슈퍼브에이아이의 NVIDIA Isaac Lab 기반 로봇 강화학습 실험기
합성 데이터 파이프라인에 이어, 슈퍼브에이아이 3D 팀이 NVIDIA Isaac Lab으로 로봇 강화학습에 직접 뛰어든 두 건의 실험을 공유합니다. 기성 4족 로봇 정책 배포와, 멀티 에이전트 축구 과제를 처음부터 학습시킨 과정입니다.

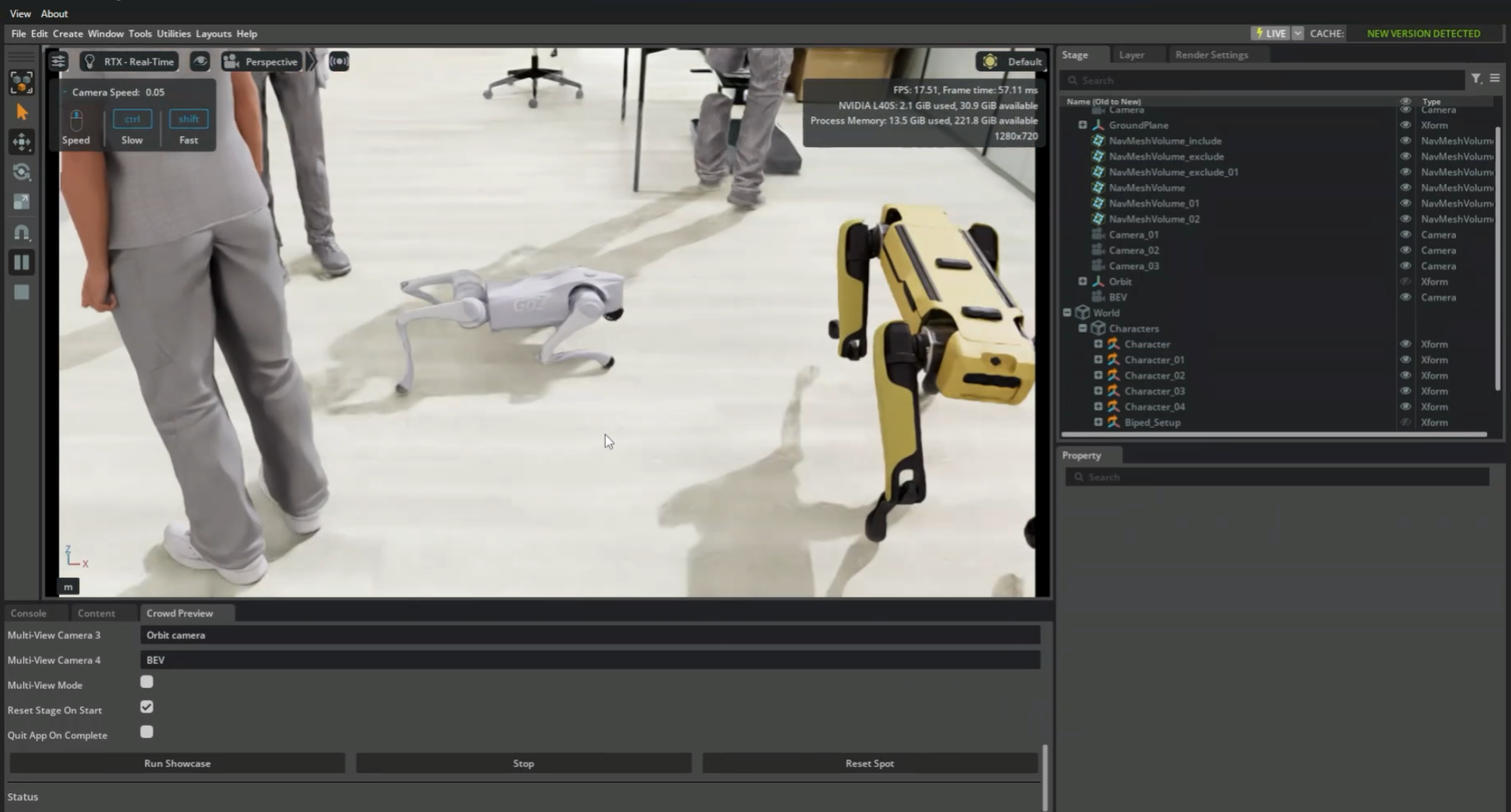
합성 데이터 파이프라인에 이어, 슈퍼브에이아이 3D 팀은 NVIDIA Isaac Lab으로 로봇 강화학습에 뛰어들었습니다. 기성 로봇 정책을 가져와 배포한 사례와, 멀티 에이전트 과제를 처음부터 만들어 학습시킨 사례를 정리했습니다.
