2023년 생성형AI 트렌드와 AI 개발을 위한 필수요소 요약


2023년 한 해는 생성형AI의 해였다고 해도 과언이 아니다. 이러한 생성형AI의 확산 경향은 챗GPT를 중심으로 한 초거대언어모델(LLM)에서 특히 두드러지게 나타났는데, 그동안 인공지능 시장에서는 Google, OpenAI, Meta 등 빅테크 기업들이 자사 기초모델(Foundation Model)을 적용한 Bard, ChatGPT, LLaMA 등 다양한 서비스를 출시해왔다.
뿐만 아니라 국내외 여러 스타트업과 연구기관 등에서는 자체적으로 확보한 데이터와 오픈소스로 공개된 기초모델을 기반으로 특정 언어와 도메인 지식을 강화하여 다양한 형태의 sLLM(small LLM)을 출시하고 있다. 또한 고객 상담용 챗봇 부터 사내지식관리(Knowledge Management System, KMS) 등 시스템 등 성능과 활용 목적에 따라 차별화 포인트를 가지고 있는 여러 종류의 초거대언어모델 기반 서비스들이 등장하면서 인공지능을 도입하고자 하는 기업들의 선택지가 넓어지는 만큼 혼란도 점점 더 가중되고 있다.

이처럼 시시각각 변화하는 인공지능 기술을 올바르게 이해하고 비즈니스에 적용하기 위해서는 우선 기초적인 개념들에 대해 이해하는 것이 무엇보다 중요하다. 이번 시간에는 생성형AI와 초거대언어모델을 비롯한 관련 기술의 여러 가지 개념들을 정리하고 성능 좋은 인공지능 모델을 개발하기 위한 필수적인 요소들에 대해서 알아보도록 하자.
1. 멀티모달, 생성형AI 모델의 경계가 사라지고 있다.
생성형AI란 이미지, 텍스트, 음성 등 다양한 형태의 방대한 데이터를 사전학습하고 이를 바탕으로 그에 대응하는 형태의 창작물을 생성해 내는 인공지능 모델들을 통틀어 지칭한다. 그중에서도 초거대언어모델이란 그 용어에서도 알 수 있듯이 언어 생성에 특화된 생성형 인공지능 모델들을 지칭한다. 즉 초거대언어모델은 이미지, 음악, 영상, 텍스트 등 수많은 생성형AI 중 한 가지 하위 분야라고 할 수 있는 것이다.

GPT4.0과 Bard 등 최근 출시되고 있는 초거대언어모델 서비스들은 텍스트 데이터뿐만 아니라 이미지와 음성 등 다양한 형태의 데이터로 입출력이 가능한 멀티모달(Multi-modal) 기능을 탑재하고 있어 다양한 형태로 창작이 가능해졌다. 이처럼 하나의 모델이 처리할 수 있는 데이터의 종류에 제한이 점점 사라지면서 이미지와 텍스트 등생성형ai간 구분의 경계가 점차 사라지고 있는 추세이기도 하다.
2. 초거대언어모델의 핵심이 되는 기초모델(Foundation Model)
초거대언어모델은 인터넷 상에 존재하는 웹페이지, 위키, 학술논문 등 방대한 양의 텍스트 데이터를 사전학습(Pre-trained)한 기초모델에 기반하고 있다. 기초모델이 사전학습한 텍스트 데이터 덕분에 초거대언어모델이 일상 대화나 일반적인 텍스트 데이터를 이해하고 생성할 수 있는 기반이 마련되는 것이다.

