[VFM 개념] 기본 용어 사전
비전 파운데이션 모델(VFM) 관련 기본 용어들을 정리한 가이드입니다. VFM은 제로샷 학습과 멀티모달 프롬프트를 통해 기업의 AI 도입 비용을 획기적으로 줄이는 차세대 시각 AI 기술입니다. 기존 AI가 특정 작업만 수행했다면, VFM은 이미지 분류부터 객체 탐지까지 모든 시각 작업을 하나의 모델로 통합 처리합니다. 새로운 객체나 상황에도 추가 학습 없이 즉시 대응 가능한 개방집합 시스템으로, 제조업부터 헬스케어까지 다양한 산업 현장에서 인간 수준의 시각 이해 능력을 구현할 수 있습니다.

![[VFM 개념] 기본 용어 사전](/content/images/size/w2000/2025/07/blog_ZERO_VFM------------------------------------------------_-2000x1125-.jpg)
비전 파운데이션 모델(Vision Foundation Model, VFM)
- 비전 파운데이션 모델은 대규모 데이터셋으로 사전 학습(pre-trained)되어 다양한 시각 AI 작업을 수행할 수 있는 범용 인공지능 모델입니다. 기존 비전 AI가 이미지 분류, 객체 탐지 등 특정 작업만을 위해 각각 개발되었다면, VFM은 이 모든 것을 하나의 모델에서 통합적으로 처리합니다.
- VFM의 핵심은 미리 학습이 되지 않은 처음 보는 대상에 대해서도 추론할 수 있는 '제로샷' 능력과 텍스트, 이미지 등 다양한 방식으로 소통하는 '멀티모달 프롬프트' 기능입니다. 이를 통해 기업은 막대한 데이터 구축과 모델 재학습 없이도 신제품이나 예상치 못한 상황에 즉시 AI를 적용할 수 있게 되어, 도입 비용을 획기적으로 줄이고 시장 변화에 민첩하게 대응할 수 있습니다.
