하룻밤에 읽는 자연어처리(NLP)의 역사(1): 단어주머니(Bow)와 DTM 그리고 TF-IDF

2022년 말에 공개된 OpenAI의 챗GPT는 출시 후 단 두 달 만에 1억 명의 사용자를 보유하게 되었으며, 현재로서는 공개된 지 1년도 되지 않은 시점에서 이미 전 세계 인구의 약 3분의 1에 해당하는 사용자 수를 확보한 것으로 추정된다. 일반 대중들은 챗GPT가 가진 두 가지 능력, 즉 '추론을 통해 문장을 이해하는 능력'과 '인간과 유사한 매끄러운 문장 생성 능력'에 대해 열광하고 있다.
이로 인해 자연어처리(Natural Language Processing, NLP) 분야에 대한 관심이 대단히 높아지고 있다. NLP는 인간의 언어를 컴퓨터에게 이해시키고 생성하는 인공지능의 한 분야를 말한다. NLP는 우리 일상에서 흔히 볼 수 있는 검색 엔진의 자동 완성 기능, 챗봇, 음성인식 등 다양한 분야에서 폭넓게 활용된다. NLP는 또한 챗GPT를 비롯한 LLM(초거대언어모델)의 근간이 되는 기술이기도 하다.
LLM이 보편화된 현재, 사람들은 NLP에 대한 깊은 이해 없이도 손쉽게 인공지능 언어모델을 활용할 수 있게 되었다. 통계학, 딥러닝, 워드 임베딩(Word Embedding), 토큰화(Tokenization)와 같이 복잡하고 어려운 NLP의 기본 개념을 알지 못해도, 몇 줄의 명령어를 채팅창에 입력함으로써 LLM을 활용하여 원하는 결과물을 얻을 수 있다.
그렇다면 인공지능 언어모델은 어떻게 현재의 수준에 도달할 수 있게 되었을까? 이를 이해하기 위해서는 언어모델이 인간의 언어를 학습하는 방법에 대한 기초적인 개념들을 이해해야 한다. 비록 LLM에 접근하기가 쉬워지고 진입장벽이 낮아지는 추세이지만, 사용자들이 자연어처리(NLP)의 다양한 기술과 컴퓨터가 인간의 언어를 처리하는 과정을 이해하는 것은 여전히 중요하다. NLP를 공부하는 것은 나중에 LLM을 사용할 때 모델이 가진 한계와 가능성을 정확히 이해하는 데에 매우 큰 도움이 되기 때문이다.
자연어처리(NLP)의 새로운 표준, 초거대언어모델(LLM)
챗GPT는 언어의 복잡한 뉘앙스를 이해하고 자연스러운 문장을 생성하는 능력을 가지고 있다. 초기의 챗봇과는 달리 사용자의 의도를 파악하고 입력한 정보를 기억하여 다음 답변에 활용하며, 특정 토픽에 대해 의견을 제시하기도 하는데, 이는 챗GPT가 초거대언어모델(LLM)에 기반한 챗봇 서비스이기 때문이다.
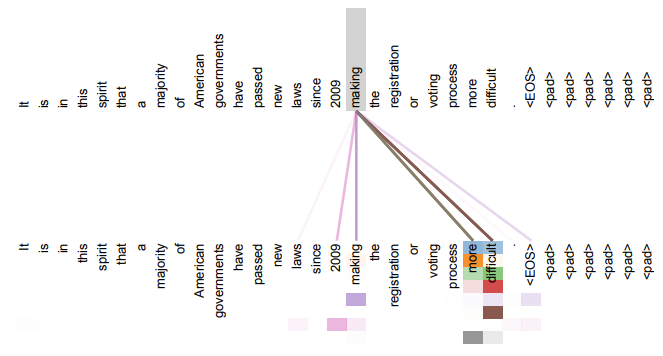
챗GPT는 초거대언어모델에 기반한 서비스로, 단순한 규칙 기반이나 통계 기반 언어모델과는 다르다.
이는 2016년 구글에서 발표한 Transformer 모델에 뿌리를 두고있는 GPT(Generative Pre-Trained) 모델을 기반으로 한 초거대언어모델의 서비스이다. 이 모델은 사전학습된 모델을 기반으로 하고, 전이학습을 통해 가중치 등을 미세조정하는 방식으로 동작한다.
