[슈퍼브 인사이트] Figure AI 휴머노이드 81시간 라이브 데모, 박스 10만 개 무사고의 의미
Figure AI 휴머노이드 데모가 81시간 동안 박스 10만 개를 무사고 분류했습니다. 시가총액 54조 휴머노이드 기업이 라이브로 증명한 것은 무엇이며, Helix-02 신경망과 Project Go-Big 데이터 전략이 피지컬 AI 시대에 던지는 시사점을 정리합니다.

![[슈퍼브 인사이트] Figure AI 휴머노이드 81시간 라이브 데모, 박스 10만 개 무사고의 의미](https://storage.ghost.io/c/73/74/73741b5e-0bdf-4e6f-9161-743bc6f76d78/content/images/size/w2000/2026/05/ko-blog------------------------------------------------Figure-AI--------------------------------81---------------------------------------------------------------.png)
>> 뉴스레터 구독하기
🌟 SUPERB Spotlight
8시간이 81시간이 됐다 - Figure AI가 '쇼'를 '검증'으로 바꾼 24시간
지난 5월 13일, Figure AI CEO Brett Adcock은 X에 짧은 영상 하나를 올렸습니다.
F.03 휴머노이드 로봇 세 대가 컨베이어 벨트 옆에서 박스를 집어 바코드를 아래로 향하게 돌려놓는 영상이었는데요. 시청자들이 로봇에게 Bob, Frank, Gary라는 별명을 붙이며 캐릭터처럼 응원하기 시작했고, 24시간이 지났을 때 방송은 3M 조회수를 돌파했습니다. Adcock의 X 게시물이 결정타였습니다.
"원래 목표는 8시간 운영이었습니다. 어제 무사고 운영이 나오자 그냥 계속 가보기로 했습니다. 지금까지 24시간 이상 연속 자율 운영, 한 번의 실패도 없었습니다. 이건 미지의 영역(uncharted territory)입니다." — Brett Adcock, X (May 14, 2026)
업계는 일제히 멈춰서서 이 라이브 방송을 지켜봤습니다. 그리고 80시간이 지나도 로봇은 멈추지 않았습니다. (5월 19일 현재까지도 130 시간이 넘어가는 라이브 중입니다)

무엇이 다른가 - '시연 영상'에서 '라이브 검증'으로
휴머노이드 로봇 업계는 오랫동안 한 가지 비판을 받아왔습니다.
"잘 편집된 30초짜리 영상은 누구나 만들 수 있다."
실패한 테이크는 잘라내면 그만이고, 카메라 밖에서 사람이 개입했는지 시청자는 알 수 없으니까요.
사실 이번 라이브 데모도 그런 비판에서 시작됐습니다. 로봇 전문가 Scott Walter가 "휴머노이드 로봇이 인간처럼 긴 시간을 버틸 수 없다면 상업적 가치는 제한적"이라며 공개적으로 비판했고, Adcock은 이를 라이브 스트림으로 받았습니다. 방송에서 드러난 숫자들은 다음과 같습니다.
- 속도: 1박스당 약 3초 — 숙련된 인간 작업자와 거의 동일한 수준
- 24시간 만에: 28,000개 이상 박스 분류, 무사고
- 40시간 시점: 약 50,000개 박스 처리, 네 번째 로봇 'Rose' 합류
- 81시간 시점: 'Jim' 단독으로 101,391개 분류 — 첫 24시간 동안 단 한 건의 오류 없음
- 자율 운영: 배터리가 줄어들면 다른 로봇이 자동으로 교대, 충전소로 스스로 이동

주목할 점은 자율 회복 메커니즘입니다. 로봇이 멈추거나 학습 분포에서 벗어난 상황을 만나면, Helix-02가 자동 리셋을 트리거하고 인간 개입 없이 작업을 재개합니다. 컨베이어 벨트에서 박스가 옆으로 떨어지는 등 사소한 오류도 있었지만, 로봇은 스스로 자세를 바로잡고 작업을 이어갔죠.