제로샷 (Zero-Shot)
- 제로샷은 AI 모델이 훈련 과정에서 한 번도 명시적으로 학습하지 않은 새로운 객체나 카테고리에 대해서도 추론을 수행할 수 있는 능력입니다. 이는 기존의 '미리 정해진 답만 아는 AI'의 한계를 뛰어넘는 기술로, 모델이 사전 학습된 방대한 지식을 바탕으로 새로운 상황에 즉시 일반화하여 대응할 수 있게 합니다. 기업 입장에서는 새로운 비즈니스 요구사항이나 시장 변화가 발생했을 때, 추가적인 데이터 수집, 라벨링, 모델 재훈련 과정 없이도 바로 AI 시스템을 적용할 수 있어 개발 시간과 비용을 획기적으로 절감할 수 있는 핵심적인 기술입니다.
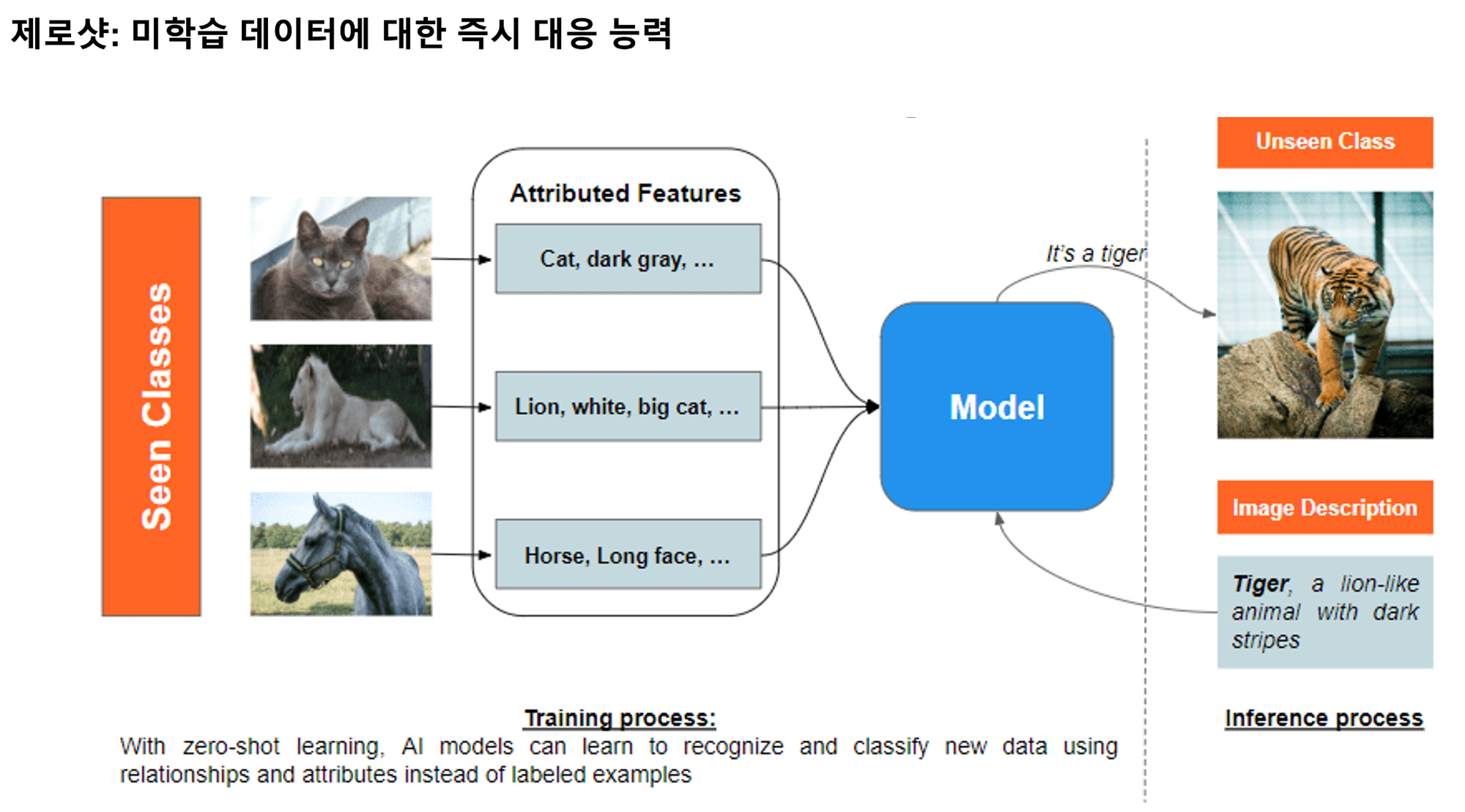
폐쇄집합 (Closed-set)과 개방집합 (Open-set) 시스템
- 기존 AI 시스템은 주로 폐쇄집합(Closed-set) 패러다임을 따릅니다. 이는 AI가 훈련 단계에서 미리 정의된 고정된 라벨 집합(예: 1,000개의 특정 객체 카테고리) 내에서만 분류나 탐지를 수행할 수 있다는 의미입니다. 반면, 개방집합(Open-set) 시스템은 이러한 한계를 넘어 자연어로 표현할 수 있는 모든 개념을 이해하고 처리할 수 있습니다. 모델이 고정된 분류 체계에서 벗어나 인간의 자연어 표현을 직접 이해할 수 있게 되면서, 사실상 무제한의 새로운 객체나 상황에 유연하게 대응할 수 있는 능력을 갖추게 됩니다.
