단어를 숫자로 바꿔 학습하는 방법 - 임베딩에 대한 이해


ChatGPT와 같은 AI 언어모델이 어떻게 사람의 말을 하는 지 궁금한 적이 있는가? 최근 핫한 ChatGPT가 사실 숫자로 입력된 정보를 요리조리 뜯어보고 사람의 말을 내뱉는 것이라면?
머신러닝 라이브러리를 사용해 보신 경험이 있는 분이라면 알겠지만 테이블로 정리된 데이터를 바로 머신러닝 라이브러리에 집어 넣을 수는 없다. 텍스트는 반드시 모두 숫자로 바꿔 입력해야 하는 데, 예를 들면 고객 데이터 테이블의 성별 컬럼에 있는 데이터가 남, 여라면 0 또는 1로 바꾸던지 아니면 1 또는 0으로 바꾸든지 해야한다.
어찌됐든 숫자로(by numbers) 입력해 컴퓨터로 하여금 데이터를 구분하고 분석할 수 있도록 해주는 것이다. 그렇다면 인공지능에게 사람의 말을 알아듣고 처리하도록 하는 자연어처리에서는 텍스트를 어떻게 숫자로 바꾸는 걸까?
이번 글에서는 자연어를 수치화하기 위한 방법 중에 하나인 임베딩에 대해 알아보고 대표적인 임베딩 알고리즘인 워드투백과 엘모, 그리고 딥러닝 기반 언어모델에서 임베딩 방법에 대해 알아 보고자 한다.
단어의 피처 벡터는 무엇일까?
앞서 고객 데이터 테이블이라면 고객의 특징을 구분할 수 있는 예를들어 성별, 나이, 가입채널 등의 정보가 고객의 특징을 나타낼 수 있는 피처(feature)가 될 수 있을 것이다. 그렇다면 A라는 고객은 [39, 여, 오프라인]과 같이 고객의 특징을 한 데 모은 피처 벡터로 나타낼 수 있다.
단어라면 어떻게 피처벡터를 구성할 수 있을까? 교착어냐 굴절어냐, 어순 등과 같은 특정 언어의 특징으로 피처벡터를 구성해서 언어모델에 입력한다면 단어 자체를 학습할 수 있는 적절한 입력값이 되지 못할 것이다.
단어의 피처벡터를 0과 1로 나타내는 것을 원핫 레프레젠테이션(One-hot represenation)이라 한다. 즉, 각 단어의 하나의 요소만 1이고 나머지 요소는 모두 0인 벡터로 표현된다.
예를 들어, 사과, 바나나, 오렌지와 같은 3개 단어를 원핫 레프레젠테이션으로 나타내려고 한다면 사과는 [1, 0, 0], 바나나는 [0, 1, 0], 오렌지는 [0,0,1]로 나타내는 것이다.
아주 쉽고 직관적이지만 단어 간의 관계를 전혀 유추할 수 없고 단어가 많아질수록 벡터의 차원도 커지기 때문에 계산 비용이 증가하는 것이 단점이다. 단어가 1만 개라면 1만 차원의 벡터가 되어 그 중 하나의 요소만 1이 되는 모양이 될 것이다.
임베딩 벡터는 이러한 문제를 해결하기 위해 도입된 개념이다. 임베딩 벡터는 각 단어를 고정된 크기의 실수 벡터로 표현한다. 예를 들어, "사과"를 [0.5, 0.8, -0.2]와 같은 다차원 실수 벡터로 표현하는 것이다. 이러한 임베딩 벡터는 단어 간 유사도를 계산할 수 있고 따라서 단어 간 관계도 고려할 수 있다. 물론 여기서도 단어의 수가 많아지면 벡터를 10차원, 100차원으로 늘려 여러 차원에 걸쳐 의미를 표현할 수도 있을 것이다.
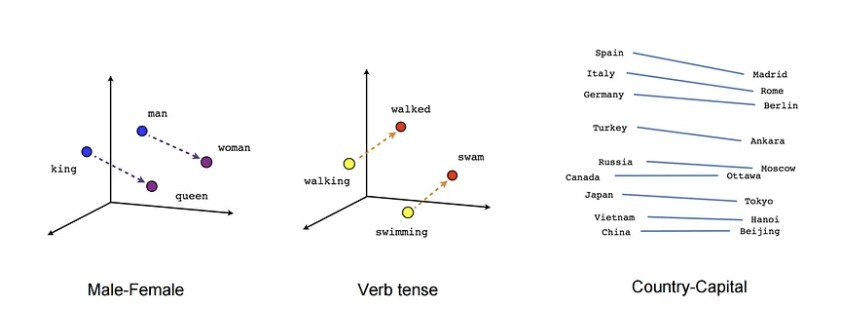
이러한 단어의 임베딩 벡터를 생성하기 위해서는 대량의 자연어 데이터가 필요한데 이 데이터를 신경망에 학습시켜 각 단어에 대한 임베딩 벡터를 생성하는 것이다.
