제조 불량 검수 AI 제작 실전 가이드: 산업용 결함 탐지 AI 모델 개발부터 배포까지
제조 현장의 불량 검수를 AI로 하고 있다면, 성능이 나아지지 않는 AI에 불만족하다면, 이 튜토리얼이 도움이 되실 것입니다. 카메라를 활용한 데이터 수집부터 슈퍼브에이아이 플랫폼으로 데이터 선별, 라벨링, 모델 학습 및 실시간 배포까지 전체 과정을 단계별로 알아봅니다. 생산 라인에서 자동화된 품질 관리 시스템을 구축하는 실용적인 워크플로우를 제공합니다.

필자: 슈퍼브에이아이 솔루션 엔지니어 Sam Mardirosian
고성능 컴퓨터 비전 모델을 개발하려면 효과적인 모델 학습 파이프라인을 구축하는 것이 필수적입니다. 파이프라인을 잘 구축하면 데이터를 효율적으로 수집하고, 똑똑하게 선별하고, 정확하게 라벨링하고, 효과적으로 모델을 학습시켜 현실 시나리오에도 우수한 일반화 성능을 보이도록 만들 수 있습니다. 또한 파이프라인의 각 단계를 최적화하면 강건한 AI 시스템을 개발하는데 필요한 시간, 비용, 노력을 절감할 수 있습니다.
이번 튜토리얼에서는 데이터 수집, 선별부터 모델 학습 및 배포에 이르는 전체적인 모델 개발 및 배포 파이프라인을 단계별로 살펴보겠습니다. 또, 어떻게 슈퍼브에이아이의 올인원 AI 플랫폼을 통해 이 과정을 자동화하고 효율화하여 성능과 효율성이라는 두 마리 토끼를 잡을 수 있는지 보여드리고자 합니다.
산업 현장에 적용할 일반적인 실시간 결함 탐지 모델을 개발해 보겠습니다. 이번에는 Lucid Vision Labs의 표준 카메라를 사용할 예정이지만, 이 워크플로우는 보안 카메라(예: RTSP CCTV)나 웹캠과 같은 다른 카메라 종류에도 적용할 수 있습니다. Lucid Vision Labs 카메라로 이미지 데이터를 취득하고, 슈퍼브 큐레이트와 슈퍼브 라벨을 이용해 데이터를 선별 및 라벨링하고, 슈퍼브 모델로 AI 모델을 학습시킨 뒤 최종적으로 배포하여 실시간 결함 모니터링을 진행할 예정입니다. 이 방법은 보안, 안전, 장비 모니터링 및 규제 컴플라이언스와 같은 다른 객체 탐지 사례에도 충분히 적용할 수 있습니다.
이 튜토리얼이 마무리될 때 쯤에는 다양한 유즈 케이스에 적용해 볼 수 있는 실용적인 파이프라인을 구축하실 수 있을 것입니다. 이를 통해 적절하게 선별된 고품질의 데이터로 여러분의 컴퓨터 비전 모델을 학습시키고 실제 환경에 배포할 준비를 마쳐보세요.
데이터 수집하기
컴퓨터 비전 모델 학습의 시작이자 끝은 바로 데이터 수집이라고 할 수 있습니다. 첫 단계이지만, 가장 중요한 단계이기도 합니다. 정확하고 신뢰할 수 있는 모델 성능을 유지하기 위해서는 품질과 다양성이 모두 확보된 데이터셋을 준비하는 것이 가장 중요하기 때문입니다. 필요한 데이터의 양은 모델이 수행하려는 작업이 얼마나 복잡한지에 따라 달라집니다. 간단한 작업을 처리하는 것이라면 상대적으로 적은 이미지로도 충분하지만, 보다 어렵고 예외적인 데이터, 즉 엣지 케이스가 많이 발생하는 시나리오를 처리하려면 더 많고 더 다양한 데이터가 필요합니다.