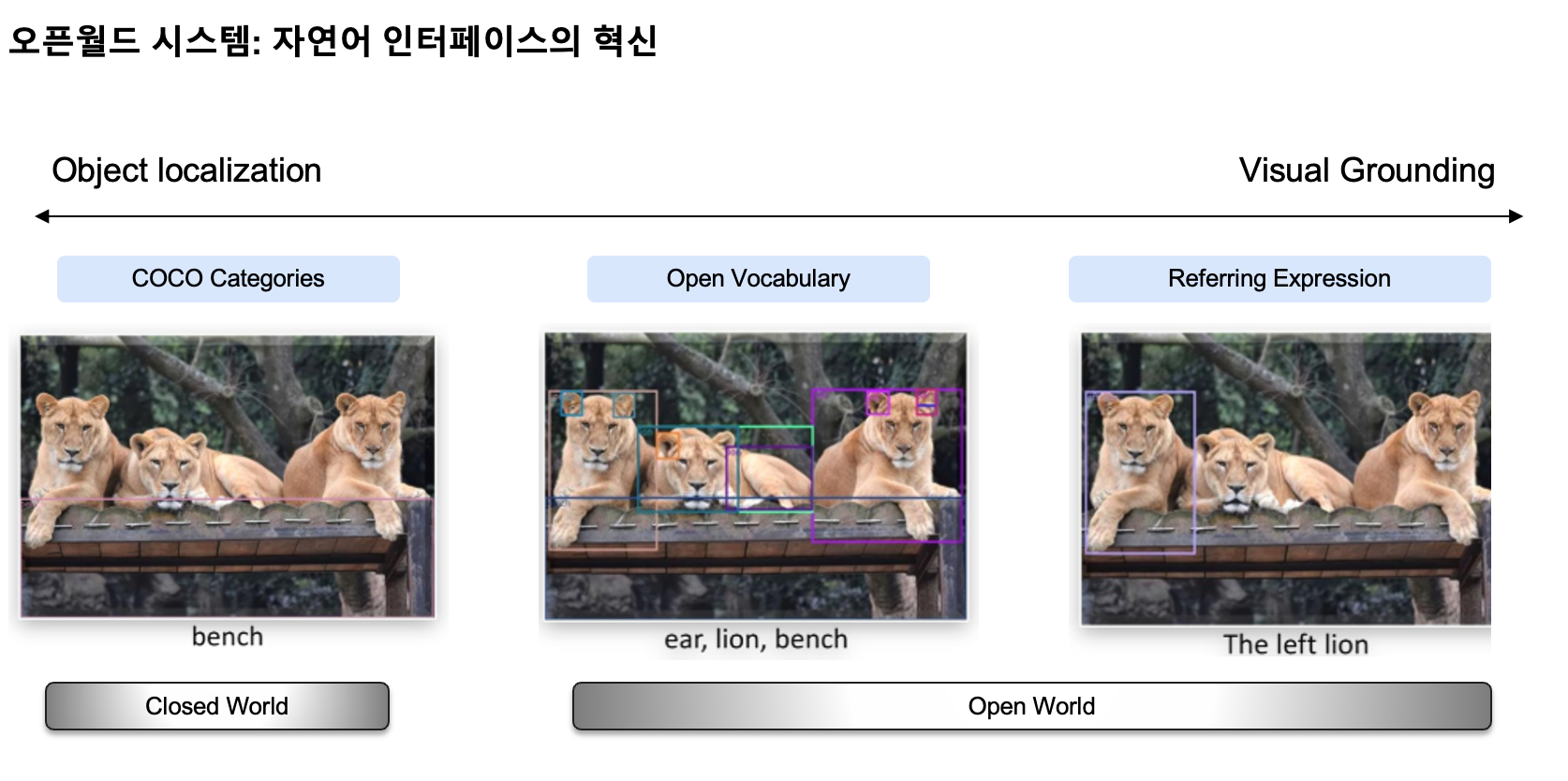
비주얼 그라운딩 (Visual Grounding)
- 비주얼 그라운딩은 AI가 자연어 설명을 바탕으로 이미지 내의 특정 위치나 영역을 정확하게 식별하는 기술입니다. 이는 단순한 이미지 분류나 객체 탐지를 넘어, '손상된 박스' 또는 '미세한 스크래치'처럼 구체적인 언어 지시를 이해하고 이미지 내에서 해당 대상을 찾아내는 능력을 의미합니다. 이 기술을 통해 AI는 인간의 복잡하고 섬세한 지시를 시각적으로 이해하고 실행할 수 있게 되어, 품질 관리, 재고 관리, 보안 모니터링 등 다양한 산업 현장에서 인간 수준의 상황 이해 능력을 구현할 수 있습니다.
멀티모달 프롬프트 (Multi Modal Prompt)
- 기존의 AI는 텍스트 명령에만 반응하는 '정적 모델'이었지만, 멀티모달 프롬프트로는 텍스트뿐만 아니라 이미지, 클릭, 스케치 등 다양한 형태의 '프롬프트'를 제공하여 AI에 복잡하고 세밀한 의도를 전달할 수 있습니다. 원하는 객체를 그림으로 그리거나, 이미지 특정 부분을 클릭하여 AI에게 작업을 지시할 수 있습니다. 사용자 의도를 더 정확하고 직관적으로 파악하고 실제 환경에서의 적용 가능성을 크게 높였습니다.
