[3분 알고리즘] 그라디언트 부스팅

![[3분 알고리즘] 그라디언트 부스팅](https://storage.ghost.io/c/73/74/73741b5e-0bdf-4e6f-9161-743bc6f76d78/content/images/size/w2000/2023/04/pRxh6XPyF8KnhTLVWa3zX9OeGNt7HDCSPV-FT7Ptqyl-khGbQNAyyl0gVmqsWS5DYlEjbidD09jIVRIYNnOlNiaXId1AgvplmyyjFNDnGz93CTBtHEfIp3j_T7eakwHUB4gAPkIh00pKwhd8pLJ8UD0.jpg)
이번 글에서는 의사결정나무를 활용한 앙상블 모델 가운데 그라디언트 부스팅 알고리즘에 대해 알아보려고 한다.
흔히 부스팅이란 무언가를 한껏 강화시키는 의미로 사용되는데 머신러닝에서 부스팅은 약한 모델 을 여러 번 순차적으로 적용해 강한 모델을 만들어 나가는 것을 의미한다.
그런 점에서 앞서 랜덤 포레스트가 여러 개의 의사결정나무를 중복적으로 샘플링한 데이터셋에 적용한 결과를 평균함으로써 다양한 데이터셋에 강한 모델을 만들었다면 부스팅은 이전 학습기 (의사결정 나무)가 잘못 예측한 데이터를 다음 학습기가 학습함으로써 순차적으로 예측 정확도를 높여가는 점이 다르다. 그럼 그라디언트 부스팅의 기본 개념과 작동원리에 간단히 알아보도록 하자.
그라디언트 (Gradient) + 부스팅 (Boosting)
선형회귀 알고리즘이 모델의 예측도를 높이기 위해 어떻게 최적의 가중치를 찾아갔는지 기억 나는가? 실제값과 예측값의 차이를 제곱해 평균한 평균제곱오차(MSE)를 손실함수로 하고 이 손실함수가 최소가 될 때 가설함수의 가중치를 경사하강법(Gradient Descent)을 통해 찾았다.
경사하강법이란 손실함수의 미분값의 크기가 점차 줄어드는 방향으로 가중치를 업데이트하며 손실함수의 최소값을 찾아가는 방법을 말한다. 이 때 손실함수를 미분하면 미분값은 예측값 - 실제값이 된다. 미분값(그라디언트)이 양수이든 음수이든 손실함수의 최소값을 찾기 위해서는
그 크기(기울기)가 점차 줄어드는 방향으로 이동해야 하는데, 그라디언트에 마이너스를 취해 가중치를 업데이트하면 된다.
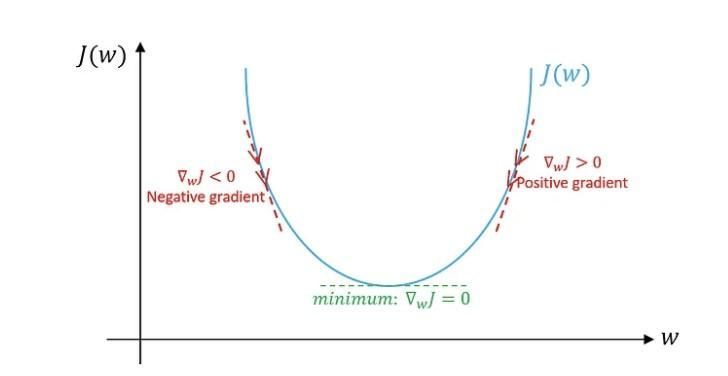
그라디언트에 마이너스를 취하면 실제값 - 예측값이 되는 데 이는 곧 잔차(residual)를 의미한다. 그라디언트 부스팅은 선형회귀와 같은 작동방식은 아니지만 실제값과 예측값의 차이인 잔차를 학습해 나가며 잔차를 줄여나가는 방식이다. 즉, 이전 학습기의 잔차를 다음 학습기가 학습하고 학습기를 계속 추가해 가면서 잔차를 줄여가는 방식이다. 선형회귀 알고리즘에서 그라디언트가 줄어들며 손실함수의 최소값을 찾아나가는 것과 같은 원리에서 그라디언트 부스팅이라 불린다.
“잔차를 줄여간다 = 그라디언트(기울기)를 줄여간다”
- 그라디언트 부스팅의 학습원리
그럼, 구체적으로 그라디언트 부스팅이 어떻게 잔차를 학습해 나가는 지 한 번 살펴보도록 하자.
예시에서는 그라디언트 알고리즘의 이해를 위해 분기를 한 번만하는 단순한 의사결정나무 모델을 가정했다.
