영어 훈련 데이터로 비영어 자연어 처리 모델 훈련 시키기


안녕하세요! 저는 하버드 대학교에서 컴퓨터 사이언스를 전공 중인 3학년 홍찬의(Channy Hong)입니다. 지난 여름, 저는 YC가 지원하는 스타트업인 슈퍼브에이아이에서 이재연 멘토님과 이정권 슈퍼바이저님과 함께 자연어 처리(NLP) 연구라는 소중한 기회를 얻었습니다. 저는 이 인턴 경험을 통해 "제로샷 교차 언어 전이를 위한 문장 임베딩 기반 비지도 중간 언어 의미 표현 방법(Unsupervised Interlingual Semantic Representations from Sentence Embeddings for Zero-Shot Cross-Lingual Transfer)"이라는 연구 논문을 완성해 인공지능 발전 협회(Association for the Advancement of Artificial Intelligence, AAAI)에 제출하는 뜻깊은 결과를 얻었습니다. 이 논문으로 핵심 테크니컬 프로그램의 발표자로 선정되는 놀라운 기회를 얻었는데요, 이 블로그를 통해 제 논문과 작업 전반에 대해 소개하고자 합니다.
연구 동기. 바로 시작해 보겠습니다. 오늘날 대부분의 NLP 연구가 영어로 수행되기 때문에, 비영어권 언어는 훈련 모델에 사용할만한 라벨링된 데이터셋이 없는 것이 일반적입니다. NLP 모델을 통합하는 실용적인 프로그램(application)에 대한 수요는 모든 언어에 존재하지만, 현실적인 여건이 받쳐주지 못하기 때문에 비영어권 언어로 최첨단 과제 해결 모델을 재현하는 데 커다란 어려움이 있습니다.
자연어 추론. '전제(Premise)’ 문장이 주어졌을 때 '가설(Hypothesis)' 문장을 분석하는 프로그램이 있다고 가정해보겠습니다. 아마도 이 분석은 전제 문장과 가설 문장 간의 의미적 관계를 바탕으로 가설 문장을 '참(entailment)', '중립(neutral)', '거짓(contradiction)' 중 하나로 분류하도록 구성되어 있을 것입니다. 이는 자연어 추론(Natural Language Inference, NLI) 작업의 기본 형태이며, BERT, XLNet과 같은 언어 인코더의 성능 벤치마킹에 일반적으로 활용됩니다.
참, 중립, 거짓이라는 세 가지 분류의 차이점을 설명하는 것이 가장 쉽게 이해하는 방법이겠네요.
거짓: 만약 "한 남자"가 "동아시아 한 국가의 주요 인물의 제복을 검사하는 중"이라면(전제), 필연적으로 "그 남자"는 현재 "잠자는 중"일 수가 없겠죠(가설). 따라서 두 문장 간의 관계는 거짓입니다.
참: "여러 명의 남성이 뛰는 중인 축구 경기"가 있다면(전제), 필연적으로 "어떤 남자들은 스포츠를 하는 중"일 겁니다.(가설) 따라서 두 문장 간의 관계는 참이 됩니다.
중립: "나이 든 남자와 젊은 남자가 웃고 있다"면(전제), "두 남자가 바닥에서 놀고 있는 고양이를 보고 미소 지으며 웃고 있는지"는(가설) 확신할 수 없습니다. 따라서 두 문장 간의 관계는 중립입니다.
NLI는 문장의 실제 의미를 완벽하게 이해해야하는 고난도의 작업입니다. 특정 키워드를 선별하는 것 만으로도 만족스러운 결과를 얻을 수 있는 감정 분석 작업과는 차원이 다르죠.
