H200 32장으로 비전 AI 파운데이션 모델 8개월 만에 학습한 방법 — AWS 서밋 서울 2026 발표
슈퍼브에이아이는 AWS SageMaker HyperPod에서 NVIDIA H200 32장으로 산업 특화 비전 파운데이션 모델 '제로(ZERO)'를 단 8개월 만에 학습 완료했습니다. 400만 장 데이터 파이프라인, FSx 병목 해결, Flexible Training Plan으로 비용 40% 절감한 실전 노하우를 공개합니다.

TL;DR (핵심 요약)누구를 위한 글인가: 대규모 비전 AI 모델을 자체 학습하려는 ML 엔지니어, AI 인프라 의사결정자, 그리고 산업 현장에 즉시 적용 가능한 Open-World 비전 AI를 찾는 제조·물류·건설 분야 기술 책임자.
무엇을 얻을 수 있는가: 슈퍼브에이아이가 산업 특화 비전 파운데이션 모델 '제로(ZERO)'를 단 8개월 만에 학습 완료한 AWS SageMaker HyperPod 기반 인프라 전략, 400만 장 큐레이션 데이터 파이프라인 설계, FSx for Lustre 병목 해결법, Flexible Training Plan으로 학습 비용을 40% 이상 절감한 실전 노하우.
핵심 결과: H200 32장으로 4노드 분산 학습 환경 구성, FSx 데이터 로딩 30시간 → 수 분 단축, 본학습 시작 시 I/O 대기 0초, 산업용 멀티 도메인 벤치마크에서 글로벌 경쟁 모델 대비 약 48% 격차로 1위 달성.
본 포스팅은 AWS Summit Seoul 2026에서 차문수 CTO의 발표 내용을 정리한 것입니다.
1. 왜 지금, 자체 비전 파운데이션 모델인가
산업 현장의 비전 AI 도입은 여전히 '도입 자체'에서 막힌다
맥킨지의 The State of AI in 2024 보고서에 따르면, 생성형 AI를 사용하는 조직의 47%가 AI 모델을 자체 학습 또는 커스터마이징해서 사용하고 있습니다. 기업들이 더 이상 '공개 모델 그대로 가져다 쓰기'에 만족하지 못한다는 의미입니다.
문제는 다음입니다. 한국 제조 현장은 특히 가혹합니다.
- 삼일PwC의 분석에 따르면 국내 중소 제조기업의 AI 도입률은 0.1% 수준에 그칩니다.
- NIA(한국지능정보사회진흥원)는 국내 제조업의 AI 활용은 '초기 단계'이며, 도입 후에도 '실질적 변화 없음' 응답이 우세하다고 진단합니다.
- 업계 현장 진단에 따르면 제조업의 AI 도입 시도는 80%를 넘지만, 실제 양산까지 안정적으로 안착하는 비율은 10~15% 수준에 불과합니다.
기존 비전 AI의 3가지 한계 (슈퍼브에이아이 자체 진단)
| 한계 | 의미 | 현장 영향 |
|---|---|---|
| Closed-World 한계 | 학습한 클래스만 인식, 새 객체 등장 시 재학습 필수 | 새 제품 라인 추가될 때마다 수개월의 라벨링·학습 반복 |
| 데이터 병목 | 수작업 라벨링 수개월 소요, 품질 관리 어려움 | PoC가 양산으로 이어지지 못하는 가장 큰 원인 |
| 스케일링 비용 | GPU 클러스터 운영 복잡성, 인프라와 모델 개발 인력 분리 | 자체 학습 시 인프라 운영에만 ML 엔지니어의 절반이 소모 |
→ 슈퍼브에이아이의 선택: AWS 인프라 위에서 이 세 가지 과제를 한 번에 해결하는 풀스택 비전 AI 플랫폼을 구축한다. 그 결과가 바로 '제로(ZERO)' 입니다.