슈퍼브에이아이 3D 팀은 앞선 글에서 NVIDIA Isaac Sim으로 합성 데이터 파이프라인을 구축한 과정을 소개했습니다. 다중 카메라 객체 추적(MTMC) 모델을 학습시키기 위해, 실제 공간을 시뮬레이션으로 옮기고 사람을 합성해 라벨링된 영상을 대량으로 만들어내는 작업이었습니다.
이번에는 같은 시뮬레이션 환경 위에 작은 실험을 하나 더 얹어 봤습니다. Isaac Lab으로 로봇이 스스로 움직이도록 학습시켜 본 것인데요. 핵심은 여전히 MTMC 합성 데이터를 구축하는 데 있고, 이러한 행동 학습은 데이터를 더 풍부하게 채우기 위한 수단입니다. 스스로 움직이는 객체는 정적인 장면보다 훨씬 다양한 상황을 만들어 내 데이터로 되돌릴 수 있고, 4족 로봇 관제와도 맞닿아 있어 시도하게 됐습니다.
이 글은 송찬영 3D 리서치 엔지니어의 사내 세미나를 정리한 것으로, 슈퍼브에이아이 3D 팀이 Isaac Lab으로 진행한 실험을 다룹니다.
Isaac Sim 위에서 동작하는 오픈소스 로봇 학습 프레임워크입니다. 핵심은 GPU 병렬화로, 동일한 환경 수천 개를 한 번에 시뮬레이션하며 강화학습을 돌릴 수 있습니다. 이 글에서는 기능 자체를 깊이 들여다보기보다, 슈퍼브에이아이가 이를 어떻게 활용했는지에 집중합니다.
케이스 스터디 1. 기성 로봇 환경 위에서 정책 학습 후 배포
첫 번째 실험의 목표는 처음부터 무언가를 만드는 것이 아니라, 이미 있는 것을 재사용하고 배포하는 것이었습니다. 작업은 세 단계로 정리됩니다.
