생성형 AI의 탄소발자국 줄이기


각 분야에서 생성형 AI의 도입이 확대되면서 이로 인한 막대한 전기 사용량과 탄소 배출이 심각한 사회적 문제로 대두되고 있다. 한 연구소에 따르면 GPT-3가 훈련과정에서 사용한 전력은 1287MWh, 이산화탄소 배출량은 552톤에 이르며, 이는 가솔린 자동차 123대가 1년 주행할 때의 탄소 배출량과 맞먹는다고 한다.
뿐만 아니라 생성형 AI에는 엄청난 양의 물도 소비된다. 컴퓨터 가동 시 발생하는 열을 식히기 위한 냉각수가 필요하기 때문이다. 미국 리버사이드 콜로라도대학교와 앨링턴택사스대 연구진이 발표한 논문에 의하면, GPT-3 훈련을 위해서만 미국 데이터센터 기준으로 물 70만 L가 소비되었을 것이며, 에너지 효율이 낮은 아시아 데이터 센터에서 GPT-3를 훈련시켰다면 3배 더 많은 물이 필요했을 것이라고 추정했다.

이처럼 천문학적 규모의 데이터 센터를 바탕으로 운영되는 생성형 AI가 환경파괴의 주범이자 애물단지로 전락하는 것을 막기 위해서는 지금이라도 지속 가능한 에너지원을 발굴하고 생성형 AI 운용에 적용하기 위한 대책 마련이 시급하다. 이번 시간에는 지속 가능한 생성형 AI 실현을 위한 방안들에 대해 알아보자.
1) 최첨단 친환경 에너지 기술 적용
우선 최첨단 친환경 에너지 기술을 적용하는 방안을 생각해 볼 수 있다. 위에서 살펴본 것과 같이 생성형 AI 운용에 필요한 막대한 에너지양 생산은 환경에 큰 부담을 주며, 현재의 에너지 그리드 시스템 만으로는 장기적으로 지속 가능하지 않기 때문이다. 태양광이나 풍력과 같은 천연 에너지원을 생성형 AI 데이터 센터 운영에 활용하고 있지만, 기존의 신재생에너지는 낮은 전력 생산 효율성으로 인한 한계에 봉착했다.
각국의 정부와 생성형 AI 기업들의 CEO 역시 대책 마련에 고심하고 있다. 이를 반영하듯 얼마 전 OpenAI의 샘 올트먼과 벤처캐피탈 안데르센 호로위츠가 에너지 스타트업 엑소와트(EXOWATT)에 약 2000만 달러(약 270억 원)을 투자했다고 한다.

샘 알트먼이 투자한 엑소와트는 널찍한 패널을 사용하는 일반적인 태양광 업체와 달리 렌즈를 사용하며, 이 렌즈를 통해 태양광을 한데 모은 뒤 열로 변환하기 때문에 발전 효율이 높은 것으로 알려져 있다. 열로 변환된 전력은 선적용 컨테이너 정도 크기의 모듈에서 최대 24시간 동안 저장되는데, 태양광 에너지를 열 형태로 바꿔 저장하면 비용 절감 효과가 크다. 이처럼 생성형 AI 기술과 친환경 에너지 기술은 함께 발전해 나아가야 한다.
2) 최적화를 통한 컴퓨팅 리소스 절감
다음으로 컴퓨팅 리소스를 줄이기 위해 생성형 AI 모델 자체를 축소하는 방안들을 고려해 볼 수 있다. 매개변수(Parameter)와 사전학습(Pre-training) 데이터의 사이즈는 생성형 AI의 성능을 가늠하는 척도로 통용되어왔다. 심층신경망(DNN, Deep Neural Network)를 기반으로 하는 현재의 생성형 AI는 모델의 가중치(Weight)와 편향(Bias)를 나타내는 매개변수가 많고, 데이터 생성의 기반이 되는 훈련 데이터의 수가 많을수록 결과물의 퀄리티가 좋기 때문이다.
문제는 매개변수와 훈련 데이터의 사이즈가 커질수록 이를 구동하기 위한 GPU 등 컴퓨터 리소스도 비례하여 커지며, 이는 곧 에너지 소비량 증가로 이어진다는 점이다. 예를 들어 GPT-3의 매개변수 수는 1750억 개에 달하며, GPT-4의 매개변수는 이의 약 10배에 해당하는 1조7천억 개 이상인 것으로 알려져 있는데, 단순 계산으로 GPT-4의 운용을 위해서는 GPT-3에 비해 거의 열 배에 달하는 계산 리소스가 필요하다는 결론이 나온다.
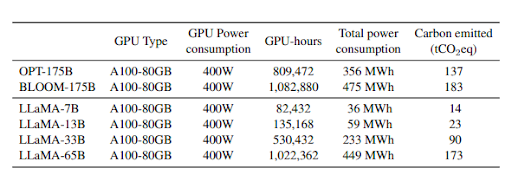
이러한 문제를 해결하기 위해서는 매개변수와 훈련 데이터 수는 적으면서 성능을 좋은 가성비 좋은 모델들의 개발을 고려해 볼 수 있다. 예를 들어 Meta AI의 오픈소스 모델의 라마는 LLaMA(Large Language Model Meta AI)는 커다란 사이즈의 모델에서 오는 문제들을 해결하기 위해 비교적 작은 사이즈의 모델(7B, 13B, 33B, 65B)들을 제시한다. 뿐만 아니라 Meta AI의 논문에서는 사이즈가 작은 모델을 더 많은 데이터로 학습시키는 것이 사이즈가 큰 모델을 더 많은 파라미터로 학습시키는 것보다 성능이 좋을 수 있다는 사실을 증명해 냈다.
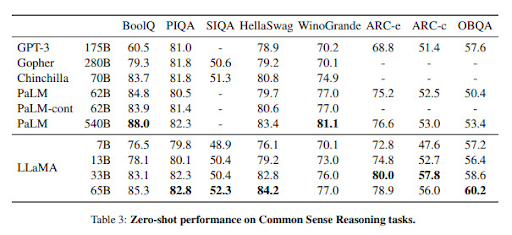
연구 결과에 따르면 놀랍게도 GPT-3(175B)에 비해 매개변수가 절반도 되지 않는 LLaMA 모델이 거의 모든 성능 지표에서 GPT-3을 앞서는 것을 볼 수 있다. 뿐만 아니라 LLaMA 시리즈 중에서도 비교적 매개변수가 적은 모델을 사용하면 CO2 배출을 많이 줄일 수 있음을 알 수 있다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.