소형 언어모델(sLLM)이 주목받는 이유 : 가성비와 보안 두 마리 토끼를 잡는 방법


생성형 AI는 지식 노동 패러다임의 변화를 가져올 만한 파괴적인 기술임에 분명하지만, 실제 생성형 AI를 업무에 적극 활용하고 있는 기업은 많지 않다. 글로벌 컨설팅펌 딜로이트의 조사에 따르면 생성형 AI를 대규모로 도입하고 있는 기업은 전체의 13%에 불과했으며, 약 79%에 달하는 회사에서는 여전히 생성형 AI의 도입 여부를 평가/실험하는 단계에 있거나 일부 업무에만 제한적으로 도입 중인 것으로 나타났다.
그렇다면 생성형 AI의 무궁무진한 잠재력에도 불구하고 이처럼 실전 도입이 저조한 이유는 무엇일까? 바로 생성형 AI 사용에 막대한 양의 컴퓨팅 리소스와 자금이 들어가고, 사용 시 보안에 대한 위협이 여전히 존재한다는 한계 때문이다.
1. 치열한 빅테크의 sLLM 경쟁
최근 생성형 AI 업계에서는 이러한 기존 초거대언어모델(LLM)의 한계를 극복하기 위해 보다 적은 컴퓨팅 리소스로 구동이 가능한 소형 LLM 즉 sLLM(small Large Language Model) 개발 경쟁이 치열하다. 우선 LLaMA 시리즈로 일찍이 오픈 소스 기반 생성형 AI의 물꼬를 튼 Meta AI에서는 올해 4월 챗봇 제작에 특화된 모델을 포함한 LLaMA-3의 출시를 발표했다.
OpenAI와 함께 다양한 생성형 AI 서비스를 제공하고 있는 MS 역시 이번 달 파이-3 미니를 출시하였다. GPT-3.0 이후 자사 모델의 철저한 ‘비공개’ 원칙을 지키고 있는 OpenAI사의 동맹인 MS가 보여주고 있는 이러한 행보는 sLLM에 대한 대중들의 관심을 반영한다.
더 이상 ‘비공개’ 원칙 만으로는 다양한 고객사의 니즈를 만족시키기 어렵다. 아무리 성능이 좋은 LLM이라도 고객이 자유롭게 활용할 수 없으면 무용지물이기 때문이다. 이러한 ‘오픈 소스’ 트렌드에 맞추어 구글과 네이버 역시 보다 쉽게 미세조정(fine-tuning)이 가능한 소형 언어 모델 시리즈를 출시하고 있다.

이처럼 sLLM이 주목받고 있는 이유는 이것이 생성형 AI 활용의 도입 비용 절감뿐만 아니라 보안 이슈까지 해결해 줄 수 있는 일석이조의 효과를 가져다줄 수 있기 때문이다.
1) 적은 리소스와 비용
LLM의 한계는 명확하다. 대당 약 4천만 원의 투자가 필요한 NVIDIA A100 GPU가 최소 1만 장 필요하며, 이는 단순 계산으로도 조 단위의 투자가 필요하다는 이야기가 된다. 또한 챗 GPT 서비스의 기반이 되는 기초 모델 GPT-4는 하루 운영비로만 9억 원가량이 필요한 것으로 알려져 있다.
반면에 Meta AI의 LLaMA를 기반으로 한 Alpaca 모델의 경우 단돈 500달러로 훈련이 가능하다. 또한 마찬가지로 LLaMA를 기반으로 개발된 Vicuna 모델의 경우 300달러라는 파격적인 금액으로 미세조정(Fine-tuning)이 가능하다. Vicuna의 또 다른 파생모델인 MiniGPT-4의 경우 전체 학습 과정을 완료하는데 단 4개의 A100 (80GB) GPU로 10 시간 정도밖에 걸리지 않았다. 이처럼 다양한 sLLM 모델의 활용으로 많은 기업들이 저렴한 가격에 sLLM을 도입할 수 있을 것으로 기대된다.
