AI 도입, 2주면 충분합니다 — 슈퍼브에이아이 노코드 플랫폼이 바꾸는 산업 현장
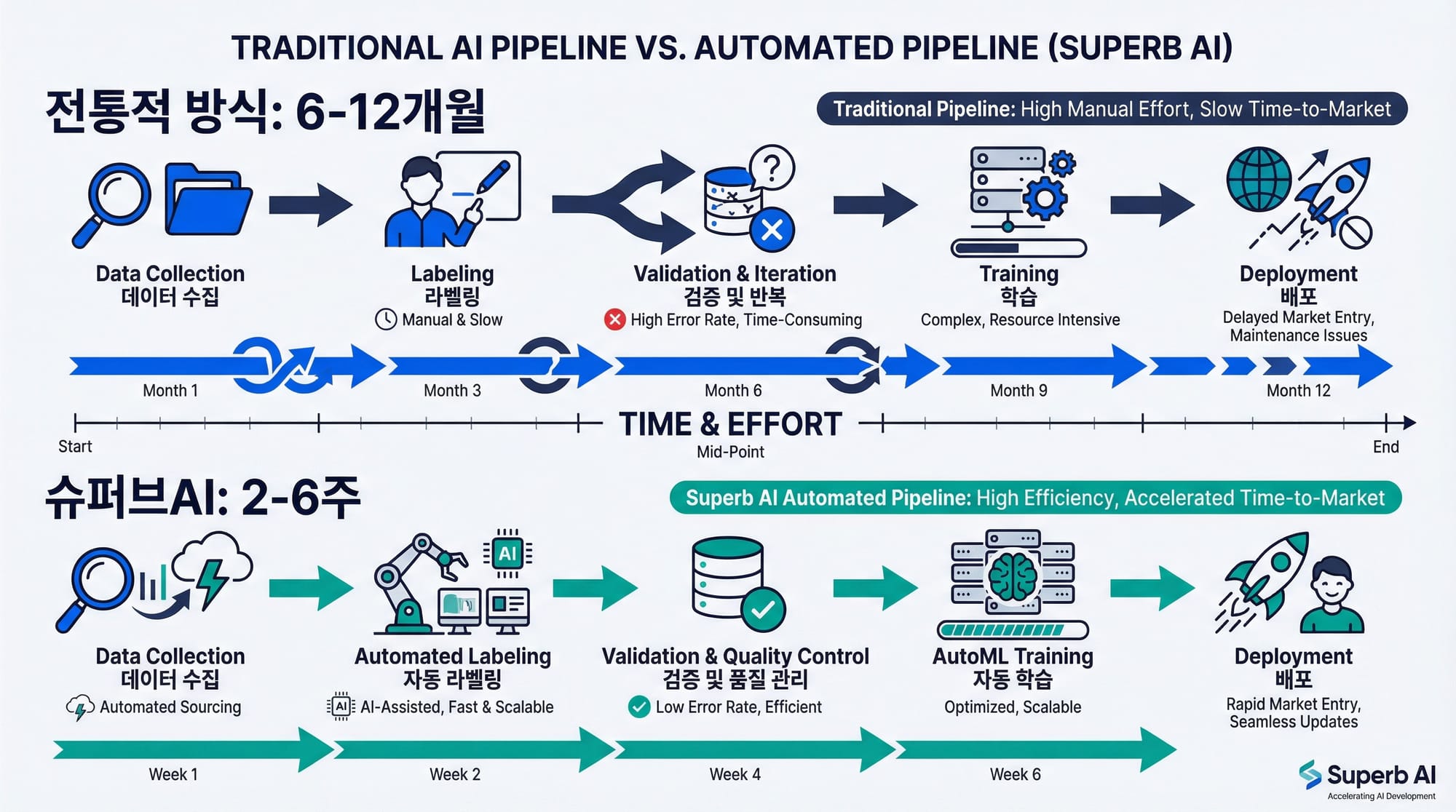
AI 프로젝트의 80%는 데이터 구축에서 멈춥니다. 슈퍼브에이아이의 노코드 AI 플랫폼은 Auto-Label, Auto-Curate, Auto-ML 기술로 기존 6~12개월 걸리던 비전 AI 개발·배포 기간을 2~6주로 단축하고, 라벨링 비용을 75% 절감합니다.


