ChatGPT 유행이 가지는 의미 (1) – GPT와 ChatGPT


최근 인공지능 분야에서 가장 핫한 키워드를 하나만 뽑으라면 단연 ChatGPT일 것입니다. ChatGPT는 사용자와 문답이 가능한 인공지능입니다. 그 무엇이든 궁금한 질문을 ChatGPT에게 던지면 ChatGPT는 그럴듯한 답변을 내놓습니다. 이러한 ChatGPT는 인공지능 분야에서 가장 유명한 LLM입니다. LLM(Large Language Model)은 초대용량의 언어 데이터를 기반으로 대화, 번역, 문장 생성 등 언어 관련 목적으로 생성된 인공지능을 의미합니다. 단연코 최근 ChatGPT는 LLM, 그리고 인공지능 중 가장 유명하면서 유행을 이끄는 인공지능 모델입니다.
최근 인공지능 업계는 ChatGPT를 기점으로 많은 변화가 일어나고 있습니다. 생성형 모델이라는 일반인들에게 낯선 인공지능 모델의 유명세를 떨쳐주게 해주었으며, ChatGPT를 시작으로 많은 기업들은 LLM 생성에 집중하기 시작했습니다. ChatGPT를 기점으로 사람들이 인공지능을 바라보는 관점에도 변화가 생기기 시작했습니다. 너무나도 만능으로 보이는 ChatGPT는 사람들에게 인공지능의 잠재력을 어필하고 있으며, 인공지능에 대한 두려움 및 기대감을 동시에 증폭시켜주고 있습니다. ChatGPT가 이끄는 이 유행은 비단 하나의 인공지능 알고리즘 유행이 아니라 우리 사회를 변화시킬 수도 있습니다.
ChatGPT 알고리즘의 역사
이렇듯 ChatGPT는 최근 인공지능 업계를 이해하는데 있어 가장 중요한 알고리즘입니다. 여기서 사람들이 오해하는 것이 한가지 있습니다. 바로 ChatGPT가 어느 날 갑자기 등장하여 우리에게 큰 충격을 가해주고 있다는 내용입니다.
하지만 이는 분명 사실이 아닙니다. 사실 2018년부터 ChatGPT의 전신이 되는 알고리즘이 꾸준히 발표가 되었습니다. 아래 그림과 같이 ChatGPT는 2018년에 등장한 GPT를 그 기반으로 합니다. Generative Pre-trained Transformer라는 이름의 GPT 알고리즘은 2018년 첫 등장을 이후로 꾸준히 발전을 하여 지금의 ChatGPT 및 GPT-4에 이르게 되었습니다.

알고리즘적으로 초기 등장한 GPT-1과 지금의 ChatGPT에 엄청난 차이는 없습니다. 몇몇가지 세부적인 변화나 대용량 데이터의 활용, Fine-Tuning라는 특정한 보정 작업이 GPT-1 출시 이후 이루어졌을 뿐입니다. 그렇기에 ChatGPT를 정확하게 이해하기 위해서는 사실 앞선 알고리즘들인 GPT-1, GPT-2, GPT-3에 대한 이해가 필요합니다. 하지만 인공지능 전문가를 목표로 하지 않는 이상 이 알고리즘의 세부 작동 원리를 모두 상세하게 이해하고 있을 필요는 없습니다.
우리는 GPT라는 알고리즘이 대체 무엇인지, 그리고 ChatGPT는 어떤 변화를 받아들였기에 이렇게 강력한 인공지능으로 탈바꿈할 수 있었는지에 대해서만 알면 됩니다. 대략적으로라도 ChatGPT의 작동 원리를 이해하는 것은 꽤 고차원적인 이야기가 될 수 있습니다. ChatGPT 그 자체에 대한 이해가 선행된다면, 우리는 ChatGPT가 앞으로 얼마나 더 유행을 이끌지, 그리고 그 한계는 무엇일지에 대해 대략적인 감을 잡을 수 있습니다.
Generative Pre-trained Transformer
ChatGPT는 GPT-1, 2, 3을 기반으로 합니다. 그리고 이 모든 알고리즘에는 공통적으로 GPT라는 말이 들어있습니다. GPT는 Generative Pre-trained Transformer의 약자로 직역하자면 사전 훈련된 생성적인 변압기라는 다소 어색한 표현으로 번역됩니다. 사실 Generative와 Pre-trained, Transformer라는 말은 모두 텍스트 관련 인공지능인 자연어처리 분야에서 특정한 의미를 지닙니다.