분류기(Classifier). 이제 NLI 과제를 해결하는 모델 개발에 대해 생각해볼까요? 각각의 예시가 전제 문장, 가설 문장 및 올바른 라벨로 구성되어있는 훈련 데이터의 양이 충분하다면, Google의 BERT와 같은 널리 알려진 인코더로 전제 문장과 가설 문장에 대해 임베딩과 같은 의미적으로 풍부한 벡터 형태의 표현을 생성할 수 있습니다. 그 후 신경망에 (연결된) 산출물을 투입해 지속적으로 업데이트(훈련 등)를 통해 두 문장 사이의 관계를 '판별'해, 참/거짓/중립 중 올바른 답을 출력할 수 있도록 하는 것입니다.
다시 말하지만, 고성능의 영어 NLI 작업용 신경망을 훈련하는 것은 꽤 쉬운 일입니다. 이미 충분한 양의 훈련 데이터가 존재하기 때문입니다. 특히 각각 57만개와 39만개의 훈련용 예시를 보유한 SNLI와 MNLI 데이터셋의 활용도 가능합니다. 본 연구는 MNLI 데이터셋을 활용했고, bert-as-a-service 라이브러리의 기본 설정을 사용해 문장 스트링을 768차원의 임베딩으로 변환해, 전제와 가설이 연결된 임베딩을 우리의 믿음직스러운 분류기 신경망에 투입했습니다. 이 신경망은 768 사이즈의 숨겨진 단일 레이어로 구성되어 3방향 신뢰 점수를 출력합니다.
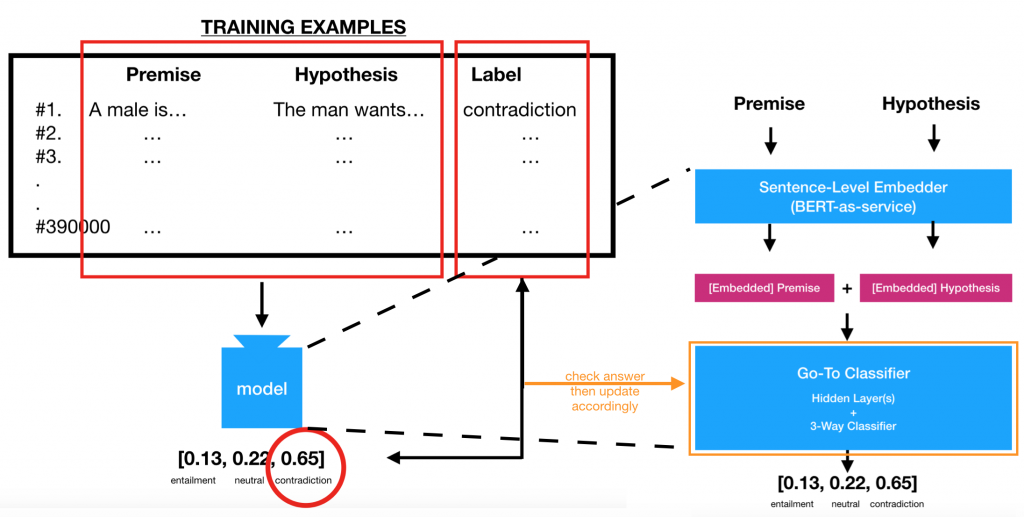
분류기는 MNLI 작업에서 63.8%의 정확도를 보여줍니다. 이 정확도는 테스트를 진행한 MNLI 데이터셋 속 5,000개 예시 중 올바른 예측의 수를 세어 계산된 수치입니다. 5,000개라는 충분한 양의 훈련용 예시로 분류기 신경망을 훈련시켰기 때문에, 약 3,200개에 해당하는 63.8%라는 정확도는 우리가 달성해야 하는 최소한의 기준선입니다.