Key Takeaways
- 데이터 구축 병목 해소: 전통적 AI 프로젝트는 전체 일정의 약 80%를 데이터 구축에 소비하지만, 슈퍼브에이아이의 Auto-Label 기술은 라벨링 비용을 최대 75% 절감하고 작업 속도를 평균 9.7배 향상시킵니다.
- 코딩 없는 모델 학습: Auto-ML을 통해 AI 비전문가도 클릭 몇 번으로 고성능 모델을 학습할 수 있으며, 실제 고객사(Sharp, Toyota)에서 검증된 성과를 기록했습니다.
- 개발-배포 기간 10배 단축: 기존 6~12개월 걸리던 AI 파이프라인을 2~6주로 압축하여, AI가 일회성 프로젝트가 아닌 지속적 자산이 되도록 설계되었습니다.
AI 프로젝트가 PoC에서 멈추는 이유
제조·물류·에너지 현장에서 비전 AI(Vision AI)의 가능성을 확인한 기업은 많습니다. 불량 검출, 안전 모니터링, 재고 관리 등 수십 가지 유즈케이스가 증명되어 왔습니다. 그런데도 대부분의 기업이 PoC(Proof of Concept, 개념 검증) 단계에서 멈춥니다.

그 이유는 단순합니다. 학계에서 AI를 연구하는 것과 산업 현장에 AI를 적용하는 것은 완전히 다른 문제이기 때문입니다. 학계는 ImageNet, COCO 같은 공통 벤치마크 데이터셋(Benchmark Dataset)으로 모델 성능을 비교하지만, 실제 기업 환경에서 이 벤치마크 모델은 거의 쓸모가 없습니다. 각 기업의 제품, 공정, 환경이 모두 다르기 때문에 맞춤형 데이터셋을 처음부터 구축해야 합니다.
문제는 이 데이터 구축 과정이 전체 AI 프로젝트 작업량의 약 80%를 차지한다는 점입니다. 데이터를 수집하고, 한 땀 한 땀 라벨링하고, 품질을 검수하고, 모델을 학습시키고, 다시 데이터를 보완하는 전통적인 수동 방식으로는 모델 배포까지 6~12개월이 걸립니다. 주어진 프로젝트 기간 내에 성과를 내지 못하면서 대부분의 기업 AI 프로젝트가 중단되는 것이 현실입니다.
슈퍼브에이아이는 바로 이 병목을 정면으로 해결하기 위해 만들어진 노코드 AI 플랫폼(No-Code AI Platform)입니다.
데이터 구축과 모델 학습 병목 동시 자동화 전략
기업이 AI를 도입할 때 부딪히는 두 가지 벽
산업 현장에 AI를 적용하려면 크게 두 단계를 거쳐야 합니다.
① 데이터 구축 단계
맞춤형 데이터를 한 장 한 장 라벨링하는 것은 비용과 시간이 막대하게 드는 작업입니다. 예를 들어 반도체 웨이퍼 불량 검출 모델을 만들려면, 수만 장의 웨이퍼 이미지에 불량 유형별로 정확한 라벨을 붙여야 합니다. 이 과정만으로 수개월의 시간과 수천만 원의 비용이 소요됩니다.

② 모델 학습 단계
데이터가 준비되어도 끝이 아닙니다. 하이퍼파라미터 튜닝(Hyperparameter Tuning, 모델 성능을 최적화하기 위해 학습률·배치 크기 등 설정값을 조정하는 과정), 모델 아키텍처 선택, 학습 스케줄링 등 AI 전문 지식이 필요한 반복 실험이 이어집니다. AI 전문 인력이 없는 기업은 소수의 외부 AI 전문 기업에 의존할 수밖에 없고, 그 결과 비용이 높아지고 기술 주체성을 잃게 됩니다.