이번 튜토리얼에서는 여러분이 학습용 데이터 수집 및 모델 배포에 Lucid Vision Labs 카메라를 활용하며 Lucid Arena SDK를 이미 설치한 상태라고 가정하겠습니다. 아래는 Lucid Vision Labs 카메라에서 데이터를 수집할 수 있는 스크립트입니다. 더 자세히 말하자면, 이 스크립트는 매 초 한 장의 이미지를 수집하여 새로 생성된 슈퍼브 큐레이트 데이터셋에 업로드합니다. 어떤 목적으로 컴퓨터 비전을 도입하냐에 따라 원하는 학습 데이터 수집 빈도가 더 높거나 낮을 수도 있습니다. 또한 조도 센서나 로터리 모터 인코더 등을 사용해 트리거를 설정, 불규칙한 빈도로 이미지를 촬영할 수도 있습니다. 예를 들면 컨베이어 벨트 위에 설치된 카메라의 바로 아래에 객체가 위치하는 경우에만 사진을 촬영할 수도 있는 것입니다.
$ pip install --upgrade superb-ai-curate numpy opencv-pythonimport os
import time
import numpy as np
import cv2
import time
import spb_curate
import arena_api.system as sys
from datetime import datetime
from spb_curate import curate
# Superb AI access key and team name
spb_curate.access_key = "your_API_access_key"
spb_curate.team_name = "your_team_name"
# Define output directory
# Directory to save captured images
SAVE_DIR = "captured_images"
os.makedirs(SAVE_DIR, exist_ok=True)
def initialize_camera():
system = sys.system
devices = system.device_infos
if not devices:
raise Exception("No Lucid camera detected.")
# Create a camera device
camera = system.create_device(devices[0])
return camera
def capture_image(camera):
camera.start_stream()
while True:
try:
buffer = camera.get_buffer(timeout=2000) # Get image buffer
last_captured_time = None
if (last_captured_time is not None
and time.time() - last_captured_time < 1):
camera.requeue_buffer(buffer)
continue
last_captured_time = time.time()
# Convert to NumPy array
item = BufferFactory.copy(buffer)
camera.requeue_buffer(buffer) # Requeue buffer for next frame
num_channels=1
buffer_bytes_per_pixel = int(len(item.data)/(item.width * item.height))
array = (ctypes.c_ubyte * num_channels * item.width * item.height).from_address(ctypes.addressof(item.pbytes))
npndarray = np.ndarray(buffer=array, dtype=np.uint8, shape=(item.height, item.width, buffer_bytes_per_pixel))
# Save image
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = os.path.join(SAVE_DIR, f"frame_{timestamp}.jpg")
cv2.imwrite(filename, npndarray)
print(f"Saved: {filename}")
yield filename
# Stop stream on keyboard interrupt (Ctrl + C)
except KeyboardInterrupt:
print("Stopping capture.")
break
# Stop stream
camera.stop_stream()
def upload_image(image_path, dataset:spb_curate.Dataset):
image = curate.Image(
key=os.path.basename(image_path),
source=curate.ImageSourceLocal(asset=image_path),
metadata={}
)
dataset.add_images(images=[image])
if __name__ == "__main__":
print("Starting image capture.")
dataset = curate.create_dataset("Lucid Camera Data")
camera = initialize_camera()
for image_path in capture_image(camera):
upload_image(image_path, dataset)
system.destroy_device(camera)초기 데이터를 충분히 수집했다면(예: 5천 프레임) 슈퍼브 큐레이트로 데이터를 업로드합니다. 슈퍼브 큐레이트는 라벨링 프로세스를 시작하기 전 먼저 데이터셋을 정제하고 최적화할 수 있게 도와줍니다. 슈퍼브 큐레이트의 데이터 선별 자동화를 통해 가장 유의미한 데이터만을 선별해 모델 학습에 사용하면 휴먼인더루프(HITL, 인간 참여형) 라벨링의 효율성을 높이는 동시에 비용을 절감할 수 있습니다. 어떤 경우에는 이런 방법으로 학습용 데이터셋의 크기는 최대 75% 줄이면서도 모델 성능을 비슷하게 유지할 수 있습니다.