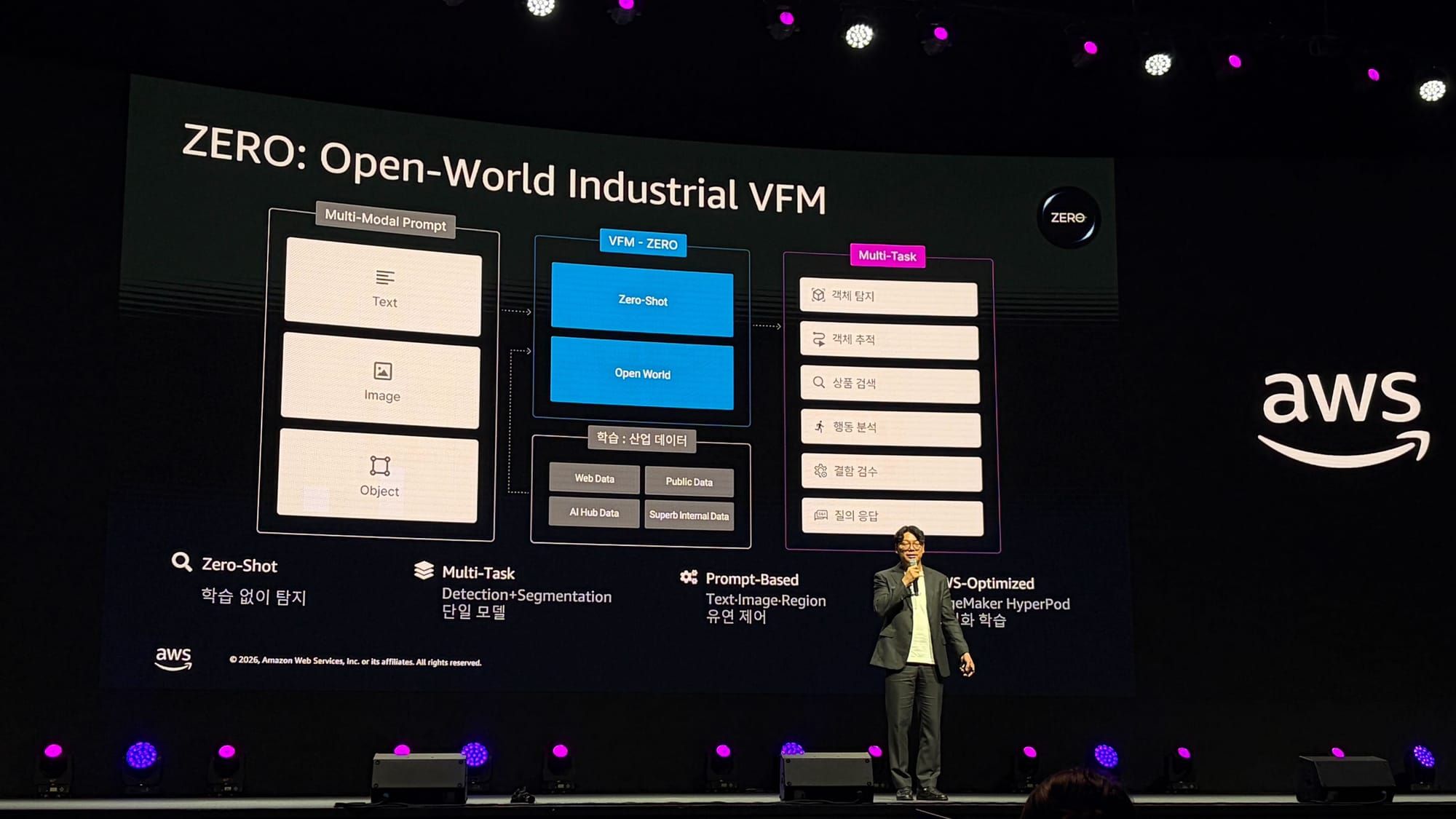
2. ZERO: Open-World Industrial VFM이란
ZERO는 슈퍼브에이아이가 개발한 국내 최초의 산업 특화 비전 파운데이션 모델(Vision Foundation Model, VFM)입니다. 텍스트·이미지·박스 등 다양한 프롬프트를 받아 사전 학습 없이 산업 현장의 객체를 즉시 탐지·추적·분할하는 멀티태스크 모델로, 객체 탐지·세그멘테이션·상품 검색·행동 분석·결함 검수·VQA(질의응답)까지 단일 모델로 처리합니다. SageMaker HyperPod 인프라 위에서 약 8개월에 걸쳐 학습되었습니다.
