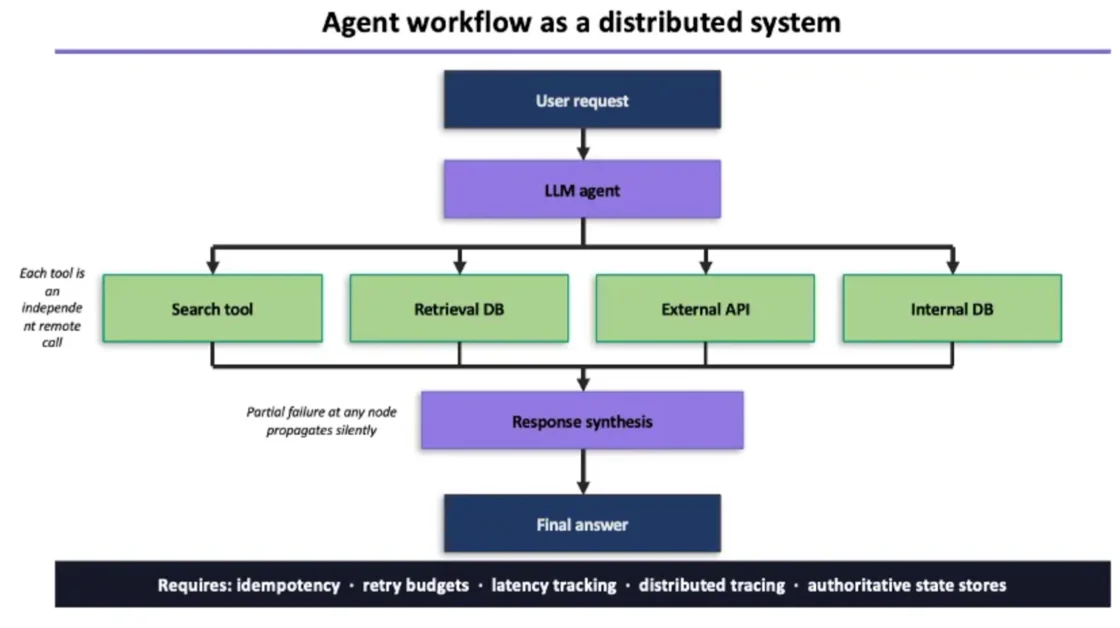
에이전트는 처음부터 여러 시스템이 얽혀 있습니다
이러한 이슈를 마주하게되는 이유는 실제 프로덕션 AI 에이전트가 혼자 움직이지 않기 때문입니다. 정보를 검색하고, 외부 API를 호출하고, 데이터베이스를 읽고, 그 결과를 조합해 다음 행동을 결정하기 때문인데요. 각 단계는 독립적으로 운영되는 외부 서비스와 통신하는 과정입니다. 즉, 에이전트 하나가 사실상 여러 시스템이 연결된 네트워크처럼 작동하는 겁니다. 언어 모델(LLM)은 그 안에서 오케스트레이터 역할을 할 뿐이고요.
사실 이런 문제들은 새로운 것이 아닙니다. 부분적인 오류, 일관성 없는 상태, 네트워크 지연처럼 에이전트 시스템에서 나타나는 장애들은 분산 시스템 엔지니어(여러 서버에 걸친 대규모 시스템을 설계하는 개발자)들이 지난 20년간 다뤄온 문제와 본질적으로 같습니다. 해결책도 이미 있습니다. 다만 그 패턴을 에이전트에는 아직 제대로 적용하지 못하고 있는 것이 문제일 수 있는데요.
중간 정도 복잡성을 가진 에이전트의 실행 흐름은 사실 여러 작업이 순서대로 연결된 파이프라인에 훨씬 가깝습니다. 그런데도 대부분의 팀이 복잡한 네트워크 시스템이라면 반드시 갖춰야 할 안전장치들을 빠뜨린 채 만들고 있습니다. 분산 시스템 분야에서는 모든 것이 성공할 것이라는 순진한 가정을 ' 해피 패스 아키텍처' 라고 부릅니다 .