VLM (Vision-Language Model) vs. VFM (Vision Foundation Model)
- VLM (비전-언어 모델)은 이미지와 텍스트를 함께 이해하고 처리하는 데 특화된 AI 모델입니다. '이미지 캡셔닝'이나 '시각적 질의응답(VQA)'처럼 시각 정보와 언어 정보를 연결하는 특정 작업에 강점을 가집니다.
- VFM (비전 파운데이션 모델)은 VLM의 능력을 포함하면서도, 시각적 AI의 모든 것을 아우르는 범용 AI 에이전트를 지향합니다. 이는 단순히 여러 기능을 합치는 것을 넘어, 분류, 탐지, 분할 등 다양한 시각 작업을 통합적으로 처리합니다.
LVIS (Large Vocabulary Instance Segmentation) 데이터셋
- AI 모델의 현실 세계 적용 능력을 검증하기 위해 메타(Meta) AI Research가 공개한 대규모 데이터셋입니다. 기존 데이터셋의 통제된 환경 한계를 넘어, 현실의 '롱테일 분포'를 의도적으로 모방하여 희귀 객체까지 학습하고 인식하도록 설계되었습니다. 160만 개 이상의 이미지와 1,200개 이상의 방대한 객체 카테고리를 포함하며, 픽셀 단위의 정교한 '인스턴스 분할' 정보를 제공합니다. LVIS는 AI 모델이 실제 산업 현장의 복잡하고 예측 불가능한 환경에서도 뛰어난 성능을 발휘하는지 측정하는 현실적인 시험대 역할을 합니다.
- [주요 성능 평가 지표]
- Text-G AP(Generic Text Prompting Average Precision): 모델이 벤치마크의 모든 카테고리 이름을 텍스트 프롬프트로 받아 제로샷 객체 탐지를 수행하는 능력. "사람", "자동차", "고양이" 같은 카테고리 이름들이 텍스트 프롬프트로 입력되면, 모델이 전체 이미지 속에서 해당 객체들을 탐지
- Visual-G AP(Generic): 모델이 훈련 데이터의 모든 카테고리의 시각적 프롬프트를 받아 전체 이미지에서 제로샷 객체 탐지를 수행하는 능력
- Visual-I AP(Interactive): 상호작용적 시각적 프롬프트를 통한 객체 탐지 성능. 테스트 이미지 내에 GT 박스 (Ground Truth Box, 사람이 직접 라벨링한 객체)를 직접 시각적 프롬프트로 사용해 이미지 안의 같은 카테고리의 다른 객체들을 탐지
- Visual-G와 Visual-I와의 차이점Visual-G: "훈련 데이터에서 일반적인 고양이 모습중 하나를 선택하여, 전체 이미지에서 고양이를 찾아라"Visual-I: "이 이미지 안의 실제 고양이 하나를 보고, 같은 이미지에서 다른 고양이들을 찾아라"
- Max AP(Maximum Average Precision): Text AP와 Visual AP 중에서 더 높은 값, 또는 두 정보를 모두 활용했을 때 얻을 수 있는 최대 AP. 모델이 텍스트와 시각적 정보를 통합하여 얻을 수 있는 잠재적 최대 성능 지표
멀티 도메인 데이터셋(Multi-Domain Dataset)
- 슈퍼브에이아이가 데이터 중심 AI 철학 하에 자체 구축한 산업 특화 데이터셋. 리테일, 게임, 의료, 자율 주행 등 17개 산업군의 데이터로 구성되어 있습니다.
롱테일 분포 (Long-tail Distribution)
- 현실 세계 데이터에서 나타나는 극심한 불균형을 설명하는 개념입니다. 이는 소수의 객체나 현상이 매우 자주 등장(빈번)하는 반면, 압도적으로 많은 수의 다른 객체나 현상은 드물게(희귀하게) 나타나는 현상을 말합니다. 예를 들어, 공장 라인에서 특정 불량품은 드물게 발생하지만 그 중요성은 매우 큽니다. 기존 AI 모델은 이 '긴 꼬리'에 해당하는 희귀 데이터를 학습할 기회가 부족하여 현실 적용에 한계가 있었습니다. 롱테일 분포에 대한 이해는 실제 산업 현장에 AI를 성공적으로 도입하는 데 필수적입니다.