ZERO의 4가지 핵심 특성
- Zero-Shot: 추가 학습 없이 새 객체·환경에 즉시 적용
- Multi-Task: Detection + Segmentation + Pose + VQA를 단일 모델로
- Prompt-Based: 텍스트 / 이미지 / 영역(Box) 프롬프트로 유연하게 제어
- AWS-Optimized: SageMaker HyperPod에 최적화된 분산 학습 파이프라인으로 학습
3. 학습 아키텍처 한눈에 보기

핵심 구성 요소 (Block-level Specs)
- 컴퓨팅: AWS p5e.48xlarge × 4노드 = NVIDIA H200 × 32장, 노드당 HBM3e 1,128GB
- 네트워킹: EFA(Elastic Fabric Adapter) 3,200 Gbps
- 스토리지: Amazon S3 + Amazon FSx for Lustre (Data Repository 연계)
- 오케스트레이션: Slurm (HyperPod가 관리)
- 모니터링: Amazon CloudWatch (GPU 사용률, 학습 메트릭 알림)
- 운영 효율: 최신 AMI 기본 탑재 (드라이버·OS·Flash Attention 즉시 설치)
4. 핵심 성과: 정량 결과
| 지표 | 수치 | 의미 |
|---|---|---|
| 데이터 효율 | 90만 개 데이터로 글로벌 1위 동등 성능 | 중국 T-Rex2·DINO-X는 2,000만~1억 개 데이터셋 사용 |
| 학습 기간 | 약 8개월 | 글로벌 빅테크 대비 1/3 수준 |
| 학습 비용 | 40% 이상 절감 | Flexible Training Plan + 리허설 분리 전략 |
| 데이터셋 로딩 시간 | 30시간 → 수 분 | HuggingFace Datasets Arrow 사전 변환 |
| 본학습 시작 I/O 대기 | 0초 | FSx Data Repository 프리로드 |
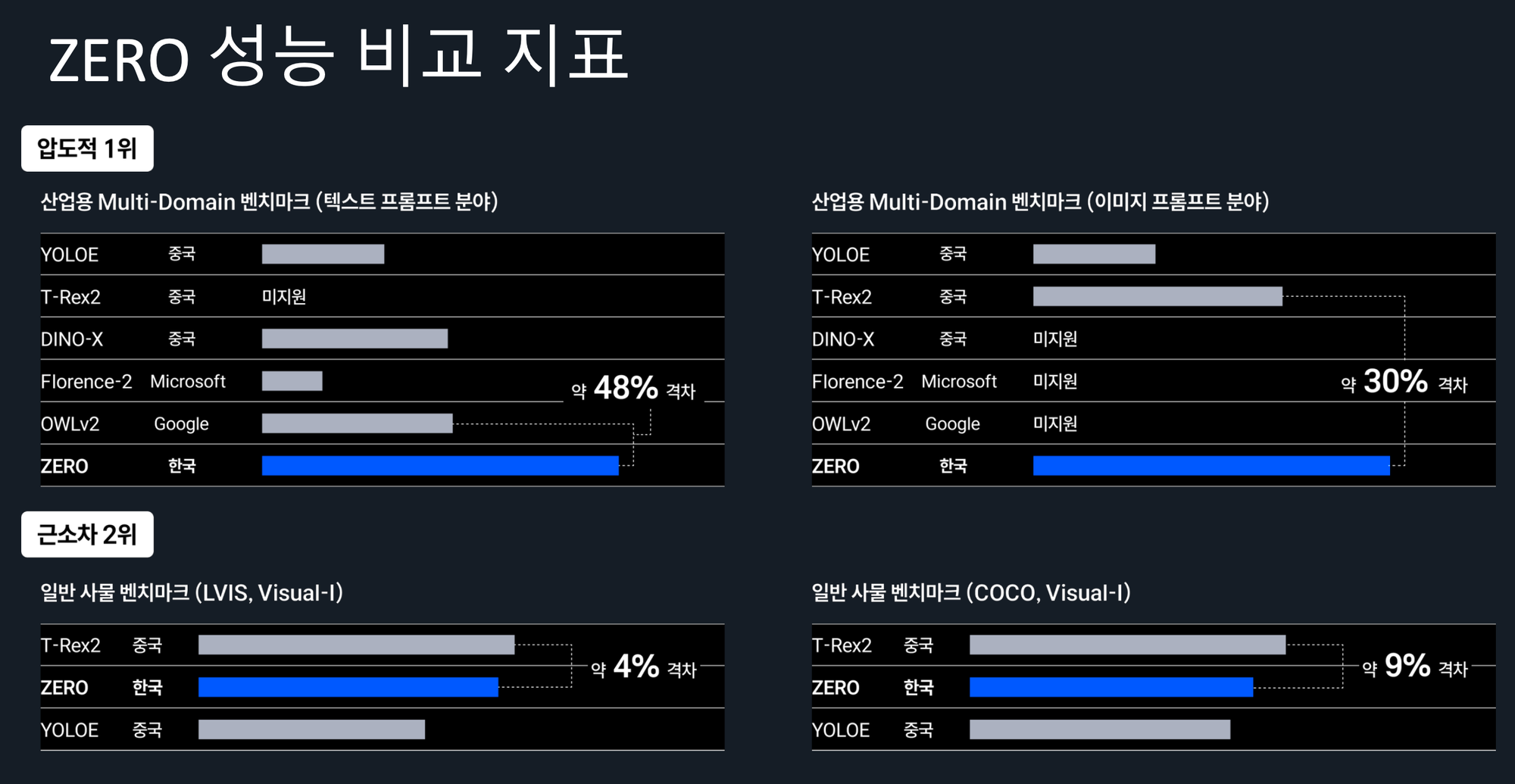
| 산업용 텍스트 프롬프트 벤치마크 | 1위, 2위와 약 48% 격차 | YOLOE·T-Rex2·DINO-X·Florence-2·OWLv2 대비 |
| 산업용 이미지 프롬프트 벤치마크 | 1위, 2위와 약 30% 격차 | 다수 글로벌 경쟁 모델 미지원 |
| LVIS Challenge | 2위 | 1,200+ 카테고리 Open-Vocabulary |
| CVPR 2025 OmniLabel | 2위 | Free-Form Object Detection |