Generative는 특정한 결과물을 새롭게 생성해 내는 알고리즘을, Pre-trained는 사전에 훈련된 데이터 셋을 이용한다는 것을, Transformer는 Self-attention이라는 모델을 사용한 알고리즘을 의미합니다. 즉 ChatGPT의 기반이 되는 GPT는 데이터를 사용하되 사전에 훈련이 되어있는 데이터 셋을 사용하고, 그 결과로 새로운 텍스트를 생성하는 것을 주요 목적으로 합니다. 그리고 사용되는 알고리즘의 핵심은 Transformer(self-attention)입니다.
사실 GPT라는 이름에 담긴 의미만 잘 이해하더라도 ChatGPT와 GPT 자체가 무엇인지는 쉽게 알 수 있습니다. 물론 이 이름의 의미를 정확히 아는 것 자체가 인공지능에 대한 학습 없이는 어려운 영역이기는 합니다.
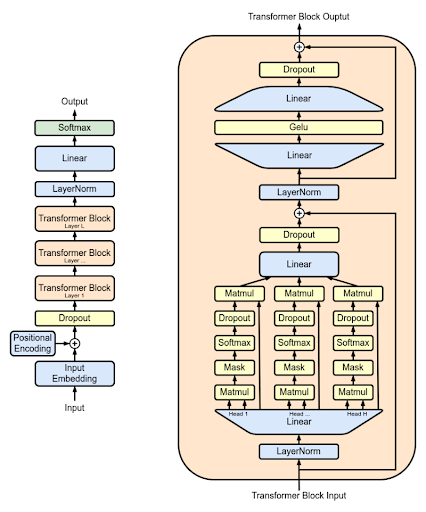
구체적으로 GPT는 위 그림과 같이 세부 구조를 가지고 있습니다. 이 구성 요소 하나하나가 모두 인공지능 전문 지식을 요구하는 개념이기에 이 세부 구조를 모두 이해하기는 어려울 수 있습니다. 하지만 우리가 GPT를 비롯하여 ChatGPT의 핵심 원리를 알기 위해 이해해야 하는 것은 명확합니다.
ChatGPT는 GPT에 기반하였으며 그러한 GPT는 Transformer라는 매우 복잡한 알고리즘을 이용하고 있으며, 이미 사전에 훈련된 데이터셋을 사용하고 있고(구체적으로는 일반적으로 인공지능 학습에 사용되지 못하는 Unlabeled data를 활용) 새로운 텍스트의 생성을 그 목적으로 한다는 점입니다. 여기서 한 번 더 중요한 사실만을 추려보면 GPT는 인공지능의 수많은 영역 중에 “생성” 영역에 집중하고 있으며, 원활한 텍스트 생성을 위해 사전 학습된 대량의 데이터를 이용합니다.
GPT-2 & GPT-3
하지만 대다수의 신규 모델과 비슷하게 GPT 역시 처음부터 큰 주목을 받지는 못했습니다. Fine-Tuning이라는 모델의 구체적 업무를 위한 세부 조정 단계를 생략한 GPT-1은 성능에 있어 많은 한계가 있었습니다. 그리고 이러한 GPT-1의 문제를 해결하기 위해 연이어 GPT-2와 GPT-3가 출시되었습니다.
상대적으로 GPT-3에 비해 GPT-2는 많은 관심을 끌지 못했습니다. 웹 상에 존재하는 데이터를 수집하여 인공지능 생성에 활용했다는 새로운 시사점을 가지는 모델이기는 했지만 기본적으로 인공지능 모델의 성능(정확도) 자체가 훌륭한 수준이 되지 못하였기 때문입니다. 그리고 이러한 문제를 GPT-3부터 원활하게 해결하기 시작했고 세상에 GPT라는 모델이 점차 널리 알려지게 되었습니다.

GPT 시리즈 알고리즘 비교
GPT-3는 알고리즘적으로 GPT-1과 GPT-2와 크게 다르지 않습니다. 이는 ChatGPT를 포함한 모든 GPT 시리즈에서 동일하게 적용되는 이야기입니다. 하지만 앞서 GPT-3부터는 그 성능에 우수함이 있어 세상에 널리 알려지게 되었다고 말했습니다. GPT-3이 앞선 GPT시리즈와 달랐던 점은 바로 인공지능 모델 생성에 활용하는 빅데이터의 양이었습니다.
