벡터 스토어로 LLM 백배 활용하기


요즘 언어모델 개발자들 사이에서 가장 핫한 라이브러리를 하나 뽑으라면 바로 Langchain이 아닐까 싶다. 2022년 10월 오픈소스로 세상에 공개된 LangChain은 초거대언어모델(LLM)을 사용하여 애플리케이션 생성을 단순화하도록 설계된 프레임워크다.
Langchain은 챗GPT 뿐만 아니라 메타의 LLaMA 시리즈와 구글의 Bard 등 다양한 LLM에 적용이 가능할 뿐만 아니라, faiss나 chromadb와 같은 벡터 데이터베이스를 활용하여 방대한 양의 DB속 정보와 인컨텍스트 러닝(In-context Learning)을 활용하여 사용자의 질문에 훨씬 더 적합한 답을 하는 기능을 제공한다.
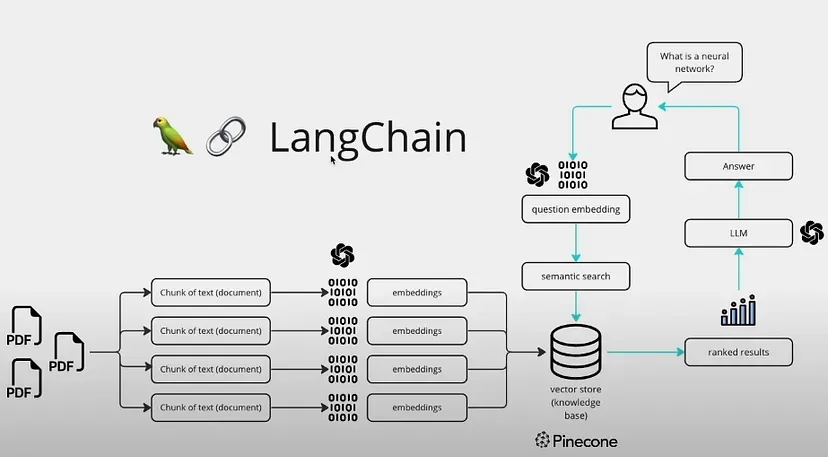
이처럼 Langchain은 LLM 사용자의 편의성을 극대화 시켜주는 동시에 LLM의 잠재력을 최대한으로 이끌어주는 멋진 툴이다. 과장을 조금 보태자면, Langchain 없는 챗GPT는 속빈 강정과 같다. 그렇다면 Langchain은 어떻게 작동하는 것일까? 이처럼 강력한 LLM 툴인 Langchain을 이해하기 위해 검색 기반 질의 응답(retrieval-based Q&A)의 예시를 들어 핵심적인 개념인 임베딩(embedding)과 벡터스토어(vector store)에 대해 알아보자.
벡터 스토어(vector store)란?
클라우드 컴퓨팅 기술과 gpu 성능의 개선으로 이전과는 다르게 이제 숫자로 표현되는 정형 데이터(structured data)가 아닌 이미지와 텍스트 등 비정형 데이터(unstructured data)의 활용이 대세로 떠올랐다.
이러한 인공지능 업계의 트렌드에 따라 기존의 관계형 데이터베이스 관리 시스템(RDBMS)에서 벗어나 방대한 양의 고차원 데이터를 벡터 형태로 최적화 하여 보관하고 쿼리하기 위한 데이터베이스의 필요성이 대두되었고, 이러한 벡터DB의 수요는 텍스트 데이터를 다루는 자연어처리(NLP) 분야에서도 자연스럽게 높아지게 되었다.

이러한 니즈를 충족시킬 수 있는 것이 바로 벡터 스토어다. 벡터 스토어는 임베딩을 통해 생성된 고차원의 벡터 데이터를 효율적으로 저장하고 조회할 수 있도록 설계된 데이터베이스이다. 벡터스토어는 전통적인 RDBMS와는 다르게, 벡터 간의 거리나 유사도를 기반으로 데이터를 조회한다. Faiss, Annoy, ElasticSearch 등의 벡터 데이터베이스는 벡터 간의 유사도 검색을 빠르게 수행할 수 있도록 최적화 되어 있어, 자연어처리나 추천 시스템 등에서 활발하게 사용된다.
임베딩(embedding)으로 벡터 스토어(vector store)에서 원하는 문장 가져오기
벡터 스토어에 비정형 데이터를 저장하기 위해서는 임베딩이라는 과정을 거쳐야 한다. 임베딩이란 텍스트나 이미지와 같은 비정형 데이터를 고차원의 벡터 형태로 변환하는 것을 의미한다.
예를 들어, 자연어 처리에서 단어나 문장을 고차원 벡터로 변환하는 작업은 단어 임베딩이라고 불린다. 임베딩의 주요 목적은 원래의 데이터의 의미나 특성을 최대한 보존하면서, 연산이 가능한 형태로 변환하는 것이다.
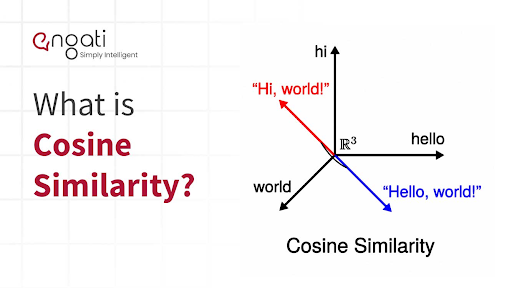
자연어처리 분야에서는 주로 Word2Vec, GloVe, FastText 등의 알고리즘을 사용하여 단어나 문장을 벡터로 변환하며, 이렇게 변환된 벡터는 비슷한 의미를 가진 단어나 문장이 벡터 공간에서 가까운 위치에 위치하게 된다. 워드임베딩(word embedding)이라고 불리는 이 과정을 거치고 나면 우리는 문장과 단어 사이의 유사도(similarity)를 구할 수 있게 된다.
