챗GPT 이외의 LLM에는 어떤 것들이 있을까?: 초거대언어모델의 경량화 트렌드

OpenAI사의 챗GPT는 LLM 시장의 대중화를 향한 첫 문을 열었다는 점에서 생성형 언어모델의 선구자라고 할 수 있다. 그러나 당연하게도 LLM에는 챗GPT만 있는 것이 아니다. 이번 시간에는 구글과 Meta를 비롯한 다양한 빅테크 기업들이 사용자들의 니즈에 맞게 야심차게 준비한 ‘챗GPT 이외의 초거대언어모델’들에 대해 알아보도록 하겠다.
주목할 점은 매개변수와 훈련 데이터를 늘려가며 성능을 개선해오던 기존의 ‘언어모델 초거대화’ 트렌드가 바뀌고 있다는 점이다 적은 매개변수와 훈련 데이터만 가지고도 최대한의 가격대비 성능을 낼 수 있는 sLLM(small Large Language Model)의 출현과 함께 언어모델이 점점 더 경량화 되고 있다는 점이다.
1.메타의 LLaMA 시리즈와 오픈이노베이션 전략
Meta는 자체 개발한 초대형 언어 모델(LLM)인 LLaMA의 소스코드를 공개하는 방식으로 오픈소스 전략을 적극적으로 추진하고 있다. 이를 통해 다양한 프로젝트에서 LLaMA를 원하는 목적에 맞게 커스터마이징하여 사용할 수 있게 되었다. 현재까지 LLM의 소스코드를 공개하고 있는 기업은 메타가 유일하며, 이런 개방성과 투명성 덕분에 메타는 인공지능 분야의 LLM 개발 프로젝트에서 가장 주목받고 있는 빅테크 기업 중 하나로 자리매김하고 있다.
작지만 강력한 LLM, LLaMA(Large Language Model Meta AI)
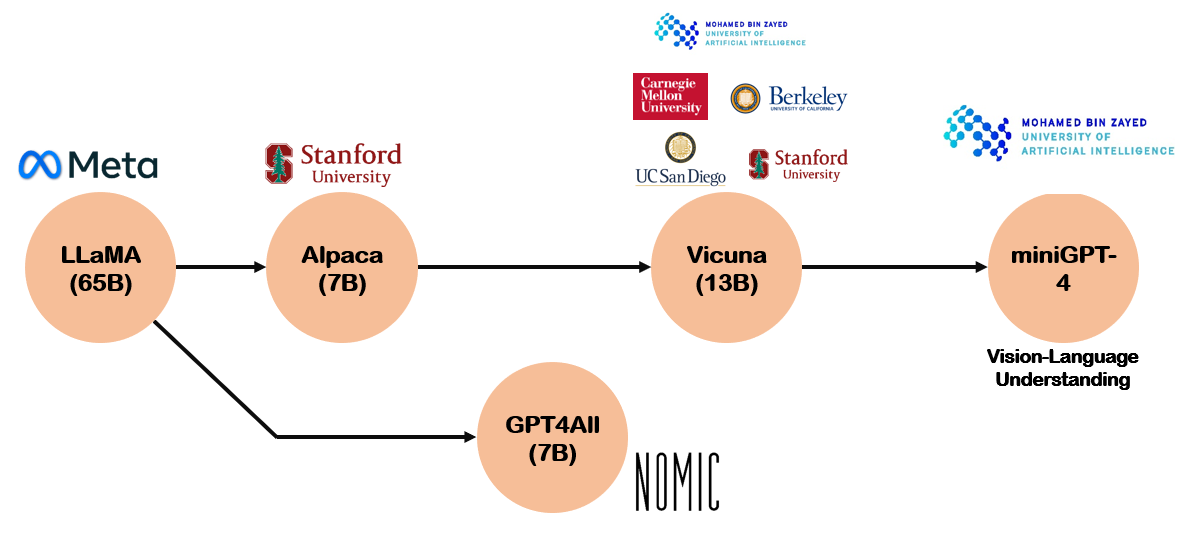
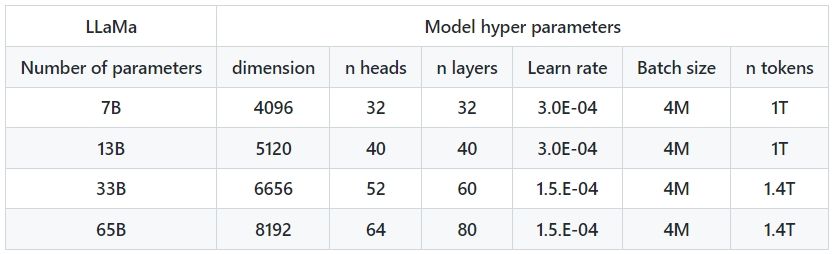
메타의 LLaMA는 70억, 130억, 330억, 650억개의 매개변수를 가지는 네 가지 모델로 구성되어 있다. 이 모델들은 1750억개의 매개변수를 가진 GPT-3.5와 비교했을 때 매개변수 수가 적지만, 그럼에도 불구하고 높은 성능과 모델 학습의 유연성을 자랑하며 개발자들 사이에서 인기를 끌고 있다.