성별과 키 데이터를 가지고 몸무게를 예측하는 회귀 문제에 그라디언트 부스팅을 적용한다고 하자. 모델의 초기 예측값은 0 또는 예측해야 할 타깃변수의 평균으로 초기화할 수 있다. 즉, 일단 모든 데이터 샘플을 몸무게의 평균인 54.65로 예측하는 초기 모델이다.
첫 번째 학습기, 즉 의사결정나무는 실제 몸무게에서 초기 예측값을 뺀 잔차를 계산하고 이를 학습한다. 의사결정나무는 앞서 이야기 한 것처럼 모든 피처의 모든 데이터 포인트를 고려해 평균제곱오차 (MSE)가 최소가 되는 값을 분기점으로 택해 분기해 나간다. 그리고 예측값은 각 데이터가 속한 최종 리프에 속한 값들의 평균이 되었다.
첫 번째 학습기는 잔차를 학습하고 잔차가 가장 줄어드는 분기점으로 Height <=171.5를 택해 분기했으며 각 그룹의 예측값은 각각 -7.25와 7.25가 된다. 이를 초기 예측값에 더해 최종 예측값을 업데이트한다.
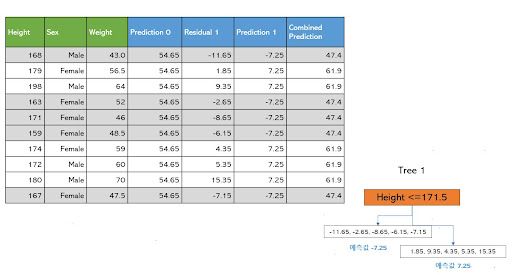
두 번째 학습기 역시 실제 몸무게에서 앞서 업데이트된 최종 예측값을 뺀 잔차를 다시 계산하고 이를 학습해 역시 잔차가 가장 줄어드는 분기점을 택해 분기한다. 이번에는 Height <=179.5를 기준으로 분기했으며 각 리프의 예측값은 -1.295와 5.1이 된다. 이를 앞서 최종 예측값에 더하면 다시 최종 예측값이 업데이트 된다.
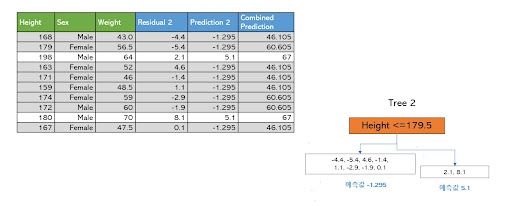
첫 번째 학습기가 학습한 잔차보다는 두 번째 학습기가 학습한 잔차가 더 줄어드는 것을 볼 수 있고 최종 예측값은 점차 실제값에 가까워지는 것을 볼 수 있다. 이 과정을 반복하며 학습기를 추가해 가면서 부스트된 모델의 최종 예측값은 앞서 나온 모든 예측값들의 합 (Prediction 0 + Prediction 1 + Prediction 2…)으로 업데이트되게 된다.
사이킷런으로 모델링하기
마찬가지로 사이킷런의 그라디언트 부스팅 회귀 라이브러리를 활용해 모델링을 간단히 해보도록 하자. 그라디언트 부스팅 역시 랜덤 포레스트와 마찬가지로 의사결정나무를 활용한 앙상블 모델 이므로 의사결정나무의 하이퍼 파라미터 설정할 수 있다.
그라디언트 부스팅 모델은 기본적으로 100개의 학습기로 부스팅을 해가가며 잔차를 줄여가는 데 경사하강법을 100번 실행했다고도 볼 수 있을 것이다. subsample=1은 학습기가 기본적으로 모든 데이터셋을 사용해 학습한다는 것이고 랜덤 포레스트와 달리 max_features=None은 모든 특성을 사용해 분할하는 것을 기본으로 하는 것을 알 수 있다.

예시로 든 키 성별 데이터셋을 만들고 사이킷런의 GradientBoostingRegressor 알고리즘을 불러와 학습시킨다. 학습기(n_estimators)는 5개로 설정했고, 최대 분기(max_depth)는 2번으로 설정했다. 테스트 데이터에 대한 예측은 학습한 모델에 predict 함수를 붙여 예측할 수 있다.
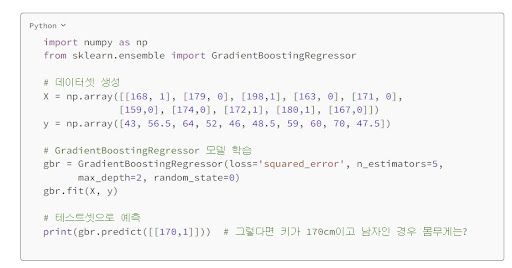
| ||
마테크와 마케팅 데이터 분석에 대해 이야기 합니다. |

슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.