- 학습: Isaac Lab이 기본 제공하는 4족 보행 과제(Isaac-Velocity-Flat-Unitree-Go2-v0)로 유니트리(Unitree) Go2를 학습시키고 정책을 내보냅니다. 새 MDP를 직접 설계하지 않고 기성 과제를 그대로 썼습니다.
- 불러오기: 보스턴 다이내믹스(Boston Dynamics) Spot을 기존 정책과 함께 씬에 불러옵니다.
- 배포: 학습한 Go2 정책을 같은 씬에 연결해 배포합니다.
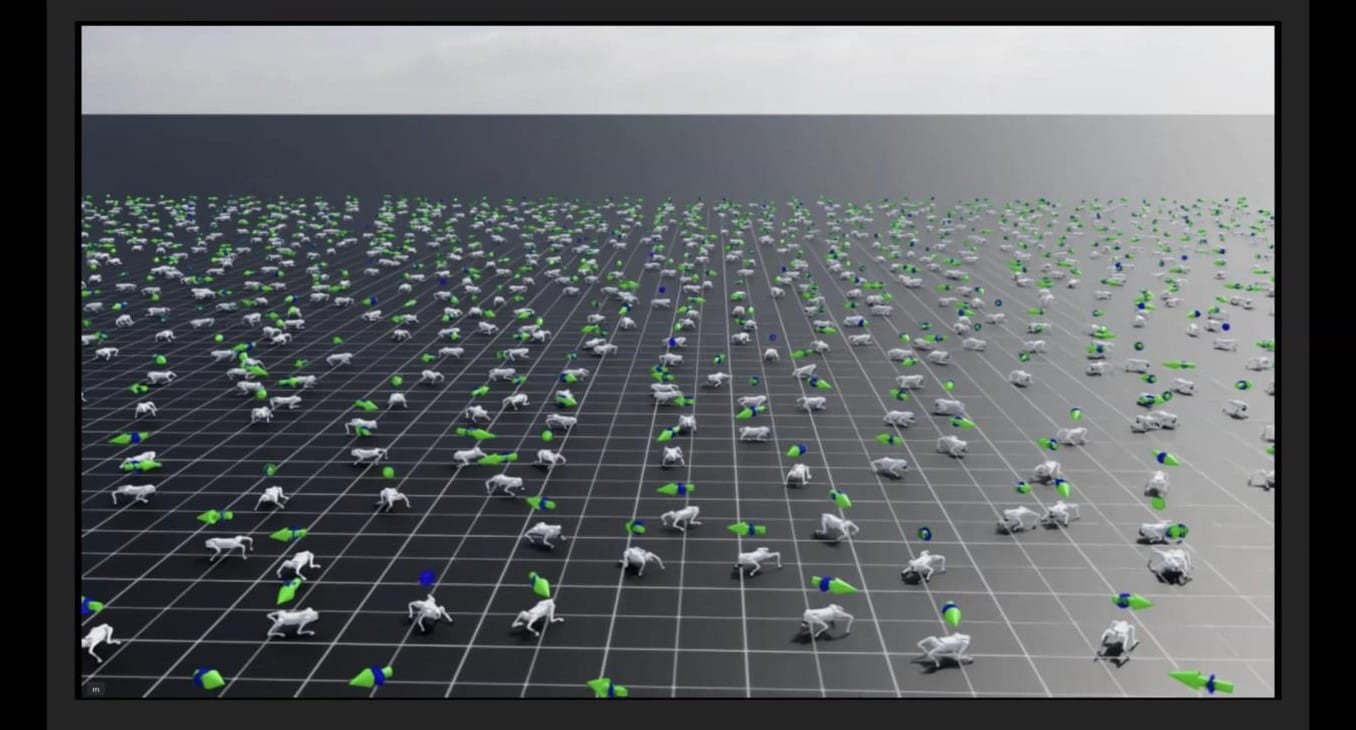
수백 개의 4족 로봇 환경을 GPU에서 동시에 돌리며 보행 정책을 학습하는 모습. 케이스 스터디 1에서는 이렇게 학습된 기성 정책을 그대로 가져와 활용했습니다.
배포 대상은 앞선 합성 데이터 작업에서 다뤘던 것과 같은 계열의 실내 공간이었습니다. Go2와 Spot이 사람들 사이를 걸어 다니고 피하도록, 기존 씬에 통합하는 것이 과제였습니다.
이 과정에서 극복한 문제는 다음과 같습니다.
- 학습 환경 설정값 vs. 시뮬레이션 설정값 충돌 학습된 정책의 물리 time step 값과 시뮬레이션 물리 time step 값이 달라서 isaac sim으로 가져왔을때 작동하지 않는 원인을 추적해 고쳤습니다.
핵심은 기존 환경과 자료들을 사용해 저희의 필요 케이스에 적용하는 과정이었습니다.
케이스 스터디 2. 멀티 에이전트 과제를 처음부터 만들기
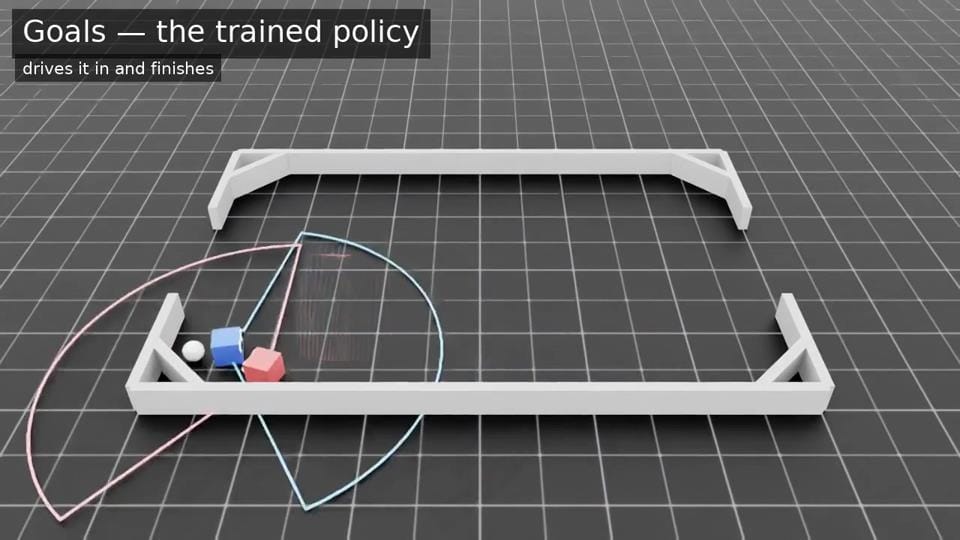
두 번째 실험은 정반대였습니다. 참고할 기성 과제 없이 ‘큐브 축구’ 게임을 바닥부터 설계했습니다. 규칙은 단순합니다. 두 개의 큐브 선수와 공 하나, 벽으로 둘러싸인 경기장, 그리고 각 선수에게 주어진 제한된 시야. 목표는 득점하도록 학습시키는 것입니다.