LLaMA의 활용성과 유연성
LLaMA의 다른 큰 장점은 그 용량이다. 이 모델은 용량이 다른 모델의 10분의 1 수준에 불과하기 때문에 고성능 GPU뿐만 아니라 다양한 엣지 디바이스, 예를 들어 스마트폰 등에서도 AI 생성을 구현할 수 있다는 점에서 매력적이다. 이런 특징은 특정 목적에 맞게 개발되는 소규모 초대형 언어 모델(sLLM)의 개발에도 큰 도움이 된다.
LLaMA(Large Language Model Meta AI) 2의 출시
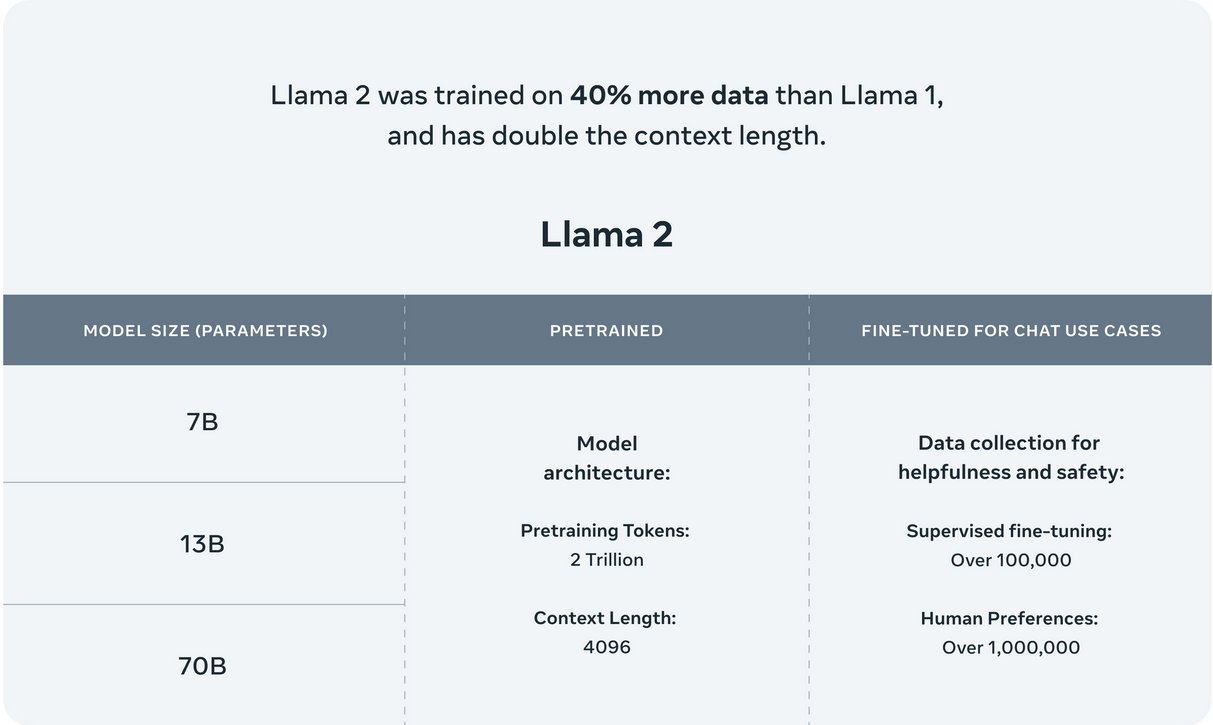
메타는 2023년 7월에 LLaMA2를 선보였다. 이 새로운 모델은 주목할 만한 특징들을 가지고 있다. 첫째, 사전 학습 말뭉치(pre-training corpus)가 1조 4천억개에서 2조개로, 약 40% 증가하였다. 이는 모델의 학습 데이터 범위가 크게 확장되었음을 의미하며, 이로 인해 모델의 성능과 다양성이 향상될 가능성이 있다.
둘째, LLaMA2는 라이선스 사용에 있어서 이전 버전인 LLaMA와 비교하여 확연한 차이를 보였다. 초기 LLaMA는 연구원, 학계, 정부 및 시민 단체 등에게 비상업적 목적으로만 일부를 공개하였다. 반면, LLaMA2는 상용 활용이 가능한 라이선스로 공개되었다. 이는 메타가 LLaMA2를 연구뿐만 아니라 다양한 상용 환경에서도 활용할 수 있도록 허용함으로써, LLM의 사용 범위를 확장하려는 의도를 보여준다.