5. AWS 기반 대규모 데이터 파이프라인
10억 장 raw → 400만 장 큐레이션, 4계층 라벨링까지 자동화
ZERO 학습을 위해 슈퍼브에이아이는 10억 장 이상의 raw 이미지를 스캔해 400만 장 이상의 학습 가능 이미지를 큐레이션했습니다. 이 모든 과정은 AWS 서버리스 서비스로 구성된 자동 라벨링 파이프라인이 처리합니다.
각 단계는 Step Functions가 순차적으로 제어하며, 단계별 자동 실행과 에러 핸들링까지 처리합니다.
4-Layer Multi-Layer Data 구조
| 레이어 | 어노테이션 | 용도 |
|---|---|---|
| L1: Detection | Bounding Box + Class | 객체 위치 탐지 |
| L2: Segmentation | Pixel-level Mask | 정밀 영역 분할 |
| L3: Pose | Keypoint Skeleton | 자세·행동 분석 |
| L4: Context/VQA | Scene Understanding | 상황 이해·질의응답 |
이 4계층 구조 덕분에 ZERO는 단일 모델로 객체 탐지부터 시각 질의응답까지 다양한 태스크를 동시에 수행할 수 있습니다.
6. 가장 큰 병목: 데이터 로딩과 그 해결법
문제: FSx · HuggingFace Datasets 메타데이터 병목
400만 장의 학습 이미지를 S3에서 FSx for Lustre로 가져오는 과정에서 두 가지 병목이 동시에 발생했습니다.
- S3 → FSx 메타데이터 동기화에 수십 분 소요
- raw 이미지를 HuggingFace Datasets Arrow 포맷으로 변환하는 데만 30시간 소요
본학습을 시작할 때마다 이 병목이 재발생하면, 비싼 H200 GPU가 데이터 로딩만 기다리며 idle 상태로 남아 있는 시간이 누적됩니다.
해결책 1: Arrow 포맷 사전 변환
HuggingFace Datasets의 Arrow file 포맷으로 데이터셋을 사전에 병합·샤드 관리합니다.
- 400만 장 → 1GB 샤드 약 1,200개로 분할
- 단일 데이터셋 형식으로 병합해 파일시스템 메타데이터 부담 최소화
- HF Datasets가 수 분 내 로드 준비 완료
- raw 상태로 로드 시 발생하는 30시간 변환 과정 제거
해결책 2: S3 → FSx 프리로드
aws cli v2 s3 sync + FSx Data Repository 연계로 I/O 지연을 본학습 이전에 모두 처리합니다.