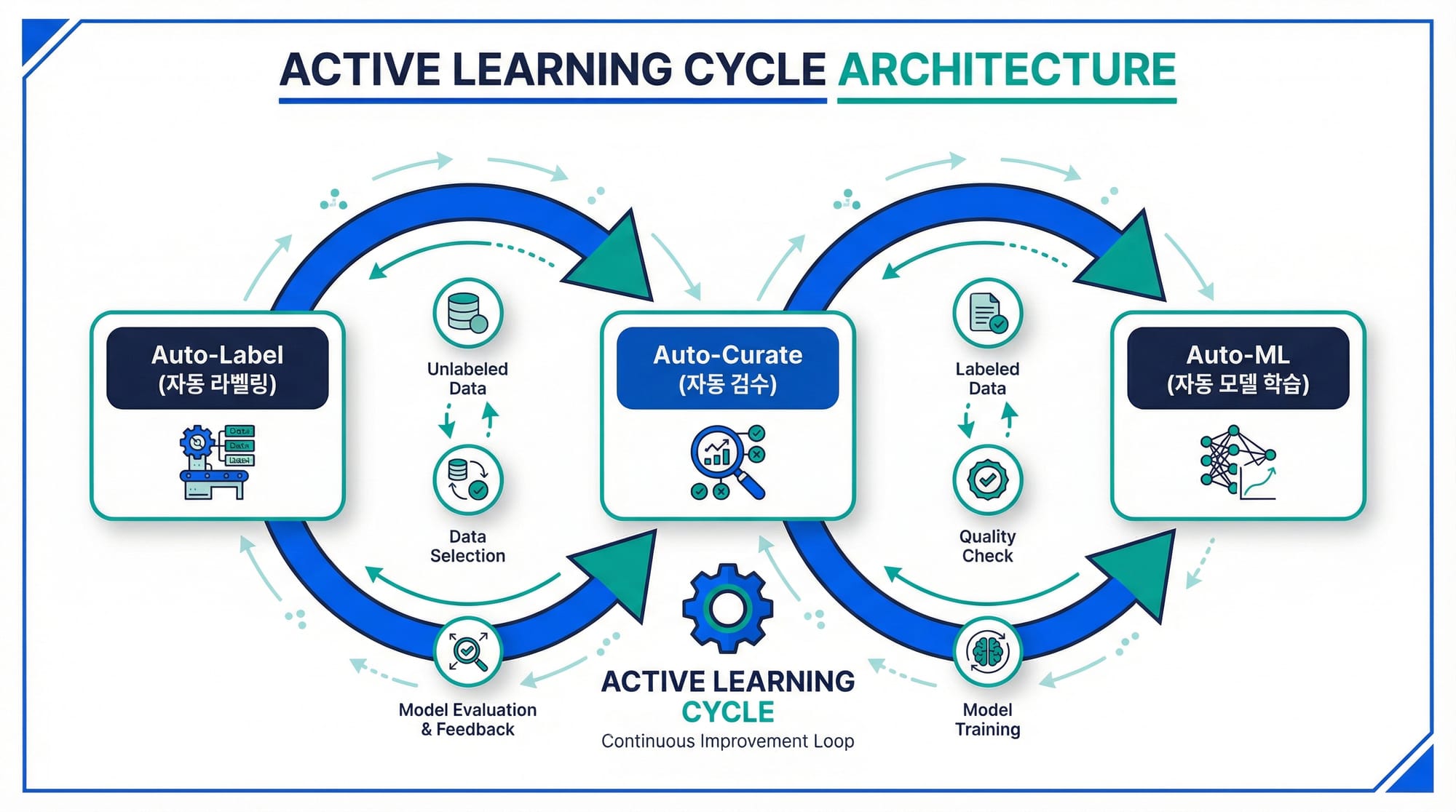
슈퍼브에이아이의 해법: 세 가지 핵심 기술의 선순환
슈퍼브에이아이는 이 두 가지 병목을 세 가지 핵심 기술로 동시에 해결합니다.