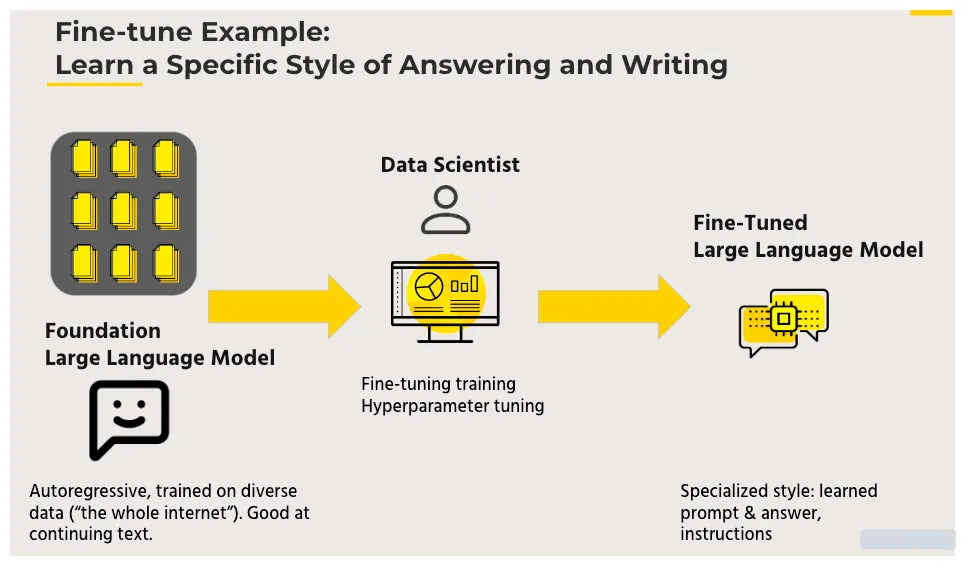
초거대언어모델은 다양한 종류의 텍스트 데이터를 사용하여 학습된다. 웹페이지, 책, 뉴스 기사, 블로그, 소셜 미디어 등 다양한 출처의 데이터를 활용하여 다양한 주제와 도메인에 대한 지식을 학습하고 이해한다. 이를 통해 보다 정밀한 추론과 자연스러운 언어구사가 가능하며, 이러한 전이학습(Transfer Learning) 과정은 인간이 언어를 배우는 과정과 유사하다.
딥러닝과 컴퓨팅 기술의 발전으로 인공지능은 방대한 양의 텍스트 데이터를 사전학습하는 초거대언어모델로 발전할 수 있었다. 처리 가능한 데이터 양의 증가로 인해 언어모델은 점점 더 거대해지고 있으며, 초거대언어모델은 이제 자연어처리 분야에서 새로운 표준으로 인정받고 있다.
초거대언어모델(LLM) 이전의 NLP(자연어처리)
LLM의 형태로 발전하기 전의 자연어처리(NLP)는 통계학과 컴퓨터과학의 발전에 의존하여 진화해왔다. 이전에는 상대적으로 적은 컴퓨팅 리소스와 데이터 처리 기술을 사용하여 자연어처리를 수행하였다.
그렇다면 LLM 이전의 자연어처리는 어떤 과정을 거쳐 발전해왔을까? 자연어처리에서 컴퓨터가 단어와 문장을 인식하는 방법은 다양하다. 이번 시간에는 직관적으로 이해할 수 있는 ‘카운트 기반 단어표현’기법에 대해 알아보자.
1. 카운트기반 단어표현(Count-based Word Representation)
카운트기반 단어표현은 문맥 안에서 특정 단어가 동시에 등장하는 빈도수를 세어 수치화하는 방법이다. 이를 위해 단어의 등장 횟수를 행렬로 표현하고, 이 행렬을 수치화하여 단어 벡터를 생성하는 방식을 사용한다. 카운트 기반 단어표현을 활용한 자연어처리 기법들에는 크게 DTM(Document-Term Matrix)과 TF-IDF(Term Frequency-Inverse Document Frequency)가 있다.
단어주머니(Bag of Words) : 0과1의 이진수로 인간의 언어를 인식하는 컴퓨터
이러한 카운트 기반의 단어표현을 이해하기 위해서는 우선 컴퓨터가 텍스트를 인식하는 방법 즉 컴퓨터가 인간의 언어를 바라보는 시점에 대해 살펴볼 필요가 있다. 컴퓨터다 텍스트 등 다양한 형태의 데이터를 0과 1로 이루어진 이진수로 인식한다. 이를 위해 자연어 처리에서는 텍스트 데이터를 0과 1로 이루어진 이진수로 변환하는 과정이 필요한데, 이를 '원 핫 인코딩(One-hot Encoding)'이다.
예를 들어 'hello world'라는 문장을 표현하기 위해서 컴퓨터는 문장을 구성하는 각각의 단어를 이진수로 변환해야 한다. 예를 들어 'hello'는 100으로, 'world'는 010으로 표현된다. 이렇게 인코딩된 단어들을 0과 1로 표현된 배열로 나열하면 하나의 문장이 완성되는 것이다.