물론 모두가 환호한 것은 아닙니다. 오하이오 주립 공과대학 학장 Ayanna Howard는 "인상적이지만 여전히 '과학 프로젝트(science project)'에 가깝다"고 평가했고, 컨베이어 벨트가 단일 루프로 같은 박스를 반복 처리한다는 점도 지적됐습니다. 그럼에도 짧은 클립이 아닌 수십 시간의 공개 검증이라는 형식 자체가 휴머노이드 산업의 신뢰성 기준을 끌어올렸다는 데에는 이견이 없습니다.
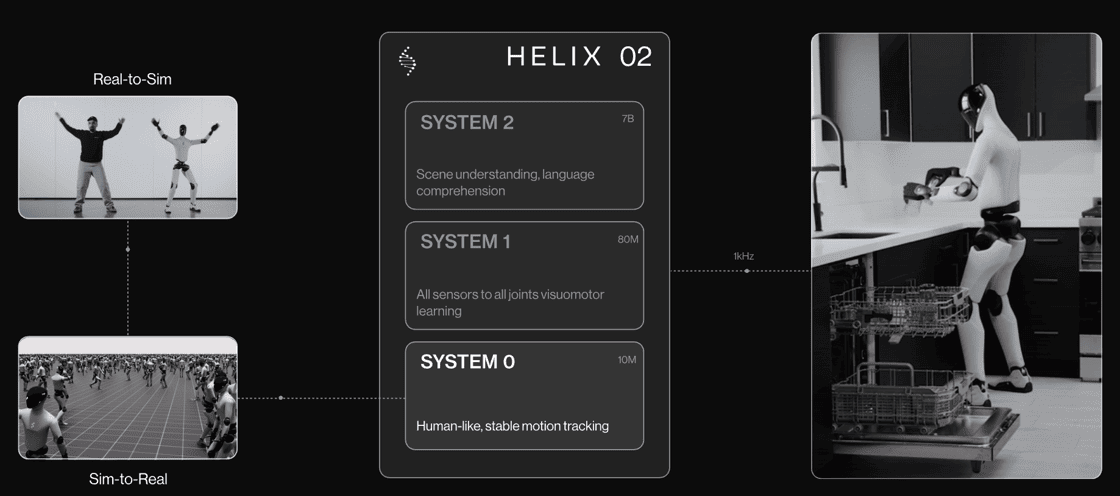
Helix-02, '109,504줄의 C++ 코드'를 대체한 단일 신경망
라이브 데모의 진짜 주인공은 박스도 로봇 하드웨어도 아닌, 그 모든 동작을 만들어내는 Helix-02입니다. 2026년 1월 공개된 Figure AI의 풀바디 자율 신경망 시스템인데요.
기존 휴머노이드 로봇은 보통 '걷기 컨트롤러 → 안정화 → 잡기 컨트롤러' 같은 모듈을 상태 머신으로 이어붙이는 방식이었습니다. 한 모듈이 무너지면 전체가 무너지는 취약한 구조였죠. Helix-02는 이를 정면으로 뒤집었습니다.
- System 0 (1 kHz): 1,000시간 이상의 인간 동작 데이터로 학습된 풀바디 컨트롤러. 균형, 접촉, 자세 조정 담당. 109,504줄의 수동 작성 C++ 코드를 단일 신경망으로 대체.
- System 1 (200 Hz): 헤드 카메라, 손바닥 카메라, 손끝 촉각 센서, 전신 자기수용 감각을 받아 전신 관절 명령 출력.
- System 2: 자연어 명령과 장면 이해를 통한 고차원 추론.
특히 손끝 촉각 센서는 3g 수준의 힘까지 감지해 약병 캡 풀기, 약통에서 알약 하나 꺼내기, 주사기로 정확한 용량 밀어내기 같은 정밀 작업까지 가능하게 합니다. 같은 신경망이 밀리미터 단위 손가락 움직임부터 방 전체를 가로지르는 보행까지 4자릿수 규모를 넘나드는 동작을 만들어내는 것이죠.