XNLI. 자, 만약 영어가 아닌 언어의 NLI 작업이 주어지면 어떨까요? 뉴욕대의 교차 언어 NLI(XNLI) 말뭉치팀에게서 14개의 비영어권 언어에 대한 방대한 자료를 제공받았는데, 각 언어별로 MNLI의 영어 버전에서 수동으로 번역된 2,500개의 개발용 예시와 5,000개의 테스트용 예시를 포함하고 있었습니다. 가장 쉬운 방법은 원하는 언어의 훈련용 예시를 영어처럼 수 천 개씩 다운받아 분류기를 훈련하는 것이겠지만, 훈련용 예시가 존재하지 않기 때문에 그럴 수는 없었습니다. 흠…
번역-훈련. 그렇다면, 영어 MNLI의 훈련용 예시를 구글 번역기로 우리가 원하는 언어로 번역해서 분류기 모델을 훈련시키는 것은 어떨까요? 분명히 가능할 것 같았습니다. 마침 XNLI 팀도 39만개의 영어로 된 훈련용 예시의 “신경망 기계 번역” 버전(445MB)을 배포했고요. 물론, 14개의 비영어 언어들로 말이죠.
작업을 위해 스페인어, 독일어, 중국어 및 아랍어를 타겟 언어로 선택했습니다. 스페인어와 독일어는 언어학적으로 영어와 가깝고, 중국어와 아랍어는 멀리 떨어져있죠. bert-as-service 라이브러리를 활용하면 이 번역-훈련 패러다임에서 아래와 같은 정확도를 달성할 수 있습니다. 참고로 다국어 BERT(BERT-multilingual)는 영어와 위 4개 언어를 포함해 총 104개 언어의 문장 스트링을 벡터 형태로 표현할 수 있습니다.

신경망 기계 번역 시스템(Neural Machine Translation, NMT)은 의미적으로 동일한 문장을 쌍으로 묶은 방대한 양의 영어 병렬 데이터를 자체 학습에 사용했습니다. 예를 들어, 배가 고프다는 뜻인 영어의 “I am hungry”라는 문장과 프랑스어의 “J’ai faim”이라는 문장이 쌍을 이루는 것과 같이요. 그러나 우르두어, 폴란드어, 타밀어와 같은 소수 언어의 경우 영어 병렬 데이터셋은 양과 질 모두에서 부족했던 반면, 위키피디아 덤프와 같은 단일 언어 말뭉치는 매우 잘 갖추어져 있었습니다.
물론 성경이나 코란 같이 널리 번역된 텍스트나 오픈 서브타이틀(OpenSubtitle)과 같은 프로젝트처럼 병렬 데이터를 얻을 수 있는 몇 가지 방법이 존재하기는 하지만, 이런 방법을 통해 축적된 데이터셋은 각 언어의 다양한 표현 방식을 모두 포함하지 못합니다. 데이터셋에 포함되는 표현이 대부분 대화나 과하게 고풍스러운 표현 등에 한정되어 의도치 않게 번역 품질에 악영향을 미치게 됩니다. 따라서 위 표는 우리가 낙관적으로 정해놓은 모델 성능의 또다른 기준선입니다. “고품질의 병렬 데이터를 충분히 사용하면 이 정도 까지 달성할 수 있습니다. 이 4개의 주요 언어에 대해서는 충분한 양의 영어 병렬 데이터를 구할 수 있기 때문이죠."
언어 간 의미 표상. 좋아요, 하지만 훈련용 예시를 영어에서 타겟 언어로 번역하는 대신, 그것들을 먼저 특정 언어의 구조와 특징에서 자유로운 어떠한 의미 표상으로 “번역”한 뒤에, 다시 타겟 언어로 “번역”하면 어떨까요? 일단 우리에게 이러한 중간적 표상이 원문의 의미 정보를 잃지 않고 의미적으로 전이적이라는 것에 대한 충분한 확신이 있다면, 도착 언어로 일일이 번역하는 대신 분류기를 훈련시키면 되는겁니다.
