텍스트 검출 및 인식 - 아날로그의 디지털화를 위해

텍스트 검출 및 인식 (Text Detection/Recognition)
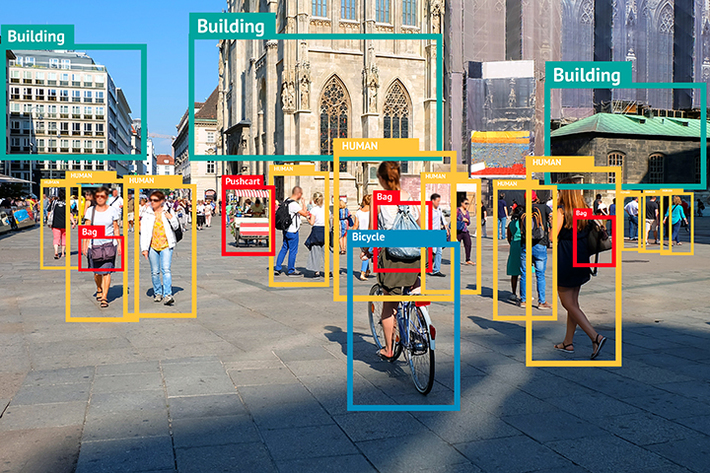
텍스트 검출(Text Detection) 및 텍스트 인식(Text Recognition)은 디지털 이미지나 비디오에서 텍스트를 검출하고 인식하는 기술로 흔히 OCR(Optical Character Recognition)이라고도 불립니다. 이러한 텍스트 검출 및 인식 기술은 객체 검출(Object Detection)의 한 분야이며 영상에서 텍스트만을 추출하고 인식합니다.
*편의상 텍스트 검출과 인식 작업을 합쳐 ‘OCR’이라 부르겠습니다.

텍스트 검출은 영상에서 텍스트의 영역을 감지하고 텍스트의 경계 상자(Bounding Box)를 그리는 과정입니다. 텍스트 검출 역시 객체 검출과 유사하게 일반적으로 딥러닝을 사용하지만 회전되지 않은 박스 형태로 객체 영역을 추출하는 객체 검출과는 달리, 텍스트 검출은 회전된 박스나 폴리곤 형태로 텍스트 영역을 최대한 타이트하게 검출하는 것이 중요합니다. 박스 안에 다른 물체나 배경 없이 온전히 읽고 싶은 텍스트만 있어야 인식 성능이 높아지기 때문입니다.