슈퍼브 큐레이트로 데이터 선별하기
데이터 업로드가 완료되면 이제부터 슈퍼브 큐레이트에서 데이터를 정제하고 라벨링을 위한 준비를 진행할 수 있습니다. 슈퍼브 플랫폼에는 데이터셋 분석을 위한 강력한 도구들이 제공되기 때문에 손쉽게 메타데이터를 기준으로 데이터를 필터링하거나, 라벨링 여부와 무관하게 자연어로 데이터를 검색하거나, 데이터 임베딩 분포도를 스캐터 뷰(Scatter View) 상에 시각화할 수 있습니다. 이 기능들을 통해 데이터 선별 프로세스를 효율화하고 수집한 데이터에 대한 깊은 인사이트를 도출할 수 있습니다.
보다 효율적인 라벨링을 위해 스마트 데이터 선별 기능인 오토큐레이트를 사용해 보겠습니다. 오토큐레이트는 엣지 케이스 자동 선별, 라벨링 오류 탐지 등과 같은 다양한 옵션이 제공되어 전체적인 데이터셋 품질을 향상시키기 용이합니다. 이번 튜토리얼에서는 라벨링 및 모델 학습에 사용하기에 가장 적절한 고가치 데이터 선별 기능인 “라벨링할 데이터 선별(Curate What to Label)”을 사용하겠습니다. 모델에게 가장 필요한 정보를 제공하는 데이터를 우선시함으로서 모델 성능을 높임과 동시에 매뉴얼 어노테이션에 소모되는 시간과 비용을 절감할 수 있습니다.

위에서 언급했듯이 처음 라벨링할 최적의 데이터를 선별하고자 할 때 몇 가지 옵션을 선택할 수 있습니다. 어떤 경우에는 AI 기반 자연어 검색 기능과 오토큐레이트 도구들을 함께 사용해 모델 학습에 이용할 흥미로운 엣지 케이스들을 선별하는 것이 좋을 수 있습니다. 슈퍼브 큐레이트에 적용된 것과 같은 멀티모달 VLM(비전-언어 모델)의 장점은 텍스트와 이미지 모두로 검색할 수 있다는 점과 데이터를 라벨링 할 필요가 없다는 점입니다. 이 뿐 아니라 시간, 카메라, 장소 등과 같은 메타데이터를 사용해 데이터를 보다 세밀하게 선별할 수도 있습니다.
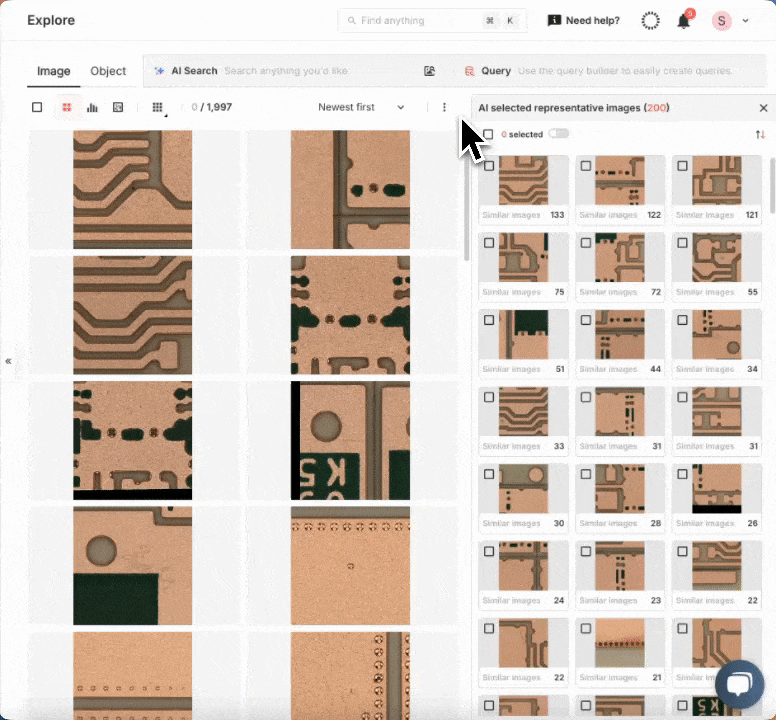
어떤 경우에는 결함이나 이상 상황이 발생할 확률이 1,000개 인스턴스 중 1개, 또는 10,000개 중 1개와 같이 극히 낮을 수 있습니다. 다시 말해 모델을 학습시킬 충분한 현실 데이터를 모으려면 수천만 장의 이미지를 촬영해야 할 수도 있다는 뜻인데, 이는 너무나 비효율적이고 많은 비용이 필요합니다.
