자연어 처리(NLP)는 왜 어려울까?

1. 자연어와 인공어 그리고 자연어 처리의 정의
세상에는 두 가지 종류의 언어가 있다. 하나는 우리가 일상적으로 쓰는 의사소통을 위한 언어다. 언제부터, 왜, 무엇을 계기로 인류가 언어를 쓰기 시작했는지 명확하지는 않지만 이러한 언어를 자연적으로 발생했다고 하여 자연어(Natural Language)라고 부른다. 한국어, 영어, 독일어, 프랑스어 등 우리가 알고 있는 거의 모든 언어는 자연어의 범주에 속한다.
또 다른 언어는 어떠한 목적을 가지고 만들어진 언어로, 인공어(Artificial Language)라고 하는데, C++, Python, Java 등 인간이 컴퓨터를 편하게 조작하기 위해 만들어낸 프로그래밍 언어는 물론이고 국제적인 의사소통을 원활하게 하기 위해 만들어진 언어인 에스페란토(Esperanto)와 같이 사람이 만들어낸 언어는 모두 이 범주에 속한다. 인공어는 명확한 규칙이 있고 패턴화하기 쉽다는 특징이 있다.
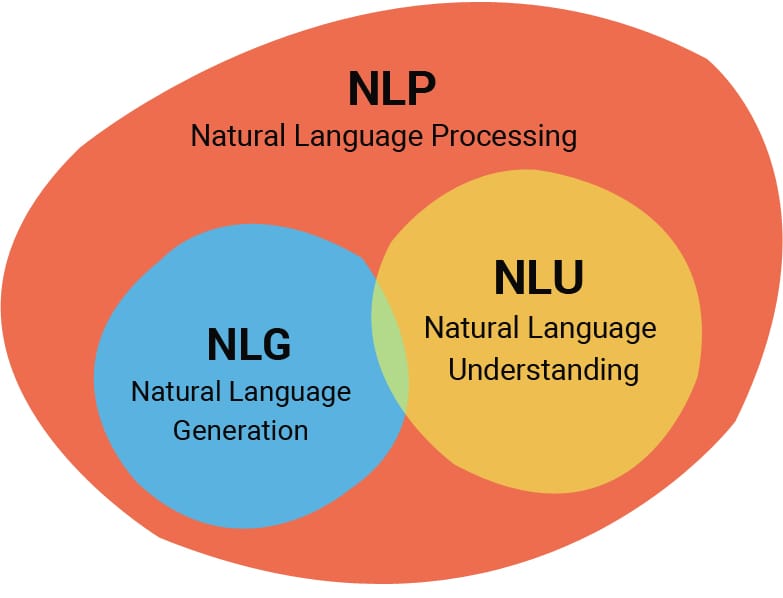
자연어 처리(NLP, Natural Language Processing)란 자연적으로 발생한 인간의 언어를 컴퓨터가 보다 자연스럽게 이해하고 생성해 낼 수 있도록 하는 인공지능의 한 가지 분야다. 자연어 처리(NLP)는 또다시 자연어 이해(Natural Language Understanding, NLU)와 자연어 생성(Natural Language Generation, NLG)로 나뉘는데, 이를 위해 다양한 테크닉과 방법론에 관한 다양한 논문들이 지금 이 순간도 끊임없이 쏟아져 나오고 있다.
2. 자연어 처리가 어려운 이유
문제는 우리 인간의 언어가 여타 비정형 데이터(Unstructured Data)와는 다르게 패턴화하고 수치화하기에 매우 어려움에도 불구하고 이미지 처리(Image Processing)이나 시계열 데이터 분석(Time Series Analysis) 등 다양한 분야의 인공지능에 적용되는 것과 마찬가지로 통계학과 딥러닝에 많은 부분을 의존한다는 사실이다.
물론 최근에는 챗GPT 등 초거대언어모델(LLM)은 방대한 양의 텍스트로 된 학습 데이터와 편향(Bias)와 가중치(Weight)를 이용한 랜덤성 부여를 통해 이러한 문제를 해결하고자 했으나 인간의 언어를 컴퓨터가 구사하도록 하는 일은 여전히 어려운 일이다. 이번 시간에는 자연어 처리를 어렵게 만드는 인간 언어 고유의 난해함에 대해 알아보자.
1) 자연어의 불완전성
자연어는 시시각각 변화하며 그 자체로 완벽하지 않다. 동일한 문장이 다양한 상황 속에서 전혀 다른 의미로 해석되기도 하며, 이러한 언어의 특징은 언어의 보편적인 규칙을 찾아내고 패턴화하려는 언어학자들의 노력을 무력하게도 한다. 또한 사람들은 어순이 뒤죽박죽이거나 문법적으로 정확하지 않은 문장을 가지고도 의사소통이라는 본연의 목적을 훌륭하게 달성해 내기도 한다. 하지만 컴퓨터는 그렇지 않다. 자연어 처리가 어려운 이유다.

2) 인간 커뮤니케이션의 즉흥성
커뮤니케이션은 인간의 본능적인 활동 중 하나이며, 그 즉흥적인 성격은 언어의 다양성을 만들어낸다. 우리는 맥락, 감정, 상황에 따라 같은 단어를 다르게 사용하며, 때로는 새로운 단어나 의미를 창조하기도 한다. 이는 인간 간의 대화가 동적이며 창의적인 특성을 갖고 있음을 의미한다. 그러나 이러한 즉흥성은 컴퓨터에게는 예측 불가능한 요소로 작용하여 자연어 처리를 더욱 복잡하게 만든다.
3) 언어의 다의성과 문맥의 중요성
언어의 또 다른 복잡한 요소는 다의성이다. 하나의 단어나 문장이 상황에 따라 여러 가지 의미를 가질 수 있다는 것이다. 예를 들어 "배"라는 단어는 과일의 이름일 수도 있고, 배를 타고 가는 행위를 의미할 수도 있다. 컴퓨터가 이러한 뉘앙스를 정확히 이해하기 위해서는 문맥이 매우 중요하다. 따라서 NLP 시스템은 문맥을 파악하고 해석하는 능력이 필수적이다.
4) 비표준적 표현과 비정형 데이터
인터넷과 SNS의 보급으로 비표준적 언어 사용이 일반화되고 있다. 줄임말, 이모티콘, 신조어 등은 비정형 데이터의 형태로 나타나며, 이는 전통적인 언어 규칙을 따르지 않는다. 컴퓨터가 이러한 비정형 데이터를 이해하고 처리하는 것은 상당한 도전 과제이다.
결론적으로, 자연어 처리의 복잡성은 언어 자체의 불완전성, 즉흥성, 다의성, 그리고 비정형적 특성에서 기인한다. 이러한 문제들을 해결하기 위해, 연구자들은 기계 학습 모델을 지속적으로 발전시키고 있으며, 더욱 진보된 알고리즘을 개발하여 컴퓨터가 인간의 언어를 더욱 정교하게 이해할 수 있도록 노력하고 있다. 그러나 인간의 언어가 가진 복잡함과 미묘함을 완전히 모방하는 것은 아직까지도 컴퓨터 과학의 한계를 보여주는 과제로 남아 있다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.