분류기 신경망의 역할이 영어 문장 임베딩의 특정한 의미적 특징을 포착하는 것이기 때문에, 이건 충분히 실현 가능한 발상입니다. 따라서, 문장을 특정 언어에만 구애받지 않으면서(interlingual) 의미적으로 풍부한 벡터 형태로 만들 수 있다면, 성능 좋은 분류기는 여전히 그 안에 인코딩된 의미 정보를 파악할 수 있을 것입니다. 다소 추상적인 이 접근법의 이점은, 더 이상 영어를 사실상의 출발 언어로 가정하지 않아도 된다는 것입니다. 여러 언어의 훈련용 데이터를 동시에 활용할 수 있는 일반적인 프레임워크가 있다면 얼마나 유용할까요? 아마도 미래에는 영어로 된 훈련용 데이터에 의존하지 않아도 되는 때가 올겁니다.
물론, 이 훌륭한 아이디어의 진짜 도전은 따로 있습니다. 바로 (BERT가 생성한 것과 같은) 문장 임베딩을 언어 간 의미 표상(Interlingual Semantic Representation, ISR)으로 “인코딩” 해 분류기를 훈련시킬 수 있는 인코더를 만드는 일이죠. 우리가 원하는 분류기 훈련 패러다임은 아래와 같은 모습입니다.
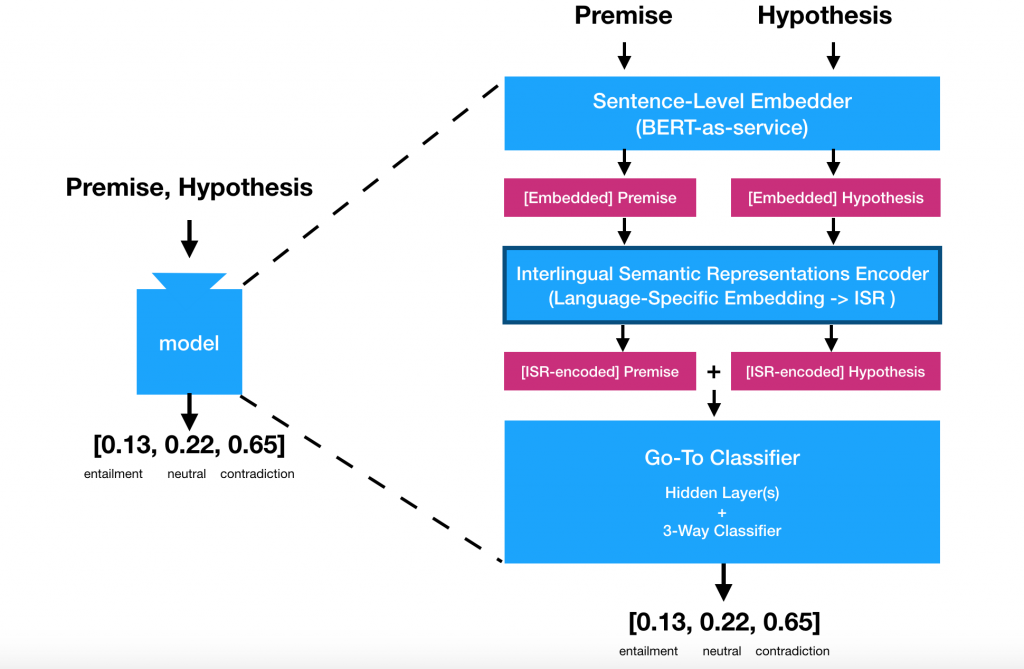
ISR 인코더. 자, 이제 ISR 인코더와 그 훈련을 준비해볼까요? 우리의 ISR은 문장의 의미 표상을 생성해야 하는 특정한 임무가 있기 때문에, 앞서 언급한 “I am hungry”라는 영어 문장과 “J’ai faim”이라는 프랑스어 문장을 투입했을 때, 근위, 즉 비슷한 위치의 ISR 임베딩을 출력해야 합니다. 왜냐하면 두 문장은 근위 의미 정보를 내포하기 때문이죠.