2. 구글의 LaMDA와 PaLM 2
구글은 2017년 'Transformer' 모델을 개발하며 'attention is all you need'라는 논문을 통해 LLM의 선구적인 역할을 했다. 최근에는 자체 개발한 초거대 언어 모델인 LaMDA(Language Model for Dialogue Applications)를 기반으로 한 서비스인 Bard를 출시했고, OpenAI의 챗GPT에 대응하기 위해 매개변수를 늘리고 성능을 개선했다는 PaLM2를 선보이기도 했다.
LaMDA
LaMDA는 'Language Model for Dialogue Applications'의 줄임말로, 대화를 위한 언어 모델을 가리킨다. 이전 언어 모델인 BERT와 GPT는 각각 언어 이해와 언어 생성에 중점을 두었지만, LaMDA는 언어 이해와 생성을 모두 통합해 대화에 중점을 두는 언어 모델을 만들었다. 이 특징은 LaMDA가 자연스러운 대화 생성과 이해에 초점을 맞춰 더욱 발전된 대화형 AI 어플리케이션의 개발을 가능하게 한다.
LaMDA는 약 1370억 개의 매개변수로 이루어진 대형 Transformer 모델로, GPT와 매우 유사하다. 일반적인 언어 모델처럼 텍스트가 입력되면 그 다음 단어를 예측하는 방식으로 학습된다. 또한, LaMDA는 대량의 텍스트 데이터로 학습되었으며, 이 과정은 사전학습(Pre-training)이라고 한다. 약 30억 개의 문서와 11억 개의 대화(총 134억 개의 개별 발언)를 학습 데이터로 사용하였다. 이러한 점은 GPT 등 다른 모델과 차이가 없다.
챗GPT의 기반이 되는 모델이 GPT-3.5라면, 구글의 대표적인 대화형 언어 모델 서비스인 Bard의 기반이 되는 초거대 언어 모델이 바로 LaMDA라고 할 수 있다.
PaLM2

Bard의 LLM인 LaMDA는 출시 이후 추론 및 언어 생성 능력에서 ChatGPT를 따라잡지 못한다는 비판을 받아왔다. 이러한 단점을 보완하기 위해, 구글은 최근 LaMDA의 한계를 개선한 LLM인 PaLM2 (Pathways Language Model 2)를 선보였으며, 이를 통해 '왕의 귀환'을 기대하고 있다.
PaLM2는 약 5400억개의 매개변수를 가진 초대형 언어 모델이다. 이는 GPT-3의 1750억개에 비해 약 3배에 달하는 매개변수 수를 보유하고 있으며, 이 덕분에 다양한 자연어 처리(NLP) 벤치마크에서 최고 점수를 기록하였다. 이런 결과는 모델의 규모가 클수록 성능이 향상되는 가설이 아직까지도 유효하다는 것을 입증하였다.
3. 그밖의 sLLM(small Large Language Model)
최근에는 모델명이 초거대언어모델이라는 표현과는 모순되게, ‘작은 초거대언어모델’이 주목받고 있다. 이는 언어 모델의 매개변수(parameter)를 줄이고 비용을 절약하는 동시에 미세조정(fine-tuning)을 통해 정확도를 높이는 '맞춤형 LLM'이라는 개념을 포함하고 있다. 초대형 언어 모델(sLLM)의 등장은 앞서 설명했던 Meta의 LLaMA의 출시를 시작으로 했다. 메타는 기본 버전인 66B(매개변수 650억 개)와 함께 다양한 크기의 '라마' 버전을 출시했는데, 이 중에서 가장 작은 모델의 매개변수는 단지 70억개(7B 버전)에 불과했다.
메타는 매개변수 수를 늘리는 것이 아닌, LLM 학습에 사용되는 텍스트 데이터 단위인 토큰의 양을 증가시키는 방법을 택하여 모델의 품질을 향상시켰다고 밝혔다. 이 방식은 LLM의 훈련 과정에서 토큰의 양을 늘리면서 모델의 성능을 개선할 수 있음을 보여주었고, 단순히 매개변수의 수를 늘리는 것이 아닌 다른 방식으로 모델의 품질을 높이는 가능성을 제시하였다.

스탠포드 대학교 연구팀은 라마 7B를 기반으로 한 초대형 언어 모델(sLLM) '알파카'를 개발하여 공개하였다. 그리고 이와 병행해서, AI 칩 전문 기업인 세레브라스 역시 다양한 형태의 sLLM 모델들을 선보였다. 이 중에서 주목받는 모델은 지난주에 갓잇AI가 출시한 '엘마'라는 sLLM 모델로, 이는 특히 사내 구축형(온프레미스) 서비스를 제공한다는 점에서 독특하다.
이런 형태의 서비스는 클라우드 기반 서비스와는 달리, 기업의 민감한 데이터가 외부에 노출되는 것을 방지하면서 머신러닝 연산을 수행하는데 최적화된 구조를 가지고 있다. 이를 통해, 엘마는 데이터 보안에 민감한 기업들이 자체 데이터를 안전하게 활용하여 머신러닝 모델을 학습시킬 수 있는 환경을 제공하며, 이는 다른 sLLM 모델들이 제공하지 못하는 독특한 가치를 제공한다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.