CVPR (Conference on Computer Vision and Pattern Recognition)
- CVPR (컴퓨터 비전 및 패턴 인식 학회, Conference on Computer Vision and Pattern Recognition)는 최대 규모의 권위 있는 비전 AI 국제 학회입니다. 이미지 인식, 객체 탐지, 비디오 분석, 3D 비전 등 컴퓨터 비전 전반의 혁신적인 연구 결과와 새로운 기술들이 발표됩니다.
- 이 학회는 자율주행, 로봇, 스마트 팩토리, 헬스케어 등 다양한 분야에서 비전 AI가 어떤 혁신을 가져올지 미리 엿볼 수 있는 핵심 창구라 할 수 있습니다. 매년 발표되는 논문과 챌린지 결과는 해당 연도의 기술 표준을 제시하며, 향후 AI 시장과 기술 발전에 지대한 영향을 미칩니다.
개별 객체 탐지 챌린지(Object Instance Detection Challenge)
- 기존 객체 탐지가 미리 정의된 클래스(예: 볼트)에 속하는 모든 객체를 찾아내는 것이라면개별 객체 탐지 챌린지는 "M8 × 20mm 스테인리스 육각 볼트"와 같이 특정 객체 인스턴스를 찾아내는 능력을 중점적으로 평가합니다.
- 예측 불가능하고 복잡한 환경에서 로봇과 AI가 특정 물체를 정확히 인식하고 작동하는 데 필수적인 핵심 기술입니다. 참가자들은 테스트 환경 이미지로 학습할 수 없는 엄격한 제약 속에서 모델의 일반화 능력을 증명해야 합니다.
CVPR 2025 개별 객체 탐지 챌린지: 산업 현장을 위한 실용적 AI 기술의 진화
CVPR 2025 개별 객체 탐지 챌린지(Object Instance Detection Challenge)는 실제 산업 현장에서 바로 활용할 수 있는 실용적 AI 기술을 다룹니다. 기존 객체 탐지와 다른 산업 특화 AI 기술의 핵심과 실제 적용 사례를 자세히 알아보세요.

파운데이션 퓨샷 객체 탐지 챌린지(Foundation Few-Shot Object Detection Challenge)
- AI가 인간처럼 적은 예시만으로도 새로운 개념을 학습하고 즉시 활용할 수 있는지를 평가합니다. 기존 AI가 막대한 데이터 수집과 긴 학습 시간으로 인해 산업 현장 적용에 한계가 있었다면, 이 챌린지는 단 10개 내외의 적은 이미지와 텍스트 설명만으로도 새로운 객체를 인식하는 능력을 검증합니다.
- 챌린지 참가자들은 실제 산업 현장과 유사한 데이터셋과 제약 조건 속에서, AI 모델의 학습 효율성과 산업 적용 가능성을 증명해야 합니다. 이 챌린지는 데이터 의존성을 극복하여 AI가 더 넓은 산업 분야에 신속하게 확산될 수 있는 가능성을 보여줍니다.
CVPR 2025 파운데이션 퓨샷 객체 탐지 챌린지: 산업을 AI로 바꾸는 미래
CVPR 2025 파운데이션 퓨샷 객체 탐지 챌린지는 실제 산업 현장에서 즉시 활용 가능한 AI를 평가합니다. 기존 대비 90% 이상 데이터 수집 비용을 절감하면서 제조업, 헬스케어, 농업 등 다양한 산업 현장에서 사용할 수 있는 AI 기술을 검증하는데요. 적은 수의 이미지로 새로운 객체를 학습하는 퓨샷 기술로 산업 AI 도입 장벽이 낮아지고 있습니다.

💡
슈퍼브에이아이의 비전 파운데이션 모델 '제로'는 아래 AWS 마켓플레이스에서 바로 사용하실 수 있습니다.
AWS Marketplace: ZERO - Zero-shot Object Detection