aws s3 sync로 내부 GPU 서버 회선 최대치 전송- FSx Data Repository에 S3 버킷 등록 (File System Path 매핑이 핵심)
- 리허설 단계에서 lazy → full 복사 트리거로 수 시간 확보
- 본학습 시점에는 FSx 내 데이터가 이미 상주 → I/O 대기 0
FSx for Lustre 경로 매핑이 중요한 이유
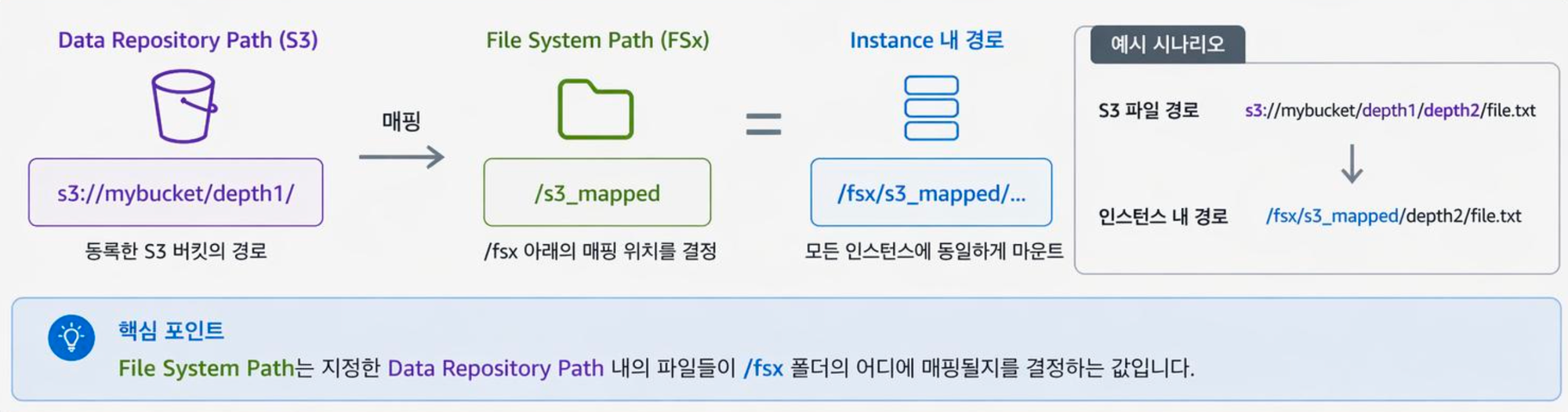
핵심 포인트: File System Path는 지정한 Data Repository Path 내의 파일들이 /fsx 폴더의 어디에 매핑될지를 결정하는 값입니다. 잘못 설정하면 모든 Slurm 노드에서 일관된 경로로 데이터를 참조할 수 없어, 학습 스크립트가 깨집니다.
7. HyperPod 대규모 학습 비용 최적화: Flexible Training Plan (FTP) 활용
핵심 전략: '리허설 → 본학습' 2단계 분리
H200 4노드 클러스터는 시간당 비용이 매우 큽니다. 본학습이 OOM이나 권한 오류로 1시간 만에 멈추면 그만큼 손실이 그대로 누적됩니다. 슈퍼브에이아이는 이 위험을 저렴한 인스턴스로 리허설을 먼저 끝낸 후, FTP 예약 구간에 본학습을 몰아 넣는 방식으로 해결했습니다.
| 단계 | 인스턴스 | 목적 |
|---|---|---|
| Step 1: 리허설 | g6e.8xlarge × 2 (EFA RDMA 지원 최저가) | 멀티노드 트레이닝 스크립트 검증 / FSx로 S3 데이터 사전 로드 / 데이터 무결성 검증 / OOM·권한·체크포인트 버그 사전 해결 |
| Step 2: 본학습 | p5e.48xlarge × 4 (H200 × 32, EFA 3,200Gbps) | 리허설 인스턴스 제거 → provisioning 편집 / Training Plan 노드 추가 + Slurm reconfigure / FSx 데이터 이미 프리로드 완료 → 즉시 학습 / 30분 내 전환, GPU 유휴 시간 최소화 |
AWS Flexible Training Plan (FTP)란
고성능 GPU 클러스터를 짧은 기간(일~주 단위)로 예약하여 확보하는 AWS 옵션입니다. 1년 약정 없이 유연하게 사용할 수 있어, Training Plan 예약 시점에 맞춰 개발·리허설 일정을 거꾸로 설계하는 것이 핵심입니다.