이 어려움을 해결할 수 있는 방법 중 하나가 바로 합성 데이터입니다. 슈퍼브 모델로 합성 이미지 생성 모델을 학습시켜 엣지 케이스 데이터를 생성하게 되면 방대한 현실 데이터셋을 구축하지 않더라도 모델 성능을 개선할 수 있습니다.

데이터셋을 개선하기 위해 사전 학습된 모델과 기존 데이터로 학습한 모델을 사용하여 라벨링되지 않은 이미지에 인페인팅 도구로 합성 객체를 삽입할 수 있습니다(위 영상 참고). 만약 라벨링 된 이미지, 즉 어노테이션이 있는 이미지를 가지고 있다면 이를 참고해 기존의 객체 레이아웃은 그대로 두고 합성 데이터만 자동으로 생성할 수도 있습니다(아래 영상 참고). 이 방식으로 현실적인 학습 데이터를 생성하고 모델 성능을 개선할 수 있습니다.

처음 라벨링 할 이미지 세트를 선택했다면 이제 이 슬라이스를 슈퍼브 라벨로 전송합니다.
슈퍼브 라벨로 데이터 라벨링하기
슈퍼브 라벨에서는 서로 다른 머신러닝 작업에 적합한 다양한 종류의 라벨 및 프로젝트를 선택할 수 있습니다. 또 슈퍼브 라벨의 고급 라벨링 자동화 도구와 강력한 리뷰 워크플로우를 활용하면 모델 학습에 사용할 첫 정답 데이터셋을 빠르게 생성할 수 있습니다.
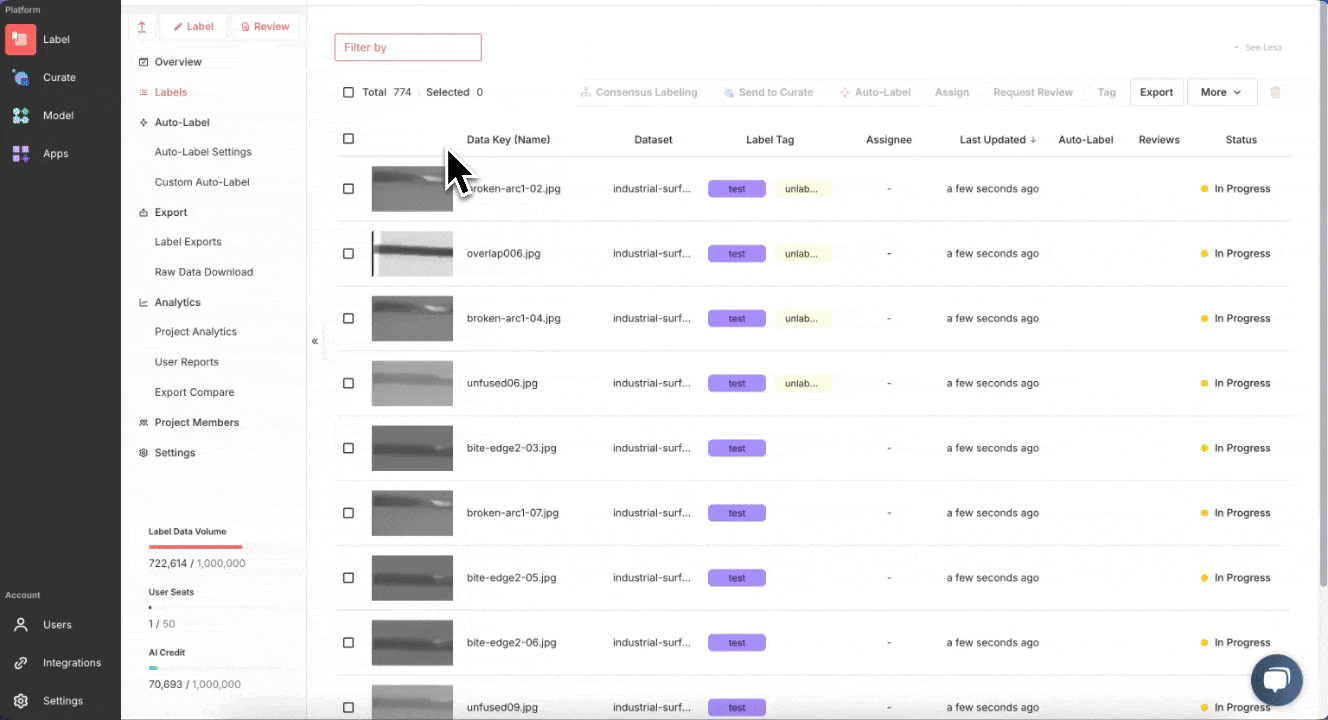
슈퍼브에이아이는 초기 라벨링 자동화를 위한 사전 학습 모델들을 옵션으로 제공합니다. 소량의 정답 데이터를 라벨링하면 이 모델들을 미세조정해 사용자의 특수한 유즈 케이스에 최적화된 커스텀 오토라벨 모델을 생성할 수 있습니다. 나머지 데이터를 라벨링하고 나면 어노테이션을 다시 슈퍼브 큐레이트로 보내 추가적인 데이터 선별과 모델 학습을 진행할 수 있습니다.
슈퍼브 모델로 AI 모델 학습하기
라벨링 된 데이터를 다시 슈퍼브 큐레이트로 보냈다면 이제 슈퍼브 모델에서 모델을 학습할 차례입니다. 슈퍼브 모델의 모델 허브는 강력한 파운데이션 모델과 유명한 컴퓨터 비전 모델을 다양하게 제공하기 때문에 객체 탐지, 세그멘테이션, 이미지 생성까지 입맛에 맞는 모델을 고를 수 있습니다.