'OpenAI 결별'부터 'Project Go-Big'까지 - Figure AI의 1년
Figure AI의 이번 행보를 이해하려면 지난 1년의 전략적 결정들을 함께 봐야 합니다.
① 수직 통합 결정 (2025년 2월) — Figure AI는 OpenAI와의 협업을 중단했습니다. Adcock의 표현으로는 "실제 환경에서 임바디드 AI를 풀려면 로봇 AI를 수직 통합해야 한다"는 것. 외부 파운데이션 모델에 의존하면 경쟁사의 로드맵에 발이 묶인다는 판단이었습니다.
② 데이터 플라이휠 구축 (2025년 9월) — Figure AI는 글로벌 부동산 자산운용사 Brookfield와 손잡고 Project Go-Big을 발표했습니다. Brookfield의 100,000개 이상 주거 유닛, 5억 평방피트의 상업 오피스, 1.6억 평방피트의 물류 공간에서 인간의 1인칭 시점 영상을 수집해 '로봇판 YouTube'를 만들겠다는 구상입니다.
"모든 머신러닝 혁신은 거대하고 다양한 데이터셋에서 나왔다. 로보틱스에는 그런 것이 없어서 우리가 직접 만든다." 라는 Adcock의 발언이 전략을 압축합니다.
실제로 11월에는 로봇 데이터 없이 인간 영상만으로 학습한 모델이 자연어 명령("주방 식탁으로 걸어가")만으로 실제 집을 자율 주행하는 zero-shot transfer를 시연했습니다.
③ 기업 가치 390억 달러(2025년 9월) — 위 두 가지 전략을 등에 업고 Figure AI는 10억 달러 이상의 시리즈 C를 390억 달러 가치로 클로징했습니다. Parkway Venture Capital이 리드, Brookfield, NVIDIA, Salesforce, Qualcomm, T-Mobile, LG, Intel Capital이 참여했습니다.
④ 양산 본격화 (2025-2026) — BotQ 공장은 2025년 월 수 대 수준에서 2026년 4월 240대까지 생산을 끌어올렸고, 현재는 90분에 한 대 생산하는 페이스로 4년 내 누적 10만대 출하가 목표입니다. BMW Spartanburg 공장 파일럿에서는 11개월간 3만대 이상의 X3 차량 생산을 지원하며 9만개 이상의 부품을 처리한 실적도 있습니다.
⑤ 그리고 5월의 라이브 데모 — 이 모든 흐름은 5월의 81시간 방송으로 수렴됩니다. "우리는 진짜로 합니다" 라는 메시지를, 편집되지 않은 라이브 영상으로 증명한 것이죠.
여기에 인간 인턴 'Aime'와 F.03의 10시간 Man vs Machine 대결까지 펼쳤습니다. 결과는 12,924 vs 12,732(박스 개당 2.79초 vs 2.83초) — 인간이 근소하게 이겼는데요.
Adcock은 "이게 인간이 이기는 마지막 순간일 것"이라는 코멘트를 남겼고, Aime는 "왼쪽 팔이 부러진 것 같다"고 농담했습니다. 로봇은 다음 날에도 작업을 이어갔습니다.

엔터프라이즈가 주목해야 할 시사점
'ChatGPT 모먼트'가 물리적 세계로 확장되는 지금, Figure AI의 사례는 단순한 기술 마일스톤을 넘어 피지컬 AI 도입을 검토하는 모든 기업에게 세 가지 신호를 보냅니다.
첫째, 휴머노이드 평가의 잣대가 '데모 영상'에서 '연속 운영'으로 옮겨갑니다.