결과
- 학습 기간 30일 → 10일로 단축
- 비용 40%+ 절감
- FSx 프리로드로 수 시간 절약
- 본학습 중단 사고 0건
8. 분산 학습 기술 스택: Slurm + NCCL + Pyxis + HuggingFace Accelerate
ZERO 학습은 단 한 줄의 sbatch 명령으로 4노드 × H200 32장 분산 학습이 트리거됩니다.
핵심 구성
srun --container-image로 컨테이너 기반 멀티노드 실행 (Pyxis 활용)accelerate launch로 PyTorch DDP + NCCL 초기화- 주요 환경 변수:
NCCL_SOCKET_IFNAME=ens,NCCL_ASYNC_ERROR_HANDLING=1,NCCL_DEBUG=INFO,CUDA_DEVICE_MAX_CONNECTIONS=1 - Master Address는 첫 노드(
scontrol show hostnames | head -n 1)로 자동 설정 - Master Port는 30000~50000 사이 랜덤으로 충돌 방지
이 모든 설정이 단일 sbatch 스크립트 안에 정리되어 있어, 본학습 시작 시 별도의 수동 작업이 필요 없습니다.
9. 산업 적용 사례: 이미 현장에서 작동 중인 ZERO
제조: SOP 모니터링과 다품종 제품 관리
- 작업자 행동 분석 + SOP 준수율 자동 평가, 새 공정에 Zero-Shot으로 즉시 적용
- 다품종 생산 라인에서 학습 없이 제품 검출·개수 추적·생산량 추적

영상 분석 플랫폼
- "빨간 모자 쓴 사람"과 같은 자연어 검색으로 CCTV 영상을 즉시 조회
- CCTV 실시간 객체 탐지 + 이상행동 감지

물류·리테일 AI
- 제품 인식 + 재고 관리 + 결함 탐지를 단일 모델로
- Edge 추론으로 실시간 처리
적용 범위
- 37개 주요 산업 분야 (산업·제조 / 해상 / 재난·안전 / 인물·행동 / 도시 보안 / 도로교통 / 항공·위성 / 리테일 / 농업 / 자연·생태계 / 수중 / 건설 / 의료 영상 / 스포츠 / 실내 / 문서 / 음식 외 20개)
- 200종 탐지 대상, 15만 건 탐지 대상 수
10. 자주 묻는 질문 (FAQ)
Q1. ZERO는 추가 학습 없이도 우리 회사 현장에서 바로 정확하게 작동하나요?
A. ZERO는 Zero-Shot으로 설계된 Open-World 비전 파운데이션 모델이라, 텍스트 프롬프트 또는 예시 이미지 1장만으로 새로운 객체를 탐지할 수 있습니다. 슈퍼브에이아이의 산업용 멀티 도메인 벤치마크에서 글로벌 경쟁 모델(YOLOE, T-Rex2, DINO-X, Florence-2, OWLv2) 대비 약 48% 격차의 1위를 기록했습니다. 다만 극단적으로 특수한 결함(미세 크랙 등)이나 도메인 특화 케이스는 슈퍼브 플랫폼의 자동 라벨링 + 파인튜닝을 결합하면 더 안정적인 성능을 확보할 수 있습니다.
Q2. ZERO를 우리 회사 시스템에 연동하려면 얼마나 걸리나요?
A. AWS Marketplace의 1-Click 배포 기능을 사용하면 SageMaker Endpoint가 즉시 생성되어, 표준 HTTPS API로 호출이 가능합니다. PLC·NPU 등 산업용 하드웨어 연동도 API 기반으로 설계되어 있습니다. 일반적인 PoC는 2주 이내에 첫 결과를 확인할 수 있습니다.
Q3. 슈퍼브에이아이는 AWS와 어떤 협력 관계인가요?
A. 슈퍼브에이아이는 2024년 AWS Rising Star Partner (APJ, ISV) 수상, 2025년 12월 AWS와 생성형 AI SCA(전략적 협약) 체결, ISV Accelerate 기반 공동 영업 진행 중입니다. Amazon SageMaker Ready 및 생성형 AI Competency 등 다수의 파트너 컴피턴시 자격을 보유하고 있습니다.
자체 환경에서 ZERO를 테스트해 보거나, HyperPod 기반 학습 인프라 구축을 검토 중이신가요? 아래 내용을 남겨주시면 슈퍼브 전문가들이 바로 현장 진단 컨설팅을 해드리겠습니다.