예를 들어 객체 탐지는 YOLOv6와 DETA 모델이, 세그멘테이션은 DETR과 Mask2Former 모델이 제공됩니다. 이번 예시에서는 DETA 모델을 기초 모델로 학습을 진행하겠습니다. DETA (Detection Transformer) 모델은 작고 희소하고 복잡한 결함도 높은 정확성으로 탐지할 수 있어 결함 탐지에 매우 효과적인 모델입니다.
글로벌 셀프어텐션을 사용하고 사전 정의된 앵커가 별로 없기 때문에 사소한 이상 현상도 정확히 식별하고 불규칙한 결함 패턴도 처리할 수 있으며 데이터가 제한된 시나리오에도 빠르게 적응할 수 있어 결함의 종류가 바뀌거나 결함 데이터가 희소한 산업에서 사용하기에 이상적입니다.

슈퍼브 모델에서 비전 인식(Recognition) 탭을 선택하고 “새 모델 학습하기”를 선택합니다. DETA를 모델 소스로 선택하고, “랜덤 분할(Random split)”을 눌러 학습용 데이터셋과 검증용 데이터셋을 분할합니다. 보다 효과적으로 학습용 데이터셋과 검증용 데이터셋을 나누고 싶다면 수동으로 데이터셋을 나누는 매뉴얼 분할과 오토큐레이트의 학습/검증 데이터셋 선별(Split Train/Validation Set) 옵션을 함께 사용하는 것이 좋습니다. 그러면 보다 고품질의 검증용 데이터셋을 생성하고 학습 결과를 개선할 수 있으며, 모델 성능을 보다 효과적으로 평가할 수 있습니다. 다음으로 이미지가 담긴 큐레이트 데이터셋을 선택하고 모델에 이름을 부여한 뒤 학습을 시작하면 됩니다. 학습 현황은 내 모델(My models) 탭에서 살펴볼 수 있습니다. 최소 한 번의 학습 에폭(epoch)이 완료되면 현재 모델의 성능을 확인할 수 있으며, 우리 목적을 달성하기에 충분한 성능을 보유했다면 학습을 일찍 마무리할 수 있습니다.

모델 학습이 완료되면 내 모델(My models) 탭에서 학습 결과를 리뷰할 수 있습니다. 또한 학습된 모델에 대한 새로운 엔드포인트를 배포하거나 모델 진단을 통해 모델을 분석하고 성능을 개선할 수 있습니다.