8시간 → 24시간 → 81시간으로 시간 단위가 커질수록, 진짜 질문은 "할 수 있느냐"가 아니라 "몇 시간 동안, 몇 번 실패 없이, 어떤 운영 비용으로 할 수 있느냐"로 바뀝니다. PoC 단계에서 만들어진 단발성 데모 영상의 신뢰도는 빠르게 낮아질 것이고, 장시간 무인 운영 가능성과 자율 회복 메커니즘이 도입 의사결정의 핵심 기준이 됩니다.
둘째, '데이터 파이프라인'이 경쟁의 본질로 부상합니다.
Helix-02가 109,504줄의 코드를 단일 신경망으로 대체할 수 있었던 건 1,000시간의 인간 모션 데이터가 있었기 때문입니다. Project Go-Big이 10만 가구의 영상을 수집하는 것도 같은 이유죠.
"로봇 데이터는 인터넷에서 긁어올 수 없다"는 관측대로, 양질의 물리 세계 데이터, 특히 시뮬레이션·합성 데이터 파이프라인을 확보한 기업만이 일반화 성능에서 격차를 만듭니다.
셋째, 휴머노이드 도입 검토는 '내년의 일'에서 '올해의 일'로 당겨졌습니다.
이미 BMW, GXO Logistics, Mercedes-Benz 같은 대기업이 휴머노이드 파일럿을 진행 중이고, Apptronik·Agility Robotics·Tesla Optimus·1X 등 경쟁자들도 빠르게 움직이고 있습니다.
슈퍼브에이아이 역시 피지컬 AI의 핵심 과제인 고품질 학습 데이터 구축에 집중하고 있습니다. 3D 가우시안 스플래팅 기반 디지털 트윈 자산화, NVIDIA Isaac Sim 기반 합성 데이터 파이프라인 구축 등 'Sim-to-Real 갭'을 줄이기 위한 기술을 현장에 적용 중인데요.
Figure AI가 만드는 '로봇의 몸과 뇌' 가 실제 산업 환경에서 의미 있게 동작하려면, 그것을 학습시킬 양질의 데이터와 검증 인프라가 반드시 함께 준비되어야 합니다. 라이브 스트림에서 본 81시간의 무사고 운영은 결국 그 뒤에 있는 1,000시간의 인간 데이터, 100,000가구의 영상, 200,000개의 병렬 시뮬레이션 환경이 만든 결과니까요.
지금 이 순간에도 "우리 조직이 휴머노이드 시대에 활용할 수 있는 데이터 자산은 무엇인가?" 를 묻는 것이 가장 현실적인 준비가 아닐까 합니다.
✏️ SUPERB Curation
슈퍼브 장태웅 ML Engineer 의 추천:
Nano-Banana 기반 instruction tuning으로 SAM 계열을 뛰어넘는 세그멘테이션 성능 달성
최근 공개된 연구에서는 이미지 생성 모델인 Nano-Banana를 instruction tuning 방식으로 학습시켜, 기존 범용 세그멘테이션 모델인 SAM 계열보다 더 높은 성능을 달성한 결과를 발표했습니다. 단순히 객체를 분리하는 수준을 넘어, 사용자의 자연어 지시를 이해하고 보다 정교한 세그멘테이션 결과를 생성할 수 있다는 점이 특징인데요.
특히 이 연구는 생성형 비전 모델이 단순 생성 작업을 넘어, 세그멘테이션과 같은 픽셀 단위 비전 태스크까지 확장될 수 있음을 보여줍니다. 기존 SAM 모델들이 범용성과 빠른 추론에 강점이 있었다면, 이번 접근은 instruction tuning을 통해 복잡한 사용자 의도를 반영한 세밀한 분할 성능을 강화했습니다.
이는 앞으로 비전 AI가 “객체를 찾는 모델”에서 나아가, 사용자의 의도를 이해하며 장면을 해석하는 방향으로 발전하고 있음을 시사합니다. 생성형 모델과 비전 모델의 경계가 점점 흐려지고 있다는 점에서도 흥미로운 연구입니다. 하는데요. Gemini API와 Google AI Studio를 통해 지금 바로 사용할 수 있습니다.