- 장애 감지: 어떤 단계에서 실패했는지 파악할 수 있어야 합니다
- 중복 요청 방지: 같은 요청이 반복 실행되지 않도록 보장해야 합니다
- 실행 추적: 전체 흐름을 기록하고 재현할 수 있어야 합니다
백엔드 엔지니어라면 당연히 챙겨야 할 것들입니다. 이는 에이전트를 만들 때도 마찬가지로 염두해 둬야하는 사항들인데요.
실패는 예외가 아니라 기본값입니다
대부분의 에이전트 시스템은 도구 호출이 성공하거나, 아니면 명확하게 실패한다는 것을 전제로 합니다. 그런데 실제로는 그 중간 어딘가에서 문제가 생기는 경우가 훨씬 많습니다. 응답이 중간에 끊기거나, 데이터 일부만 돌아오거나, 네트워크상으로는 성공했지만 내용이 잘못된 결과가 오기도 하는 것이죠. 분산 시스템 분야에서는 모든 것이 성공할 것이라는 이런 순진한 가정을 '해피 패스 아키텍처' 라고 부릅니다. 신뢰할 수 있는 시스템은 잘 될 것을 전제로 설계하는 것이 아니라, 실패를 기본값으로 놓고 설계해야 합니다.
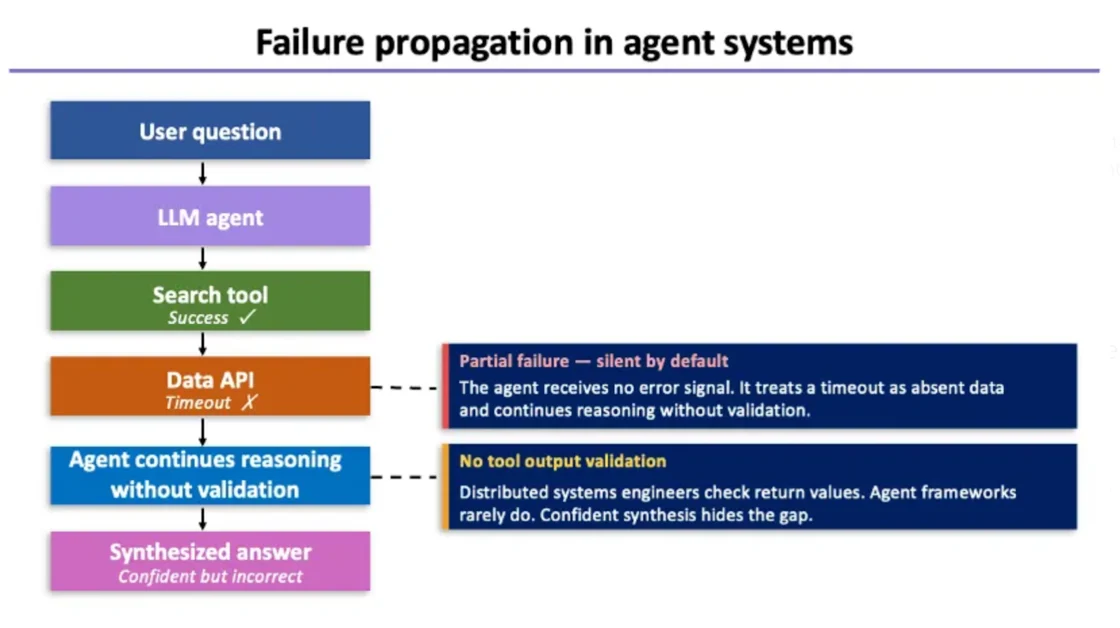
조용히 틀린 답변이 나오는 이유
에이전트 시스템에서 가장 까다로운 실패는 에러가 발생하지 않는 실패입니다. 예를 들어, 에이전트가 특정 주제를 리서치해서 요약문을 작성하는 상황을 생각해봅시다.