과제의 뼈대(설정과 핵심 파이프라인)는 비교적 빠르게 갖춰졌습니다. 2,048개 환경을 병렬로 돌리는 학습 구조도 이 단계에서 함께 마련됐고요. 정작 시간이 든 건 그다음의 반복이었습니다. 보상 함수와 환경을 다섯 단계에 걸쳐 개선하면서 정책의 완성도를 끌어올렸습니다.
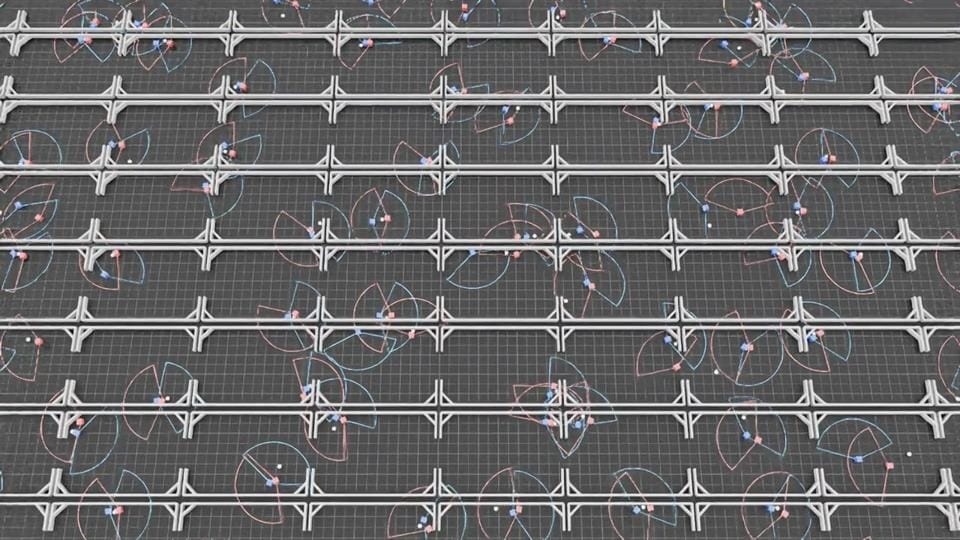

- 1단계: 학습 전. 무작위 정책. 큐브는 떨고 공은 거의 움직이지 않습니다.
- 2단계: 학습이 자꾸 무너졌습니다. 매번 약 3.3만 스텝에서 붕괴했는데, 한동안 물리 설정을 의심했지만 원인은 다른 곳에 있었습니다. 학습률(learning rate)이 통제 없이 치솟아 가중치가 NaN이 된 것이었습니다. 상한 한 줄(max_lr: 3.0e-04)로 해결했습니다.
- 3단계: 안정적으로 학습되지만, 엉뚱한 것을 배웠습니다. ‘공에 닿으면 보상’을 매 스텝 주자 큐브는 공을 끌어안고 버티는 것이 최적이 됐습니다(보상 해킹). 보상을 ‘공이 골대에 가까워지는 정도’가 지배하도록 다시 설계해, 큐브가 공을 몰고 가도록 만들었습니다.
- 4단계: 시야를 현실적으로 좁혔습니다(360° → 원뿔형). 4단계에서는 학습이 어느 정도 안정되고 의도한 행동이 나타나기 시작했습니다. 그래서 원래 제약 조건 중 하나였던 제한적 시야를 다시 적용했습니다. 다만 이와는 별개로, 개선하려던 동작들이 여전히 서로 붙어 공만 미는 교착이 자주 나타났습니다.
- 5단계: 큐브는 공을 ‘밀’ 수만 있고 ‘찰’ 수는 없었습니다. 보상을 조정해 숫자는 올랐지만 경기 모습은 그대로였습니다. 행동 공간에 킥(속도 임펄스)을 추가하자 비로소 실제 슈팅이 나왔고, 득점률은 약 70%까지 올랐습니다.