기존의 GPT시리즈와 유사한 알고리즘을 유지한 채 인공지능 모델 학습에 사용되는 빅데이터 및 모델의 파라미터 양을 어마어마하게 늘렸습니다. 인공지능 모델의 파라미터라는 것을 직관적으로 이해하기 어려울 수 있으나, 인공지능이 특정한 결과물을 출력해내기 위해 조정하는 “변수” 정도로 이해할 수 있으며, 파라미터의 수가 많을수록 인공지능 모델은 정밀한 성과를 낼 수 있으며 또한 파라미터의 수가 많기 위해서는 대량의 빅데이터가 필요합니다. 즉, 발전된 알고리즘에 더불어 엄청난 양의 빅데이터가 GPT-3를 탄생시켰고 이때부터 사람들은 대화, 시나리오 등 GPT가 생성해내는 감쪽같은 텍스트에 집중하기 시작했습니다.
ChatGPT의 탄생
그리고 GPT-3는 다시 ChatGPT 탄생의 기반이 됩니다. 정확히는 GPT-3를 기반으로 GPT-3.5를 만들었고 GPT-3.5를 기반으로 탄생하게 된 것이 ChatGPT입니다. GPT-3에서 ChatGPT가 탄생한 것에 인공지능 모델을 생성하는 방법론적인 혁신이 있었다고 보기는 어렵습니다.
다만 번역이나 작문, 시나리오 생성 등 매우 다양한 목적을 가지고 탄생된 GPT에게 “채팅”이라는 특정한 목적만을 부여해 세부 성능을 향상시키며 GPT-3.5 및 ChatGPT가 탄생하였습니다. 아무래도 모든 업무를 다 잘하게 만들려는 것 보다는 특정한 하나의 업무부터 전문성을 가지게 하는 것이 일반적인 사고흐름 상 훨씬 쉬우며, 이는 인공지능 모델 생성의 영역에서도 마찬가지로 적용되는 이야기였기 때문입니다.
이러한 탄생 배경을 가지고 태어난 ChatGPT는 출시되자마자 엄청난 충격을 선사했습니다. 인공지능이라는 용어가 탄생한지는 제법 시간이 지났지만, ChatGPT 이전까지의 인공지능은 아직 사람들에게 우스운 수준이었습니다. 어떤 일을 하던 인공지능이 하는 일이 사람보다 낫다는 인식을 가지기는 힘들었습니다.
하지만 ChatGPT가 채팅 속에서 만들어내는 대답은 너무나도 자연스러우며 해당 대답을 사람이 한 것인지, 기계가 한 것인지 구분을 힘들게 합니다. 그리고 단순히 특정 지식을 묻거나, 일상 대화를 하는 것을 넘어 프로그래밍 코드를 작성해주는 등 그 활용성에 있어서도 큰 혁신이 일어났습니다. 결국 GPT시리즈는 ChatGPT라는 괴물 인공지능을 만들어내는 것에 성공했고, 이 ChatGPT는 단순 인공지능 업계 뿐 아니라 모든 사람들에게 많은 생각해볼 거리를 안겨주며 하나의 트렌드로 자리를 잡게 되었습니다.
왜 ChatGPT는 유행을 이끌게 되었을까?
ChatGPT가 많은 사람들에게 충격을 주었다는 점과 하나의 트렌드를 이끌고 있다는 사실은 그 누구도 부정하기 힘듭니다. 하지만 생각해보면 의문이 따를 수밖에 없습니다. 지금 이 시간에도 새로운 인공지능 알고리즘은 끝없이 출시되고 있고 새로운 인공지능 알고리즘은 각각마다 다양한 장점을 지니고 있습니다.
하지만 대부분의 새로운 인공지능 알고리즘은 일반 사람들에게 인식되지도 않을뿐더러 유행을 이끌지도 못합니다. 그렇다면 과연 ChatGPT는 도대체 무엇이 특별해서 이렇게 유행을 이끄는 존재가 될 수 있었을까요? 다음 시간에는 ChatGPT가 도대체 어떤 유행을 이끌었는지, 그리고 왜 ChatGPT가 이러한 유행을 이끌었는지를 오늘 살펴본 ChatGPT의 히스토리에 기반하여 알아보도록 하겠습니다.
| ||

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.