- 에이전트가 검색 도구를 호출합니다
- 검색 도구가 응답하지 않고 중단됩니다
- 에이전트는 이를 인식하지 못한 채 넘어갑니다
- 다른 도구에서 일부 정보를 가져옵니다
- 가져온 정보와 스스로 생성한 내용을 섞어 요약문을 완성합니다
시스템은 정상적으로 작동한 것처럼 보이고, 사용자는 완성된 답변을 받습니다. 하지만 그 안에는 검증되지 않은 내용이 포함되어 있습니다. 아무도 눈치채지 못한 채로요. 이러한 문제를 방지하려면 각 도구의 출력값이 다음 단계로 넘어가기 전에 반드시 검증되어야 하고, 실패했을 때는 에이전트가 이를 명확히 인식하고 처리할 수 있어야 합니다.
실수가 두 배가 되는 재시도, 느려지는 응답
네트워크 오류가 발생했을 때 요청을 재시도하는 건 일반적인 대응이죠. 그런데 에이전트 환경에서는 주의가 필요합니다. 결제나 주문처럼 한 번 실행되면 실제 결과가 발생하는 작업을 에이전트가 자동으로 재시도하면 문제가 생깁니다.
- 결제 API가 두 번 호출되면 → 고객에게 중복 청구
- 주문 API가 두 번 호출되면 → 상품이 두 번 배송
- 캘린더 API가 두 번 호출되면 → 동일한 일정이 두 개 생성
이러한 치명적인 오류들을 방지하려면, 당연하게 같은 요청이 반복되더라도 결과는 한 번만 처리되도록 설계해야 합니다. 응답 속도도 마찬가지입니다. 에이전트가 도구를 순서대로 하나씩 호출하는 구조는 각 단계의 시간이 그대로 누적됩니다. 이를 관리하려면 다음이 필요합니다.
- 동시에 처리할 수 있는 단계는 병렬로 실행하기
- 자주 사용되는 결과는 미리 저장해두기
- 전체 실행 시간에 상한선 두기
문제를 파악하려면 기록이 있어야 합니다
프로덕션에서 문제가 생겼을 때 가장 먼저 해야 할 일은 무슨 일이 있었는지 파악하는 것일 텐데요. 그런데 실행 기록이 없으면 어떤 단계에서 잘못됐는지, 어디서 지연이 발생했는지 알 방법이 없습니다. 에이전트 시스템에는 다음 항목들이 처음부터 포함되어야 합니다.
- 각 도구 호출의 입력값, 출력값, 실행 시간, 성공 여부 기록
- 에이전트가 어떤 정보를 바탕으로 결정을 내렸는지 재현할 수 있는 상태 스냅샷
- 어떤 단계가 전체 응답 속도를 늦추는지 파악할 수 있는 단계별 측정
이러한 사항들은 장애가 발생한 후에 추가하는 것이 아니라, 처음 설계할 때부터 포함되어야 하는 부분입니다.
모델보다 중요한 것
AI 에이전트를 이야기할 때 관심은 주로 모델 성능에 쏠립니다. 더 정확한 추론, 더 긴 맥락 처리 능력처럼요. 물론 중요한 요소이지만, 실제 서비스에서는 모델보다 그 주변 설계가 잘되어야 에이전트가 안정적으로 작동하는 경우가 많습니다. 프로덕션 환경에서 잘 버티는 서비스를 제공하는 팀들은 대부분 이 점을 일찍 인식한 팀들이겠죠. 에이전트를 단순한 AI 도구가 아니라, 여러 시스템이 연결된 구조물로 보고 그에 맞게 설계한 것인데요. 이 관점의 차이가 장애 대응 방식, 도구 설계 방식, 그리고 서비스 안정성 전체를 바꿉니다. 모델은 무엇을 할지 판단합니다. 그 판단이 실제로 잘 실행되는지는 설계가 결정합니다.
📌 주목해야 할 핵심 인사이트
1. 새로운 기술도 결국 기존 문제를 똑같이 겪습니다
AI 에이전트는 최신 기술처럼 보이지만, 실제로 겪는 문제들은 20년 전 개발자들이 복잡한 소프트웨어 시스템을 만들 때 이미 겪었던 것들입니다. 새로운 도구가 나올 때마다 "이번엔 다를 것"이라고 생각하지만, 결국 비슷한 지점에서 막히게 됩니다. 인사이트는 여기서 나옵니다. 새 기술을 빠르게 도입할 때일수록, 이미 검증된 선례와 해결책을 먼저 찾아보는 것이 훨씬 효율적입니다.