워드투벡(Word2Vec)은 대표적인 임베딩 알고리즘 중 하나로 주변에 같은 단어가 나타나는 단어 일수록 비슷한 벡터 값을 가질 것이라고 전제한다. 현재 단어를 입력하면 주변 단어들을 예측하는 과정에서 단어의 적절한 임베딩 값을 얻을 수 있다. 단어의 의미를 벡터의 여러 차원에 분산해서 표현한다고 해서 분산 표현(Distributed presentation)이라고 한다.
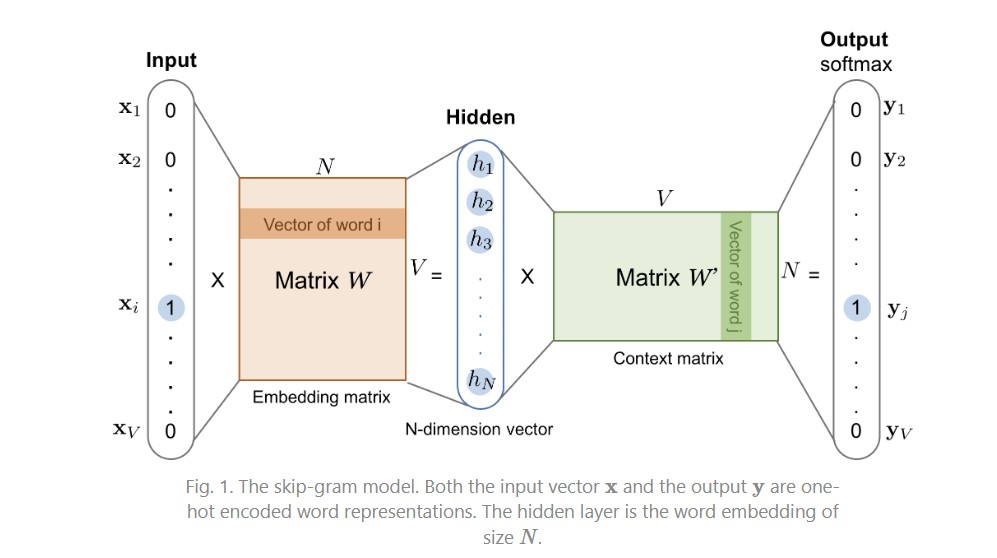
워드투백은 단어를 하나씩 학습해 가며 데이터셋 전체를 다 학습해야 임베딩 벡터가 픽스가 되기 때문에 같은 단어라면 같은 벡터를 가지게 된다. 우리가 흔히 ‘나 머리 잘랐어’라고 하면 이 때 머리 는 Head가 아니라 Hair라는 의미를 가지는 데 이러한 차이를 구별하지 못하는 것이다.
단어의 의미가 문맥에 따라 다른 의미를 가질 수 있다는 것을 고려해 단어의 피처 벡터를 표현하고 자 하는 것이 문맥적 표현(Contextual Representation) 방법이다. 그리고 이것을 가능하게 만드 는 것은 언어모델을 사용하는 것이다. .
엘모(Embeddings from Language Models)는 양방향 LSTM(Bidirectional Long Short-Term Memory)이라는 언어모델을 활용한 임베딩 방법으로 단어를 순방향과 역방향으로 모두 학습해 단어의 의미와 문맥을 반영한 임베딩 벡터를 생성한다. 같은 단어라도 문맥에 따라 다른 임베딩을 가질 수 있어 자연어처리의 성능을 올릴 수 있을 것으로 기대할 수 있다.

엘모는 대량의 데이터셋으로부터 학습한 언어모델의 지식을 활용하면 다른 자연어처리 문제에도 효과적일 것이라는 자연어처리에 있어 전이학습(Transfer learning)의 포문을 열었다 할 수 있다. 하지만 엘모로 임베딩 벡터를 생성했다 해도 모델의 파라미터는 Random initial weight로 학습하기 때문에 대용량 데이터셋의 도움을 직접적으로 받지 못한다는 한계가 있었다.
워드투벡이나 엘모가 임베딩 모델을 통해 사전에 임베딩 벡터를 학습해 다른 자연어처리에 활용 하는 방법이라면 트랜드포머 이후 언어모델들은 임베딩과 자연어처리를 동시에 학습하는 엔드 투 엔드(end-to-end) 방법을 사용한다.