이러한 문장들이 모여서 하나의 글이 완성되는데, 이러한 방식으로 만들어진 문장의 조합을 'Bag of Words'라고 한다. '단어 주머니'라는 의미를 가진 이 용어에서도 알 수 있듯이, Bag of Words 방식은 단어의 출현 빈도에만 관심을 가지며 단어의 순서는 고려하지 않는다.

BoW에서 한단계 더 발전한 DTM은 여러 문서에서 단어의 등장 빈도를 행렬로 표현하는 방법이다. 예를 들어, 여러 문서에서 "고양이"라는 단어가 각각 몇 번 등장하는지를 행렬로 표현하고, 이를 활용하여 문서 간의 유사도를 계산하거나 문서 내에서의 단어 중요도를 파악할 수 있다.
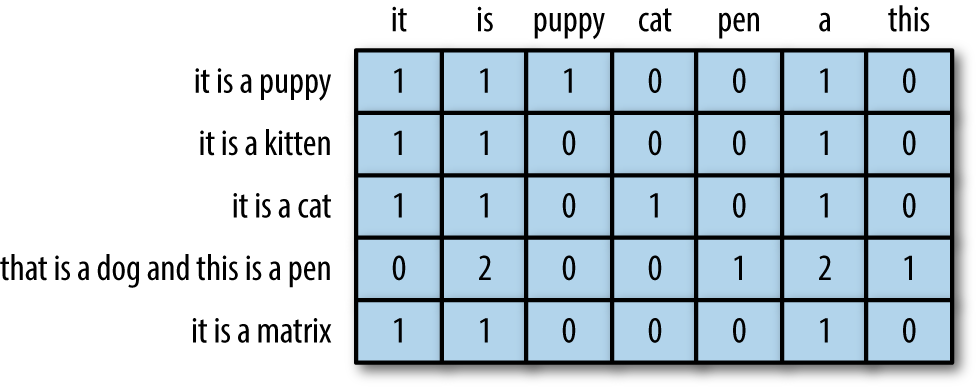
TF-IDF는 DTM보다 한단계 진보한 단어표현 방식이다. 단순히 단어의 등장횟수만이 아닌, 각 단어의 중요도를 고려하는 TF-IDF는 단어의 등장 빈도와 역문서 빈도를 고려하여 단어의 중요도를 평가하는 방법이다. 한 문서에서 자주 등장하지만 다른 문서에서는 등장하지 않는 단어일수록 중요하게 간주된다. 이를 통해 문서의 특징을 잘 나타내는 단어를 추출하거나 문서 간의 유사도를 계산할 수 있다.
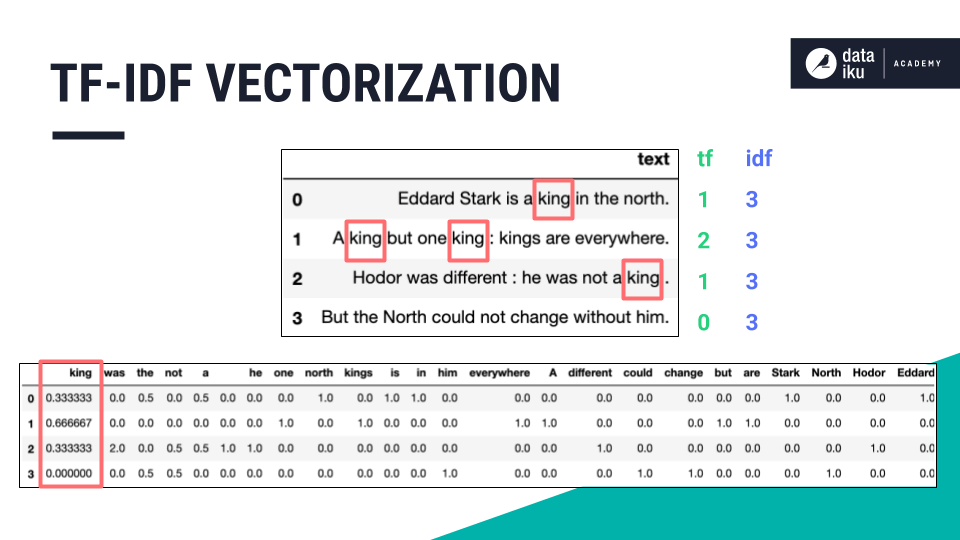
카운트기반 단어 표현은 자연어처리에서 중요한 개념으로 사용되며, DTM과 TF-IDF는 이를 구현하는 방법 중 일부다. 컴퓨터는 이러한 표현 방식을 적절히 활용하며 문서의 의미를 이해하고, 검색 결과를 개선하거나 문서 간의 유사도를 계산하는 등 다양한 자연어처리 작업을 수행한다. 컴퓨터가 인간의 언어를 어떻게 표현하는지 이해하는 것은 다가오는 생성형AI시대에 컴퓨터와 더욱 효율적이고 효과적인 소통을 위해 매우 중요하다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.