2. 겉으로 작동하는 것과 제대로 작동하는 것은 다릅니다
이 글에서 가장 인상적인 지점은 "시스템이 멈추지 않아도 틀릴 수 있다"는 부분입니다. 에이전트뿐 아니라 어떤 시스템이든 마찬가지입니다. 눈에 보이는 결과물이 정상적으로 나온다고 해서 내부가 제대로 돌아가고 있다는 의미는 아닙니다. 제품이나 서비스를 운영할 때, "일단 돌아가니까 괜찮다"는 판단은 위험할 수 있습니다. 문제는 보통 가장 바쁜 시점에, 가장 예상치 못한 방식으로 터집니다.
3. 설계는 만들기 전에 하는 것입니다
기록 체계, 오류 대응, 중복 방지 같은 안전장치들은 문제가 생긴 후에 추가하면 이미 늦습니다. 이건 AI 에이전트에만 해당하는 이야기가 아닙니다. 어떤 서비스나 프로세스를 설계할 때도 동일하게 적용됩니다. "나중에 고치면 되지"라는 생각으로 시작한 것들이 결국 가장 큰 기술 부채가 됩니다. 처음부터 실패를 전제하고 설계하는 것, 그게 결국 가장 빠른 길입니다.
✏️ SUPERB Curation
슈퍼브 한동훈 ML Engineer의 추천:
Google DeepMind, 산업 현장 로봇을 위한 공간 추론 모델 Gemini Robotics-ER 1.6 공개
Google DeepMind가 로봇의 물리 세계 이해를 한 단계 끌어올린 Gemini Robotics-ER 1.6을 출시했습니다. 이전 버전 대비 가장 눈에 띄는 개선은 포인팅(pointing) 정밀도, 멀티뷰 성공 감지, 그리고 계기판 읽기(instrument reading) 세 가지 인데요.
특히 계기판 읽기는 Boston Dynamics와의 협업을 통해 발굴된 기능으로, Spot 로봇이 산업 시설을 순회하며 압력 게이지나 액면계 같은 아날로그 계기를 자율적으로 판독할 수 있게 합니다.
모델은 이미지 줌인 → 포인팅 → 코드 실행의 순서로 중간 추론 단계를 거쳐 눈금 간격까지 정확히 읽어내며, agentic vision을 함께 사용할 경우 성공률이 93%에 달한다고 합니다. 안전 측면에서도 물리적 제약 조건 준수와 부상 위험 감지 성능이 이전 세대 대비 크게 향상되었다고 하는데요. Gemini API와 Google AI Studio를 통해 지금 바로 사용할 수 있습니다.
차문수 CTO의 추천:
Tencent, 텍스트나 이미지 한 장으로 탐색 가능한 3D 세계를 생성하는 World Model HY-World 2.0 공개
Tencent가 멀티모달 입력(텍스트, 이미지, 영상)으로부터 실제 3D 에셋을 생성하고 재구성하는 월드 모델 HY-World 2.0을 공개했습니다. 기존 Genie 3, Cosmos 같은 영상 기반 월드 모델이 픽셀 단위 영상을 생성하는 데 그쳤다면, HY-World 2.0은 Unity/Unreal Engine/Isaac Sim에 바로 임포트 가능한 메시(mesh)와 3DGS(3D Gaussian Splatting) 형태의 3D 에셋을 출력합니다.
파이프라인은 파노라마 생성 → 탐색 경로 계획 → 씬 확장 → 3D 합성의 4단계로 구성되며, 소비자 GPU에서 실시간 렌더링과 물리 기반 충돌 처리도 지원합니다. 현재는 3D 재구성 모듈인 WorldMirror 2.0의 코드와 가중치가 공개된 상태이며, 월드 생성 전체 파이프라인과 파노라마 생성 모듈은 순차 공개 예정이라고 하는데요.
영상 생성 수준을 넘어 편집 가능한 3D 세계 자체를 산출물로 만드는 방향으로 월드 모델의 패러다임이 이동하고 있음을 보여주는 사례입니다. 합성 데이터 생성이나 시뮬레이션 환경 구축을 검토 중인 팀이라면 눈여겨볼 만한 업데이트입니다.