딥러닝 기반 언어모델이 임베딩을 학습하는 방법
그렇다면 ChatGPT의 (직계)조상이라 할 수 있는 트랜스포머는 어떻게 임베딩을 넣어 학습할까?
우선 단어를 토큰화하고 각 토큰을 숫자로 처리할 수 있도록 정수에 매칭한다. 0번부터 9999번에 매칭되는 토큰들이 1만 개가 있다면 1만개의 크기를 가진 사전이 만들어 진 것이다. 이렇게 만든 사전을 기준으로 각 데이터 샘플을 정수로 변환해 트랜스포머의 임베딩 레이어에 전달하게 된다. 참고로 자연어(문장)의 길이는 샘플마다 다 달라 패딩도 추가해야 한다.
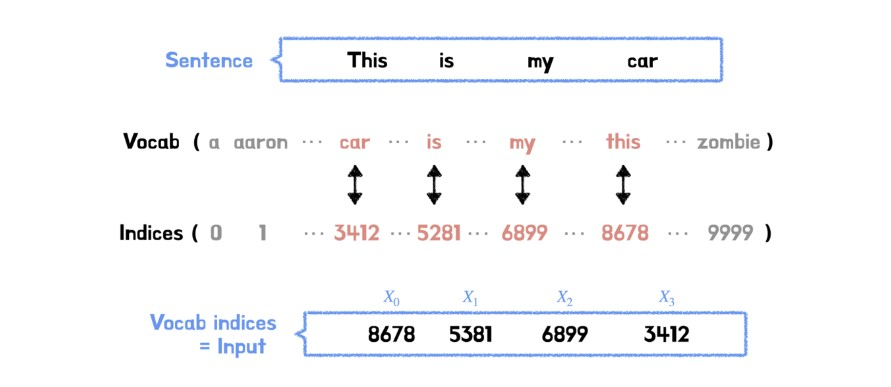
이렇게 전달된 샘플은 임베딩 층을 통과하며 각 정수에 해당하는 초기 가중치, 즉 토큰의 벡터값이 랜덤하게 배정될 것이다. 이 값들은 트랜스포머의 인코딩 층을 통과하고 다시 디코더 층을 통과해 최종 결과 (Output)가 나오게 된다. 한국어를 영어로 번역하는 문제라면 정답 단어가 나올 확률을 높이는 방향으로 학습을 진행하게 되는데 예측확률과 정답의 오차에 기여한 만큼 오차 기여도를 전달 받으며 모델의 가중치는 물론 임베딩 레이어의 가중치까지 모두 변화시키며 학습을 진행하게 된다. 이 과정에서 태스크에 맞는 최적화된 임베딩 표현과 모델의 가중치를 얻게 되는 것이다.
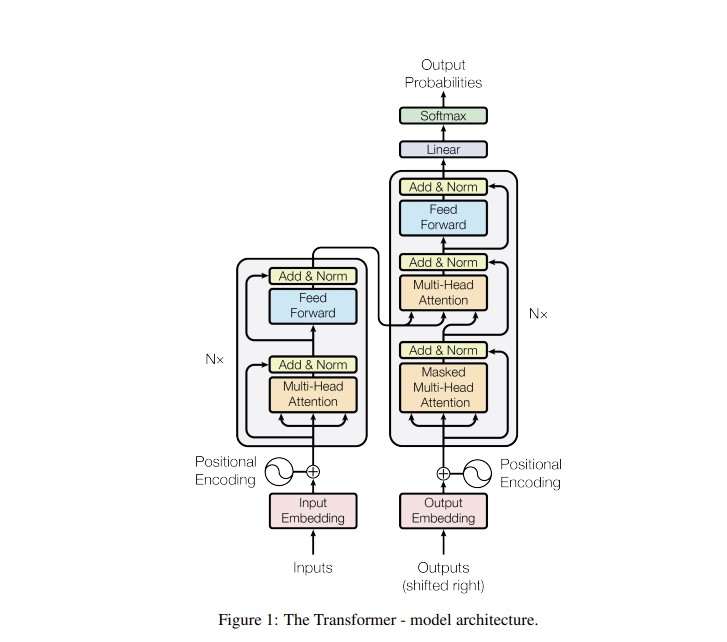
여기서 나아간 GPT-3와 같은 대형 언어모델의 경우 어마어마한 크기의 모델과 데이터셋의 학습을 통해 좋은 임베딩 표현을 가지고 있는 것은 물론 거의 모든 태스크에서 준수한 성능을 보인다고 할 수 있다.
| ||
마테크와 마케팅 데이터 분석에 대해 이야기 합니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.