슈퍼브 모델 클라우드 API로 모델 배포하기
모델을 학습했다면 다음은 프로덕션 환경으로 배포해야 합니다. 배포하는 방법 중 하나는 슈퍼브에이아이의 클라우드와 엔드포인트 API를 활용하는 것입니다. 이번 예시에서는 모델의 엔드포인트를 생성해 Lucid Vision 카메라에서부터 데이터를 스트리밍하고 실시간으로 인입되는 프로덕션 환경 데이터에 대해 추론을 실행해 보겠습니다.
먼저 모델의 슈퍼브 모델의 엔드포인트 생성(Create Endpoint) 옵션으로 모델의 엔드포인트를 생성합니다. 엔드포인트를 배포하면 수집한 이미지에 대해 추론을 실행할 수 있는 고유 URL이 제공됩니다. 이 URL을 통해 이미지를 학습된 모델로 전송해 실시간으로 예측을 생성할 수 있습니다.

아래 스크립트는 Lucid Vision Labs 카메라에서 이미지를 가져와 엔드포인트로 전송해 추론을 실행할 수 있는 스크립트로, 별도의 최적화 없이도 초당 10 프레임의 속도로 추론할 수 있습니다. 해당 추론 결과는 후속 모델 학습 이터레이션에 사용할 새로운 이미지 탐색에도 활용할 수 있습니다. 이번 예시에서는 신뢰 구간이 낮은 (예: 0.5 미만) 결함이 발생한 모든 이미지를 큐레이트 데이터셋으로 업로드하는 샘플 코드가 제공됩니다.
import requests
from requests.auth import HTTPBasicAuth
def run_inference(image_path):
image = open(image_path, "rb").read()
response = requests.post(
url="https://your_endpoint_url",
auth=HTTPBasicAuth(TEAM_NAME, ACCESS_KEY),
headers={"Content-Type": "image/jpeg"},
data=image,
)
return response
if __name__ == "__main__":
print("Starting image capture and inference...")
dataset = curate.fetch_dataset(name="Lucid Camera Data")
camera = initialize_camera()
for image_path in capture_image(camera):
response = run_inference(image_path)
if response.status_code == 200:
print("Inference result:", response.json())
#
# Perform some action based on the inference result, such
# as triggering an alert if a defect or anomaly
# has been detected.
#
# Additionally, we could upload all images that contain
# low confidence inferences of our defect class to our
# Curate dataset for our next round of training:
#
# low_confidence_inference_classes = [
# obj["class"] for obj
# in response["objects"] if obj["score"] < 0.5
# ]
#
# if "defect_class" in low_confidence_inference_classes:
# upload_image(image_path, dataset)
#
else:
print("Error: Failed to get inference result.", response.text)
system.destroy_device(camera)$ pip install --upgrade superb-ai-curate numpy opencv-python이렇듯 실시간 추론을 통해 지속적으로 결함을 모니터링할 수 있기 때문에 품질 관리에 상당히 유용합니다. 우리가 추론 엔드포인트에 학습하고 배포한 모델을 사용하면 검수 카메라에 촬영된 이미지들을 즉시 분석해 외관 결함, 정렬 오류, 또는 다른 유형의 결함을 실시간으로 탐지할 수 있습니다. 이를 알람 시스템과 연동하면 실시간 탐지 결과에 자동으로 결함 플래그를 부여해 품질관리팀에 경고를 보내거나 추가 문제를 방지하기 위해 생산을 잠시 중단할 수도 있습니다.

위 예시에서는 객체 탐지 모델을 사용해 의약품 용기의 결함을 탐지했습니다. 일부 통제된 환경이 필요한 산업의 경우 이렇게 클래식한 객체 탐지 파이프라인보다 효율적인 대안을 고려하는 것이 좋을 수 있습니다. 슈퍼브에이아이 팀은 결함 데이터가 아닌, 라벨링 되지 않은 정상 데이터 소량만으로도 우수한 성능의 이상 탐지 모델을 개발할 수 있습니다. 그렇기에 아래 예시와 같이 결함 발생 확률이 높은 부분을 히트맵으로 표시해 보여주는 고성능 모델을 훨씬 빠르게 배포할 수 있습니다. 해당 기능은 곧 출시될 예정입니다.