기술 | 해결하는 문제 | 핵심 효과 |
Auto-Label (자동 라벨링) | 데이터 구축 비용·시간 | 학습된 AI가 새 데이터에 라벨을 자동 예측, 사람은 검토·수정만 수행 → 라벨링 비용 75% 절감 |
Auto-Curate (자동 검수) | 데이터 품질 관리 | 불확실성 추정(Uncertainty Estimation)과 오라벨 탐지(Mislabel Detection)로 문제 데이터를 자동 식별 → 전수검사 불필요 |
Auto-ML (자동 모델 학습) | 모델 학습의 전문성 장벽 | 하이퍼파라미터 탐색·아키텍처 선택·학습 스케줄링을 자동화 → 클릭만으로 고성능 모델 학습 |
이 세 기술이 결합되면 Active Learning(능동 학습) 사이클이 형성됩니다. Auto-Label로 데이터를 빠르게 구축하고 → 자동 검수로 품질을 확보하고 → Auto-ML로 모델을 학습하면 → 학습된 모델이 다시 Auto-Label에 투입되어 더 정확한 예측을 수행합니다. 이 사이클을 반복할수록 데이터 품질과 모델 성능이 동시에 개선되는 선순환이 만들어집니다.
실행 가이드: 비전 AI 도입을 검토 중이라면, 가장 먼저 현재 보유한 이미지 데이터의 양과 라벨링 상태를 점검하세요. 슈퍼브에이아이 플랫폼은 소량의 초기 라벨링 데이터(수십~수백 장)만으로도 Auto-Label을 시작할 수 있으므로, 대규모 데이터 수집 전에 빠르게 프로토타입을 만들어 볼 수 있습니다.
Auto-ML과 Auto-Label 핵심 기술의 실질적 차이
Auto-ML: AI 전문가 없이도 최적의 모델을 학습하는 방법
전통적으로 AI 모델 학습은 ML 엔지니어의 전유물이었습니다. 학습률을 얼마로 설정할지, 어떤 백본(Backbone) 네트워크를 쓸지, 데이터 증강(Data Augmentation)은 어떻게 적용할지 — 이 모든 판단에 깊은 전문 지식이 필요했습니다.
슈퍼브에이아이의 Auto-ML은 이 과정을 자동화하여, 도메인 전문가(비전문가)가 학습 버튼 클릭만으로 최적화된 모델을 얻을 수 있게 합니다. 그 뒤에는 다음과 같은 기술이 작동합니다.
- Few-shot Learning(소량 학습): 5~50장의 소량 데이터만으로 프로토타입을 즉시 생성합니다. 고객이 현장 데이터 수십 장만 업로드하면 수분 내에 동작하는 모델을 확인할 수 있어, AI 도입의 초기 진입장벽을 극적으로 낮춥니다.
- Self-Supervised Pre-training(자기지도 사전학습): BEiT, BOT 등의 알고리즘으로 모델의 초기 가중치를 사전 학습합니다. 의료 영상, 현미경 이미지, 위성 사진 등 대규모 공개 데이터셋이 존재하지 않는 니치 도메인에서도 적은 데이터로 높은 성능을 달성할 수 있습니다.
- Bayesian Optimization(베이지안 최적화): 하이퍼파라미터 탐색을 자동화합니다. 전통적인 Grid Search나 Random Search 대비 3~5배 높은 효율로 최적 설정을 찾아냅니다.
- Residual Feature Fusion with Adapter: 슈퍼브에이아이가 보유한 한국·미국 등록 특허 기술(KR 10-2738343 / US 11,954,898)로, 사전학습된 백본을 동결한 상태에서 중간 레이어의 피처를 어댑터에 통과시켜 결합합니다. 기존 LoRA·어댑터 방식이 레이어별 독립 적용으로 레이어 간 정보 흐름이 단절되는 반면, 이 방식은 크로스 레이어 잔차 연결(Cross-layer Residual Connection)로 레이어 간 피처 상호작용을 명시적으로 학습합니다. 적은 파라미터 추가만으로 풀 파인 튜닝에 근접한 성능을 달성합니다.