코사인 유사도는 두 벡터 간의 유사도를 측정할 때 많이 사용되는 방법으로, 특히, 자연어 처리 분야에서 텍스트의 임베딩 벡터 간의 유사도를 측정할 때 자주 활용된다. 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다. 두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖기 때문이다.
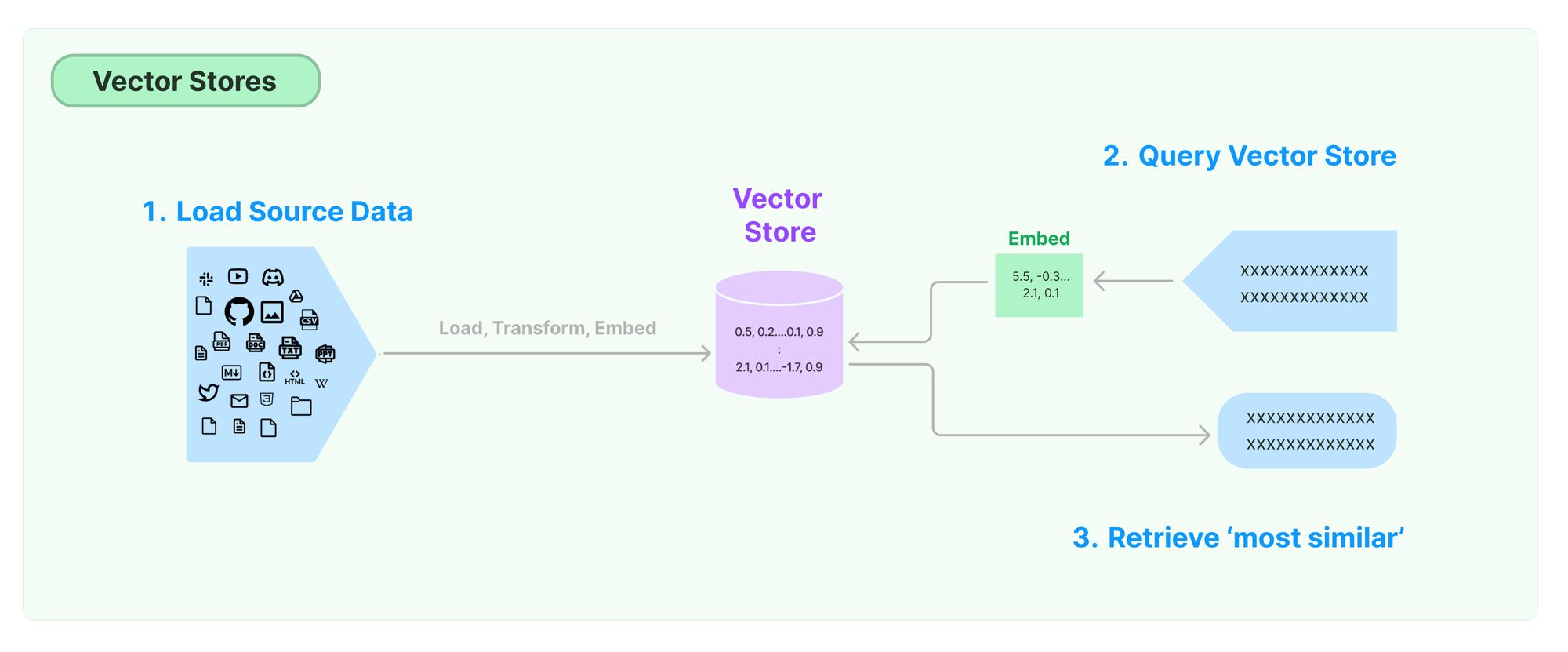
결국 벡터 스토어에서 원하는 검색 결과를 가져오기 위해서는 임베딩 벡터 간의 유사도를 측정해야 한다. 특히, 대규모의 데이터를 다룰 때, 직접 모든 데이터와 비교하는 것은 비효율적이기 때문에, 위에서 살펴본 코사인 유사도를 활용하여 사용자의 쿼리와 가장 유사한 데이터를 효율적으로 검색하게 된다.
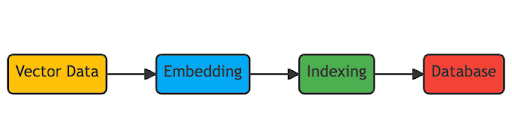
벡터 스토어는 이러한 코사인 유사도 검색을 최적화해서 수행할 수 있도록 설계되어 있다. 예를 들어, Faiss는 Facebook AI Research에서 개발된 벡터 검색 라이브러리로, 방대한 양의 데이터 중에서 특정 벡터와 가장 유사한 벡터들을 빠르게 찾아낼 수 있다. 또한, 벡터 스토어는 임베딩 벡터를 저장할 때 특정한 방식으로 인덱싱하여, 검색 시간을 크게 단축시킨다. 이러한 인덱싱 방법은 데이터의 크기나 특성, 그리고 어플리케이션의 요구사항에 따라 다양하게 선택될 수 있다.
결국, 벡터 스토어를 통해 원하는 검색 결과를 빠르게 가져오기 위해서는 적절한 임베딩 방법을 선택하고, 그 임베딩 벡터 간의 유사도를 효과적으로 측정할 수 있는 방법을 사용해야 한다. 그리고 이렇게 생성된 벡터 데이터를 효율적으로 저장하고 검색할 수 있는 벡터 스토어의 활용은 대규모 데이터를 다루는 현대의 다양한 어플리케이션에서 필수적이다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.