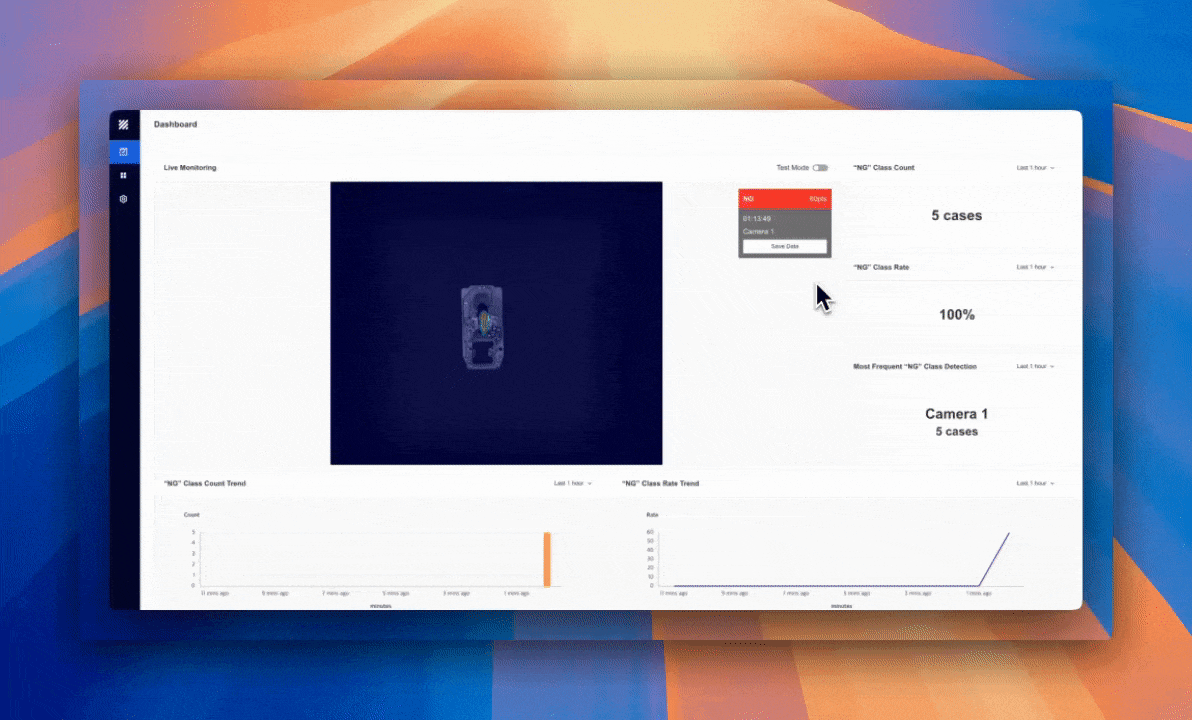
초기 모델 배포는 강건하고 효과적인 모델 파이프라인 구축의 첫 단추일 뿐입니다. 모델의 성능을 최고로 끌어올리기 위해서는 모델 성능이 저하되는 부분을 분석해 부분적이고 적확한 개선을 가능하게 하는 모델 진단과 같은 도구를 사용해 지속적으로 모델을 개선하는 과정이 필요합니다.
데이터셋에 새로운 현실 데이터를 채워넣고, 큐레이트 검색 도구와 오토큐레이트를 사용해 가장 유의미한 데이터를 검색하고, 슈퍼브 모델의 합성 데이터 생성으로 희소한 엣지 케이스를 생성하는 일련의 과정을 통해 모델의 정확성과 신뢰도를 보다 개선할 수 있습니다. 이런 기법들로 모델 학습 이터레이션을 반복하면 모델은 현실 시나리오에 대한 적응력이 높아져 실제 프로덕션 환경에서도 뛰어난 성능을 보여주게 됩니다.
지금 바로 시작할 수 있는 제조 불량 검수 AI 솔루션이 궁금하시다면, 슈퍼브에이아이와 함께 하세요. 아래 내용을 입력해 주시면 바로 연락 드리겠습니다.