번역-훈련이라는 우리의 아이디어에 기반해, 이를 가능케 하는 한 가지 방법은 대량의 병렬 데이터를 활용해 서로 다른 언어로 쓰여졌지만 의미적으로는 동등한(equivalent) 문장을 인코더가 근위 임베딩 공간에 매핑할 수 있도록 훈련시키는 것입니다. 그러나 다시 한 번 말하지만, 병렬 데이터는 자료가 부족한 소수 언어에는 활용할 수 없기 때문에, 우리가 원하는 방법은 아니겠네요. 그렇다면, 우리는 어떻게 단일 언어 말뭉치만 사용해서 인코더를 비지도 학습시킬 수 있을까요?
영감. 놀랍게도, 우리의 주요 영감은 컴퓨터 비전의 영역에서 탄생했습니다. 컴퓨터 비전에서 말하는 '번역'은 일반적으로 인풋을 기존 도메인(original domain)에서 타겟 도메인(target domain)으로 번역하는 방법을 고안하는 것을 뜻하는데, 여기에서 자주 활용되는 비지도학습 방법은 주로 인코더가 양쪽 도메인의 인스턴스를 대량으로 보게 해 각 도메인의 인스턴스 분포에 대한 이해도를 높이도록 하는 것입니다. 이 아이디어의 선행 사례는 사이클 생성적 적대 신경망(CycleGAN)으로, 짝을 이루지 않은 데이터를 활용한 훈련으로도 효과적인 번역 시스템을 구축할 수 있습니다.
CycleGAN의 핵심 개념은 입력 이미지를 타겟 도메인으로 번역했을 때의 예상 결과물을 생성해 마치 병렬 데이터가 존재하는 것처럼 시뮬레이션하는 것입니다. 번역과 같은 것이죠. 이 생성 프로세스는 타겟 도메인의 전체 분포도에 부합하는 번역을 선호하도록 유도하여 실제로 대상 도메인에 속하는 것처럼 렌더링합니다. 그런 다음, 이 유사 번역물은 기존 도메인으로 다시 번역되고, 이 '재구성된' 이미지는 입력된 원본 이미지와 비교되어 유사하다고 판단하도록 유도됩니다. 이것을 '주기 일관성 손실(cycle consistency loss)'이라고 하는데, 핵심 내용, 특히 NLP의 경우에는 의미가 이 재구성 프로세스 과정에서 보존되는지의 여부를 확인합니다. 여기서부터는 주기 일관성 손실과 재구성 손실을 동일한 의미로 간주하겠습니다.
하지만 다시 한 번 말씀드리지만, 저희는 특정 도메인에서 다른 도메인으로 문장을 번역하는 데에 관심이 있는 것이 아니라, 중간 ISR을 위해 특정 성질을 포착하는 데 관심이 있습니다. 특히 영어 문장에서 생성된 ISR이 의미적으로 동등한 프랑스어 문장에서 생성된 ISR에 근접해야 하는 등, ISR의 의미적 전이성(semantic transitivity)과 언어 불가지성(language-agnosticity)이 모두 유지되는 것이 목표입니다.
ISR 일관성 손실. 이러한 문제를 해결하기 위해 우리는 번역된 문장을 통해 병렬 데이터셋이 존재하는 것처럼 시뮬레이션한다는 사실을 다시 활용해, 정방향과 역방향 번역의 ISR을 비교하고 유사하다고 판단하도록 유도하는 ISR 일관성 손실 개념을 도입했습니다. 이 아이디어의 핵심은 일관성 손실이라는 레이어를 추가해 의미적 전이성을 보존하면, 기존 도메인이나 한 번 번역을 거친 타겟 도메인 등 어떤 언어든 의미적으로 동등한 문장에서 생성된 ISR은 반드시 근위값을 가져야한다는 것입니다.