여기서 가장 크게 와닿은 건, 진입 장벽이 달라졌다는 사실입니다. 코딩 에이전트와 Isaac Lab 프레임워크가 있으면, 환경을 처음부터 세우는 일에서 정책을 학습시키는 일까지 한 사람이 이어서 시도해 볼 수 있습니다. 하지만 결과는 단번에 나오지 않습니다. 코딩 에이전트와 반복적으로 주고받으며 다듬어 가는 과정을 거쳐, 의도한 강화학습 동작에 도달하게 됩니다.
AI 코딩 에이전트로 시뮬레이션을 다루며 배운 것
두 실험 모두 상당 부분을 AI 코딩 에이전트로 구동했습니다. 코드 작성·학습 실행·디버깅을 에이전트에 맡기면서, 어떤 방식의 지시가 통하고 통하지 않는지가 비교적 또렷하게 드러났습니다.
통한 방식
- 에이전트가 추론할 수 없는 사실은 추가로 준다. 어느 장비에 씬이 있는지, 파일 경로, 타이밍 같은 환경 정보.
- 지표가 아니라 산출물을 본다. "공이 아직 밀리기만 한다"는 관찰을 통해 빠져 있던 킥을 찾아냈습니다. 한 걸음 더 나아가, 코딩 에이전트에게 렌더된 영상을 직접 확인하며 검증하도록 했더니 한결 정확한 결과물이 나왔습니다.
- 고치기 전에 진단하게 한다. “바꾸지 말고 먼저 설명해줘.” 방법 자체에 의문을 던지는 것도 효과적이었습니다. “GPU를 제대로 쓰고 있는 게 맞나?”라는 질문이 학습을 7배 빠르게 만든 적도 있습니다.
통하지 않은 방식
- 해법부터 지시하는 것. “회전 속도를 올려”, “그냥 GRU 써봐”, 막연한 “고쳐/확인해” 같은 지시는 대체로 헛돌았습니다. ‘먼저 측정·확인하라’로 바꾸고 정확한 산출물을 지목하는 편이 나았습니다.
정리하며
슈퍼브에이아이 3D 팀은 Isaac Lab으로 두 방향을 모두 확인했습니다. 기성 자산을 재사용해 빠르게 배포하는 길과, 과제를 처음부터 설계해 학습시키는 길. 합성 데이터로 인식 모델을 키우던 작업이, 이제 같은 시뮬레이션 환경에서 로봇의 행동을 학습시키는 단계로 이어지고 있습니다.
시뮬레이터가 제공하는 기능을 쓰는 데 그치지 않고, 학습된 정책의 구조를 이해하고 문제의 레이어를 구분하며, 지표 너머의 행동을 직접 관찰하는 것. 피지컬 AI 연구에서 슈퍼브에이아이 3D 팀이 쌓아가는 방식입니다.
자주 묻는 질문
NVIDIA Isaac Lab이란 무엇인가요?
Isaac Sim 위에서 동작하는 오픈소스 로봇 학습 프레임워크입니다. GPU에서 수천 개의 시뮬레이션 환경을 병렬로 돌려 로봇의 강화학습을 수행합니다.
Isaac Sim과 Isaac Lab은 어떻게 다른가요?
Isaac Sim은 물리·렌더링을 담당하는 시뮬레이션 플랫폼이고, Isaac Lab은 그 위에서 로봇 정책을 학습시키는 프레임워크입니다. 슈퍼브에이아이는 먼저 Isaac Sim으로 합성 데이터를 만들었고, 이번에는 Isaac Lab으로 로봇 행동을 학습시켰습니다.
슈퍼브에이아이는 Isaac Lab으로 무엇을 했나요?
두 가지입니다. (1) 기성 학습 환경을 활용해 4족 로봇 Go2의 정책을 직접 학습시키고, 기성 정책을 그대로 쓰는 Spot과 함께 기존 씬에 배포했습니다. (2) 멀티 에이전트 큐브 축구 과제를 처음부터 설계해 득점까지 학습시켰습니다. Isaac Lab을 익히고, 그 환경에서 코딩 에이전트가 어디까지 해내는지 검증하기 위한 과제였습니다.
이 글은 합성 데이터 파이프라인 글과 어떻게 이어지나요?
앞 글이 인식 모델을 위한 합성 데이터를 만드는 단계였다면, 이번 글은 같은 시뮬레이션 환경에서 로봇이 행동을 학습하는 단계입니다. 인식에서 행동으로 이어지는 연속선상에 있습니다.