2) 보안 강화
LLM은 본질적으로 보안에 취약하다. 개인정보위원회에 따르면 작년 한국인 ChatGPT 이용자 687명의 개인정보가 유출된 것이 확인되었다고 한다. 삼성그룹 역시 자사 민감정보 유출 등을 이유로 직원들의 ChatGPT 등 외부 생성형 AI 사용을 전면 금지하고 있으며, 자체 언어 모델인 Samsung Gauss를 구축하여 사용하고 있다.
근본적인 정보 유출 방지를 위해서는 API 등 외부 네트워크로부터 원천 차단된 환경을 구축하는 것이 중요하다. 이때 sLLM의 강점이 또 한 번 발휘된다. 오픈소스 기반의 sLLM은 생성형 AI 훈련(training) 및 추론(inference)을 위해 인터넷이 연결되지 않는 네트워크와 완전히 분리된 온프레미스(on-premise) 서버를 자체적으로 구축하고, 확보한 데이터를 활용해 직접 자사 업무에 특화된 생성형 AI를 구축하여 사내 데이터가 외부로 새어나가는 가능성을 원천 봉쇄할 수 있기 때문이다.
2. sLLM의 한계점
그러나 sLLM에도 한계점은 존재한다. 보다 적은 컴퓨팅 리소스를 기반으로 구동되는 만큼 결과물의 퀄리티가 떨어질 수 있다. 특히 부족한 한국어 이해력 및 추론 능력 보완은 sLLM 확산을 위해 꼭 해결해야 하는 부분이다.
1) 부족한 한국어 성능
sLLM의 고질적인 문제로 한국어 질문에 대한 인식과 답변을 제대로 하지 못한다는 점을 들 수 있다. 예를 들어 LLaMA2는 기존 오픈소스 LLM에 비해 한국어를 가장 잘하는 것으로 알려져 있지만 여전히 GPT-4와 비교하면 성능이 현저히 떨어진다.
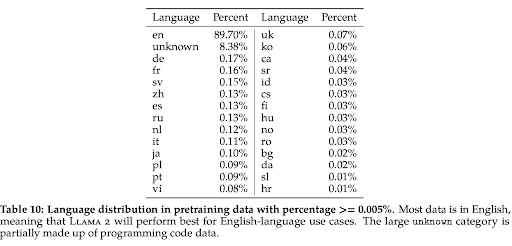
이는 LLaMA2에 활용된 언어별 훈련 데이터의 분포를 보면 명확해진다. 훈련 데이터의 무려 89.7%가 영어인 반면에, 한국어는 고작 0.06%에 불과한 것을 알 수 있다. 최근에는 NIA(한국 정보화진흥원)과 스타트업 업스테이지가 '한국어 리더보드'를 공동 개설해 운영하는 등 한국어 데이터셋 확보를 통한 한국어 특화 LLM의 개발을 촉진하는 등 다양한 시도들이 계속되고 있다.
2) 부족한 언어 능력과 추론 능력
LLM의 추론 능력은 방대한 양의 매개변수(parameter)에서 비롯되는 것으로 추측되고 있다. 따라서 LLM에 비해 수백 분의 일에서 수십분의 일 정도의 매개변수 수를 가진 sLLM은 기존의 LLM에 비해 성능이 떨어지는 것은 물론이고, 추론 능력까지 부족한 경우가 많다.
예를 들어 GPT-4.0을 사용해 보면 GPT-3.5에 비해서 확실히 똑똑하다고 느낀다. 이는 이전 시리즈와는 다르게 GPT-4는 놀랍게도 어느 정도 창발 능력을 가지고 있는 것처럼 보이기 때문이다. OpenAI 측은 GPT-4가 각종 시험에서 “인간 수준의 능력을 보여줬다”라고 주장한다. 실제로 GPT-4가 미국 모의 변호사 시험과 미국의 수학 능력 시험 격인 SAT에서 상위 10%에 해당하는 성적을 거둔 것도 사실이다. 앞으로 sLLM이 더욱 적은 매개변수로 LLM 수준의 성능과 추론 능력을 구현해 내기 위한 연구가 활발히 이루어질 것으로 보인다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.