텍스트 인식은 검출된 텍스트 영역에서 실제 텍스트 정보를 추출하는 과정입니다. 정형화된 텍스트의 경우 간단한 방법으로도 텍스트를 인식할 수 있지만 폰트와 색상이 다양하고 조명, 노이즈 등이 있는 실제 환경의 텍스트를 인식하는 것은 쉽지 않은 문제입니다. 관심 영역을 박스 형태로 추출하고 추출된 관심 영역 이미지에서 텍스트를 인식한다는 것에서 이미지 분류와 유사하지만 다른 점도 있습니다. 이미지 분류의 경우 이미지를 하나의 카테고리로 분류합니다.
강아지, 고양이, 자동차 등으로 말이죠. 하지만 텍스트 인식의 경우 여러 글자가 모여 하나의 단어를 이루고, 일반적으로 관심 영역 안에 하나 이상의 단어가 포함됩니다. 때문에 텍스트 인식은 텍스트 속의 여러 문자를 하나씩 인식하고 인식한 결과의 합을 보여줘야 합니다. 이때 단순히 문자를 하나씩 인식하는 것이 아니라 문맥 정보를 활용하여 정확도를 향상시키는 경우가 많습니다.
OCR 모델 개발의 어려운 점 - 데이터
텍스트 검출과 인식은 이미 많은 연구가 진행되어 있지만 완성도 높은 OCR 모델을 만드는 것은 쉽지 않습니다. 학습 데이터를 만드는 것이 쉽지 않기 때문입니다. 일반적인 객체 검출에 비해 텍스트 검출은 텍스트 영역을 감싸는 회전된 박스나 폴리곤 형태의 어노테이션이 필요합니다. 또한 텍스트 인식은 관심 영역의 텍스트 정보를 기입해야 하기 때문에 미리 지정된 여러 항목 중 하나의 항목을 지정하는 방식에 비해 많은 시간이 소요됩니다.
국가별로 언어가 다르다는 것 또한 어려운 점 중 하나입니다. 객체 검출의 경우 지구 반대편에서 만든 모델을 가져오더라도 사용하는데 무리가 없지만, 언어는 굉장히 다양하기 때문에 OCR 모델을 개발하기 위해서는 사용목적에 맞는 언어가 포함된 학습 데이터가 필요합니다. 한국어는 특히 우리나라만 사용하는 언어이기 때문에 공개된 텍스트 검출 및 인식 데이터셋 자체가 적고 연구 자료 또한 영어에 비해 부족합니다.
이러한 이유 때문에 OCR 분야에서는 딥러닝 모델 연구뿐만 아니라 양질의 학습 데이터셋을 구축하는 것이 굉장히 중요합니다.
지금부터는 OCR 기술이 여러 산업에서 어떻게 활용되고 있는지 알아보도록 하겠습니다.
OCR 기술은 주로 각종 아날로그 문서를 디지털화하는데 사용됩니다. 은행, 관공서, 의료 기관을 포함한 다양한 기업에서 각종 문서를 디지털화하기 위해 많은 인력과 시간을 쏟고 있었기 때문입니다. 또한 IT플랫폼 기업에서는 여러 이미지 속에서 텍스트를 추출하고 데이터화시켜 고객의 니즈를 파악하는 용도로 활용할 수 있고, 자율 주행 분야에서도 도로 위 다양한 텍스트를 읽어내는데 활용할 수 있습니다. 더욱 간단한 용도로는 주차장에 들어갈 때 차량 번호를 인식하거나 금융 앱에서 신분증이나 신용카드를 인식하는 데 OCR 기술이 활용되고 있습니다.
문서 이해 (Document Understanding)
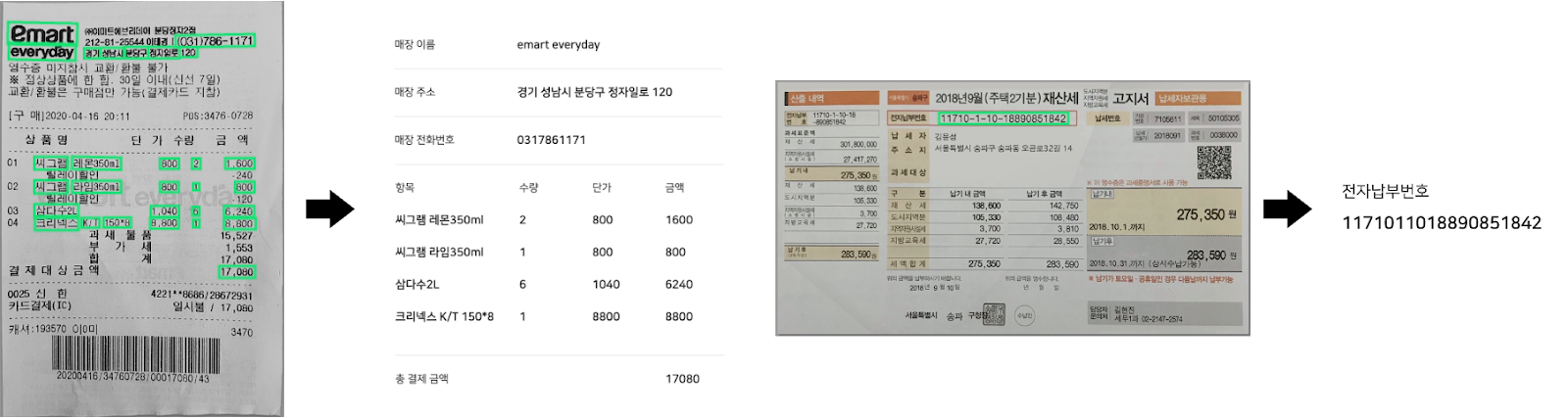
앞서 설명한 문서의 디지털화를 위해서는 단순히 이미지에서 텍스트를 검출, 인식하는 것만으로는 부족합니다. 필요한 정보를 key-value로 카테고리화(e.g. 이름 - 홍길동, 주소 - 서울시,...) 해야 활용할 수 있는 데이터가 되기 때문입니다. 예를 들어 영수증을 인식할 때는 매장 이름, 메뉴 이름, 가격, 최종 가격 등을 추출해야 하고 명함에서는 이름, 주소, 전화번호, 이메일 등을 추출해야 합니다. 이러한 작업은 Document Understanding(DU)이라고 불리며, 학습 완료된 OCR 모델에 추가로 DU 모델을 학습할 수도 있고, 처음부터 OCR-DU를 한 번에 end-to-end로 수행하는 모델을 만들 수도 있습니다.
자율주행, 정밀 지도 제작


OCR 기술은 야외 간판이나 도로 표지판 등을 인식하여 자율 주행이나 정밀 지도 제작 등에도 활용할 수 있습니다. 야외 실제 환경은 텍스트의 크기와 폰트가 다양하고 가로, 세로 텍스트가 혼재하기 때문에 OCR에서 가장 어려운 조건 중 하나입니다.
또한 OCR 기술은 영상 속 장면을 이해하는 데 필수적인 기술이기 때문에 설명드린 내용 이외에도 제조, AR/VR, 교육, 유통 등 다양한 곳에 활용될 수 있습니다.
 | ||
이야기와 글쓰기를 좋아하는 컴퓨터비전 엔지니어 콤파스입니다. |
* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.