자연어처리(NLP)와 텍스트 마이닝(Text-mining) 언어에는 통찰력이라는 보물이 숨어있다

인공지능 도입을 고려하고있는 고객사의 현업분들과 미팅을 진행하다보면 자연어처리(NLP)와 텍스트 마이닝(Text-mining) 혹은 텍스트 분석(Text Analysis)이라는 단어를 구분하지 않고 사용하는 경우를 자주 볼 수 있다. 작년말 OpenAI사의 챗GPT 출시로 요즘은 LLM(초거대언어모델)과 생성형 AI까지 등장하며 자연어처리(NLP) 관련 용어의혼란을 더욱 가중시키고 있다.
자연어처리(NLP)라는 분야는 1950년대부터 이어져온 유구한 역사를 가진만큼 관련 기술의 범위와 깊이가 넓으며 그 경계가 애매하여 혼동하기 쉽다. 그러나 해당 분야를 정확히 이해하고 활용하기 위해서는 기술이 복잡하고 정교화 될수록 관련된 개념들을 정확하게 구분하고 자신만의 언어로 이해하는 것이 중요하다. 이번 시간에는 자연어처리와 비슷한듯 조금 다른 텍스트마이닝의 개념을 알아보고 그 매력에 푹 빠져보자.
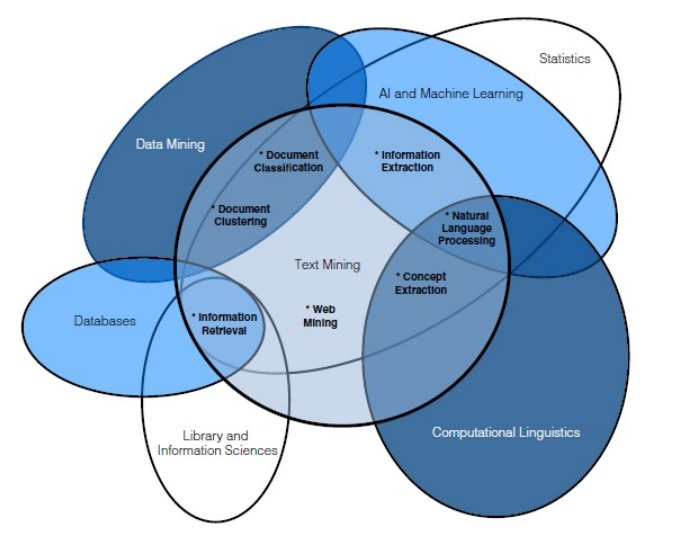
텍스트 마이닝과 자연어 처리
텍스트마이닝(Text Mining)은 얼핏보아 자연어처리(NLP)와 비슷한 개념인 것처럼 보이지만, 엄밀히 말해 NLP(자연어처리)와는 다른 분야다. 자연어처리(NLP)는 인간의 언어인 자연어(Natural Language)를 인공지능이 인식하고 표현할 수 있도록 하는것에 중점을 두는 분야인 반면, 텍스트마이닝(Text mining)은 자연어처리 과정을 통해 추출된 단어나 문장 속에서 유의미한 인사이트(Insight)를 찾아내는 작업을 칭한다. 텍스트마이닝에는 자연어처리뿐(NLP) 아니라 데이터(Data mining)과 데이터베이스(Database) 등 다양한 방면의 지식과 스킬이 필요하다.
쉽게말해 자연어처리(NLP)는 인공지능이 자연어를 ‘개떡같이 말해도 찰떡같이 알아듣도록’(Natural Language Understanding)하고, 그럴듯하게 생성(Natural Language Generation)해낼 수 있도록 통계학과 다양한 딥러닝 기술들을 적용하여 연구하는 분야다.
반면에 텍스트마이닝(Text-mining)은 자연어처리(NLP)의 결과물인 언어모델(Language Model) 혹은 토큰(Token)과 말뭉치(Corpus) 등을 활용하여 배달앱 리뷰나 쇼핑몰 검색 데이터와 같은 텍스트 형태로된 데이터에서 고객의 경향성이나 선호도 등 유의미한 정보를 얻어내기 위한 분석 기법들인 것이다.
2. 텍스트마이닝은 어떻게 적용될까?