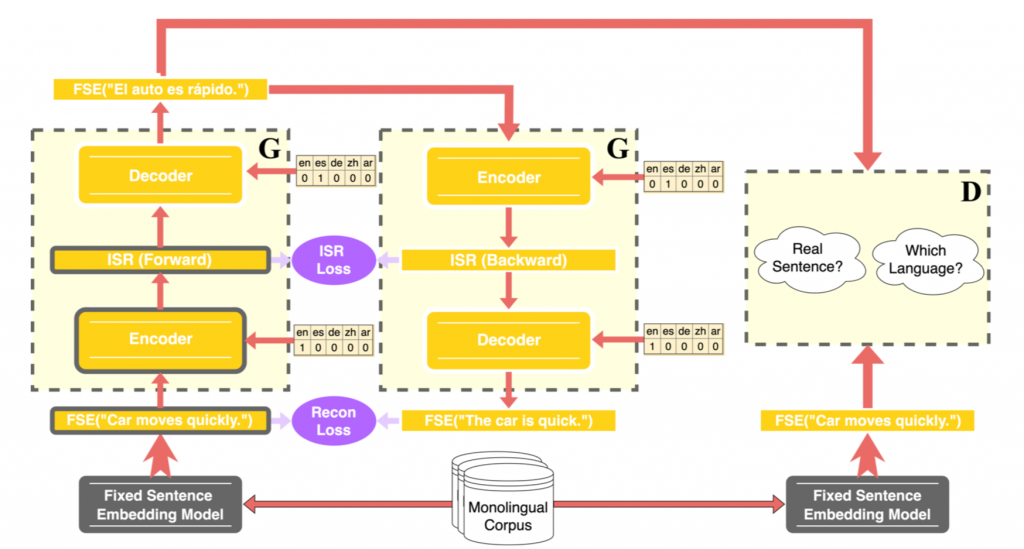
이 프레임워크 작동에 필수 요소인 적대적 손실(adversarial loss) 및 도메인 분류 손실(domain classification loss)과 같은 추가적인 세부 개념에 대해서는 저희 논문에서 더 자세하게 다루고 있으니 한 번 읽어보시기 바랍니다.
훈련 세부 정보. 이번 작업에서는 영어, 스페인어, 독일어, 중국어, 아랍어의 위키피디아 덤프에서 각각 40만 개의 문장을 긁어 모은 다음, 번역된 문장의 의미적 전이성에 대해 확신이 들 때까지 ISR 인코더를 포함한 전체 프레임워크를 하나의 테슬라 T4 GPU에서 약 60시간 동안 훈련시켰습니다.
ISR 인코더를 훈련 및 수정한 후 영어 훈련 데이터로 분류기 모델을 훈련시켰고, 아래는 그 요약입니다.
- 영어의 훈련용 예시 문장은 다국어 BERT에 의해 풍부한 의미 표상으로 변환되었고,
- 저희 ISR 인코더에 의해 ISR로 변환되었으며,
- 이를 바탕으로 저희 분류기를 학습시켰습니다.
결과. 그리고 마침내 제로 샷 언어 간 변환, 즉, 영어의 훈련용 예시로 훈련 후 비영어권 언어의 테스트용 예시로 테스트를 수행했는데, 테스트용 예시는 다국어 BERT에 의해 의미 표상으로 변환되어 ISR 인코더에 의해 ISR로 변환되었고, 연결된 ISR이 분류기에 투입되어 예측값이 출력되었습니다. 제로 샷 언어 간 변환의 결과는 아래와 같습니다.