이러한 기초모델들은 여러 빅테크 기업에서 제공하는 초거대언어모델 서비스의 뼈대가 된다. 예를 들어 OpenAI의 LLM 서비스인 챗GPT는 GPT-3.5/GPT-4.0/Text-davinci 등의 기초모델을 바탕으로 구동되며, Google의 LLM 서비스 Bard는 PaLM2라는 기초모델에 기반하여 작동한다.
여러 연구논문들에 따르면 기초모델이 보다 정확하고 자연스러운 답변을 생성해 내기 위해서는 모델 알고리즘뿐 아니라 사전학습 데이터의 질과 양 그리고 모델의 매개변수(Parameter)의 수가 결정적인 역할을 하는 것으로 알려져 있다. 이처럼 초거대언어모델의 전체적인 성능은 기초모델의 성능에 크게 의존하는 경우가 많다.
3. 초거대언어모델의 개발을 편리하게 해주는 랭체인(Langchain)
그러나 초거대언어모델의 성능에 영향을 끼치는 요소에는 기초모델만 있는 것은 아니다. 기초모델에 추가적인 데이터를 활용해 미세조정(Fine-tuning)을 가하거나 프롬프트 엔지니어링(Prompt Engineering)이라는 방법론을 활용하여 모델의 환각현상(Hallucination)을 방지하고 성능을 개선하는 등 기초모델을 더욱 잘 활용하기 위한 다양한 기술들이 존재한다.
특히 프롬프트 엔지니어링은 초거대언어모델에서 매우 중요한 요소 중 하나이다. 프롬프트(Prompt)란 모델이 특정 질문이나 명령에 어떻게 응답해야 하는지를 정의하는 텍스트를 가리키는데, 이를 활용한 프롬프트 엔지니어링은 모델에게 원하는 결과를 산출하도록 도와주는 역할을 한다. 이는 모델이 특정 작업에 더 정확하게 반응하도록 유도하거나 모델이 생성하는 결과물의 품질을 향상시키는 데 사용된다.
프롬프트 엔지니어링은 기초모델이 사전학습되지 않은 정보에 대해 부정확하거나 관련 없는 정보를 제공하는 환각 현상을 방지하고 원하는 결과를 얻기 위한 핵심적인 전략이다. 즉, 모델의 오류를 줄이고 원하는 응답을 얻기 위해 프롬프트 엔지니어링은 매우 중요한 역할을 한다. 따라서 초거대언어모델의 성능을 향상시키기 위해서는 앞에서 살펴본 좋은 기초 모델을 사용하는 것뿐만 아니라 효과적인 프롬프트 엔지니어링이 필수적이라고 할 수 있다.
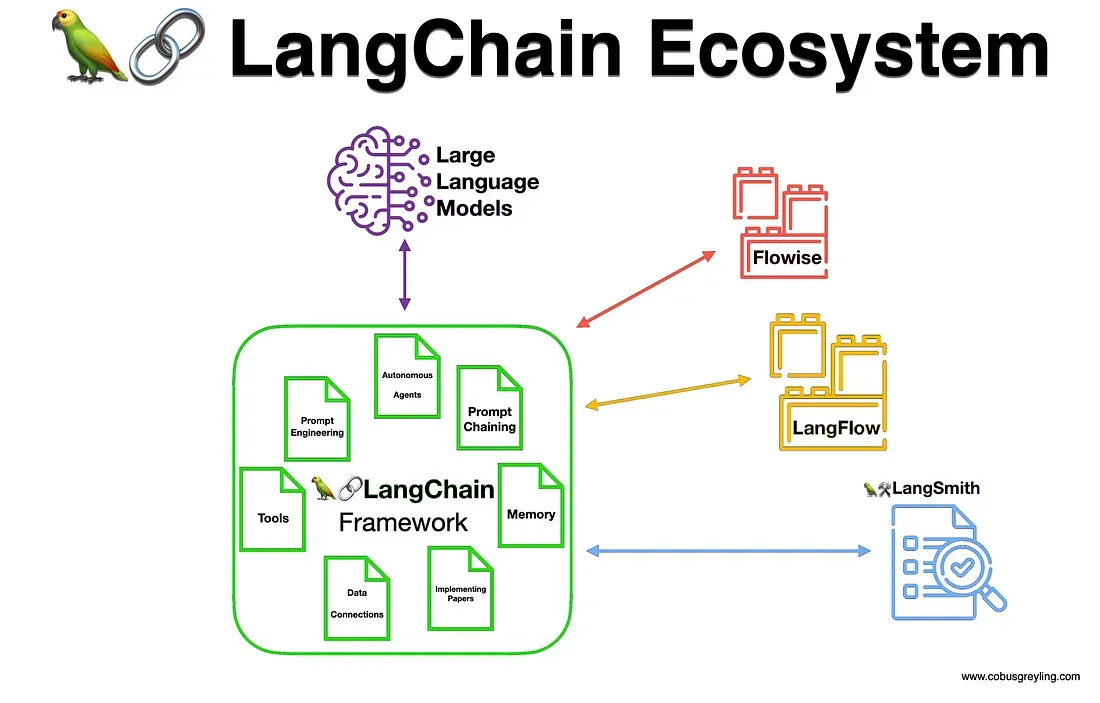
최근에는 초거대언어모델에 이러한 프롬프트 엔지니어링을 적용하고 손쉽게 어플리케이션 개발에 활용하기 위한 다양한 프레임워크(Framework)가 Python 라이브러리의 형태로 적용되고 있다. 특히 최근 초거대언어모델 개발자들 사이에서 많이 활용되는 패키지로는 랭체인이 있는데, 이러한 프레임워크를 사용함으로써 비교적 적은 노력으로 초거대언어모델을 원하는 형태로 커스터마이즈 하고 활용하는 것이 가능해졌다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.