텍스트 마이닝에는 분류(Classification), 워드클라우드(Word Cloud), 군집분석(Clustering) 등 다양한 기법들이 있다.
이러한 기법들을 실제 텍스트 데이터에 적용하기 위해서는 우선 말뭉치(Corpus)를 구성하고 각 단어속에서 어근을 뽑아내는 어간추출(Stemming)과 표제어추출(Lemmatization) 그리고 단어를 최소한의 의미단위로 나누어주는 토큰화(Tokenization)과 같은 텍스트 전처리(Preprocessing) 과정이 필요한데, 이러한 정제과정을 거친 텍스트 데이터를 텍스트마이닝에 활용하면 우리가 평소에 사용하는 정제되지 않은 문장들을 사용할 때보다 훨씬 더 분명한 인사이트를 얻어낼 수 있다.
3. 언어에는 통찰력이라는 보물이 숨어있다 : 상담사들의 ‘말’은 유능함의 척도가 될 수 있을까?
이러한 텍스트마이닝 기법들을 적절하게 활용하면 비교적 적은 노력만으로도 매우 흥미롭고 인사이트있는 결론을 얻어낼 수 있다. 예를들어 작년말 진행했던 모그룹 계열사 프로젝트에서는 상담사들의 실적을 파악하고자 하는 니즈가 있었다. 실적에 따른 인센티브 제공과 추가 트레이닝(Training) 제공으로 매출을 최적화 하기 위해서다.
목표달성을 위해 우선 계약실적을 기준으로 상담사군을 그룹화(Grouping) 한 뒤, 각 그룹의 상담사들이 주로 사용하는 문장의 특성을 보여주는 말뭉치(Corpus)를 구성하였고, 말뭉치를 최소한의 의미 단위인 토큰으로 변환하는(Tokenization) 작업을 진행하였다. 전처리 과정을 통해 추출된 각 그룹의 토큰(Token)들을 분석을 위한 Python 라이브러리를 활용하여 워드클라우드(Word Cloud)를 제작하였다.
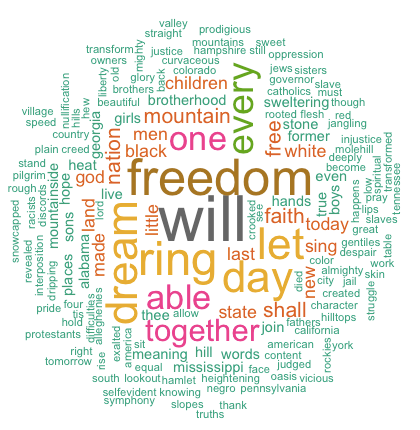
워드클라우드란 통해 말뭉치에 등장하는 단어의 횟수에 따라 서로 다른 크기로 단어를 보여주는 시각화(Visualization)를 위한 도구 일종인데, 이를 통해 우리는 실적이 좋은 ‘우수상담사’와 실적이 비교적 나쁜 상담사 사이에 사용하는 단어의 뚜렷한 차이가 있음을 알 수 있었다.
예를들어 실적이 우수한 상담사의 경우 ‘준비’,’바로’,’다음’,안내’ 등 즉시 계약을 유도해내기 위한 단어 표현을 많이 사용하는 경향이 있는 반면, 실적이 저조한 상담사의 경우 ‘만약’,’상황’,’언제’ 등 소극적이거나 다음을 기약하고자 하는 단어 표현이 많음을 알 수 있었다. 이렇게 비교적 간단한 작업만으로도 우리는 커다란 인사이트를 얻을 수 있었다.
사람들은 숫자로 이루어진 테이블 데이터와 같은 정형화된 데이터(Structured Data)에서 객관적인 정보(Information)과 인사이트를 유추해내는 것에 익숙하다. 반면에 텍스트 데이터와같은 비정형 데이터(Unstructured Data)에서도 유의미하고 비즈니스에 도움이 되는 인사이트를 얻어낼 수 있다는 사실은 잘 눈치채지 못하는 것 같다. ‘언어’로된 데이터는 생각보다 많은 정보와 통찰력을 담고 있다. 따라서 텍스트마이닝을 잘 사용한다면 놀라운 지혜를 얻게될 수 있을 것이다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.