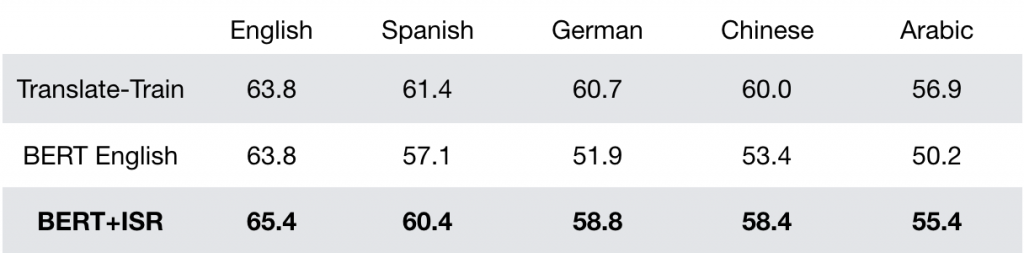
이 프레임워크는 번역-훈련의 기준선에 비해 살짝 떨어지지만 거의 비슷한 결과를 산출합니다. ISR 인코더의 절대적인 성능은 아직 산업용 프로그램에서 상용화하기에는 경험적 보완이 필요하지만, 그럼에도 불구하고 이 결과는 비지도적인 제로 샷 언어 간 변환 방식에 대한 전반적인 타당성을 보여주는 확고한 사례라고 단언합니다.
제외(ablation) 연구. 도메인 분류 손실과 ISR 일관성 손실 중 하나가 빠진 ISR 인코더를 학습시킨 다음, XNLI 개발용 자료에 포함된 5개 언어의 병렬 문장 1,000개 세트의 t-SNE 시각화를 통해 이 프레임워크의 설계가 효과적이라는 점을 확인할 수 있었습니다.
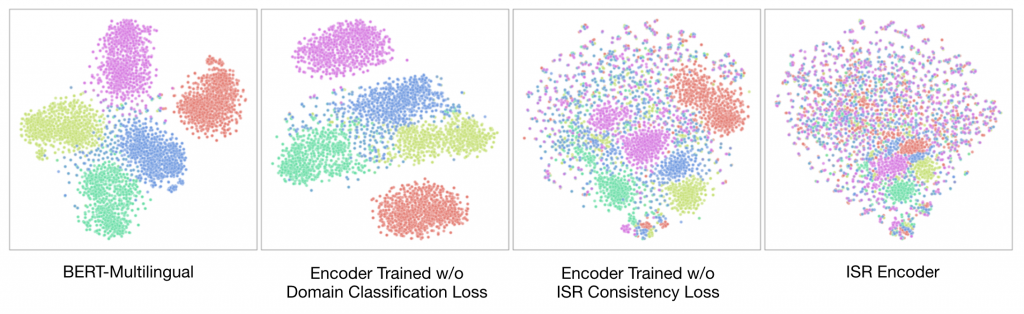
위에서 볼 수 있듯, 도메인 분류 손실과 ISR 일관성 손실이 포함되었을 때에 각 언어의 전반적인 ISR 분포가 크게 개선되는 것을 확인할 수 있습니다.
의미적 전이성에 관련한 우리의 설계 선택이 가져온 효과를 더욱 명확히 설명하기 위해, 의미적으로 평행한 문장들의 하위 집합끼리 선으로 연결했습니다. 아래 그림은 ISR 일관성 손실이 병렬 문장의 '순열 정렬'에 크게 기여하여 의미적으로 근접한 문장, 즉 병렬 문장들이 근접한 위치에 배치되도록 유도하는 것을 보여줍니다.

또한 아래 표에서 볼 수 있듯, 두 인코더의 제로샷 언어 간 변환 능력을 평가하여 정량적으로 위 내용을 확인할 수 있었습니다.
결론. 이 연구의 다음 단계는 이 프레임워크를 문장 수준이 아닌 단어 수준의 임베딩을 생성하는 언어 인코더로 확대 적용하는 것입니다. 비록 작은 발걸음에 불과하지만, 저희의 연구가 소수 언어의 데이터 부족 문제를 해결할 수 있는 새롭고 확장 가능한 방향의 문을 열 수 있기를 바라며, 이러한 마음으로 이 작업에 사용한 코드 구현과 지침을 여기에 공유합니다.
읽어주셔서 감사합니다!