지원 태스크: Classification(분류), Object Detection(객체 탐지), Segmentation(영역 분할)
실제 고객 검증 사례
고객사 | 학습 기간 | 학습 횟수 | 성과 |
S사 | 8개월 | 136회 자동 학습 | 디스플레이 불량 검출 mAP 40.7% → 54.9% (+35% 성능 향상) |
T사 | 10개월 | 21회 학습 | 공장 안전 AI mAP 79.6% → 96.6%, 기존 대비 약 10배 빠른 속도로 모델 개선 |
두 사례 모두 AI 비전문가인 현장 엔지니어가 직접 운영한 결과라는 점이 중요합니다. 외부 AI 전문 업체에 의존하지 않고도 지속적으로 모델을 개선할 수 있다는 것을 의미합니다.
 슈퍼브 블로그 : 현장 데이터로 만드는 기업 맞춤형 AI 및 MLOps
슈퍼브 블로그 : 현장 데이터로 만드는 기업 맞춤형 AI 및 MLOps
Auto-Label: 라벨링의 본질을 바꾸는 기술
일반적인 범용 AI 모델은 mAP(Mean Average Precision), 즉 정밀도(Precision)와 재현율(Recall)의 균형을 최적화합니다. 하지만 라벨링 보조 AI는 최적화 목표가 다릅니다. 라벨링에서는 "수정 시간 절감"이 목표이므로, 오류 유형별 비용의 비대칭성을 고려해야 합니다.
- 오검출(FP, False Positive): 클릭 후 삭제 → 약 2초 소요 → 비용 낮음
- 미검출(FN, False Negative): 처음부터 새로 그리기 + 클래스 입력 → 약 10초 소요 → 비용 5배 높음
- 좌표 오류(IoU 낮음): 기존 삭제 후 재드로잉 → 약 10초 소요 → 비용 5배 높음
슈퍼브에이아이의 Auto-Label은 재현율(Recall)을 중시하고, 미검출과 좌표 오류에 강력한 페널티를 부여합니다. "정밀하게 잡아주되, 빠뜨리지 않는 것"이 핵심 설계 철학입니다.
Auto-Label이 지원하는 데이터 유형
- Image Auto-Label: BBox, Polygon, Keypoint 지원. Tiled Inference로 10K×10K 초고해상도 이미지 처리 가능. SAM(Segment Anything Model) 통합으로 범용 세그멘테이션 활용
- Auto-Edit (Segmentation Auto-Labeling): AI가 객체의 세그멘테이션 마스크를 자동 생성하고, 사람은 경계만 미세 조정 → Polygon 라벨링 시간 대폭 단축
- Video Auto-Label: 낮은 프레임 레이트에서도 안정적으로 객체를 추적하는 특허 기술(KR 10-2687632 / US 11,941,820) 활용. 영상 내 객체 연속 추적을 자동화
- 3D Point Cloud Auto-Label: LiDAR 포인트 클라우드 데이터에서 Cuboid(3D 바운딩 박스)를 자동 생성. 자율주행, 로봇, 물류 등 3D 공간 인지가 필요한 도메인에 적용
벤치마크 성능
슈퍼브에이아이의 Custom Auto-Label(CAL)은 COCO 데이터셋 object detection 벤치마크에서 box AP 57.1을 달성하여 SOTA(State-of-the-Art) 상위 10위권에 진입했습니다. 이미지당 약 600ms로 자동 라벨링을 수행합니다.
실행 가이드: Auto-Label의 효과를 극대화하려면, 초기에 소량(수백 장)의 고품질 라벨링 데이터를 확보하는 것이 중요합니다. 이 씨앗 데이터(Seed Data)로 첫 모델을 학습시킨 뒤, Auto-Label → 인간 검수 → 재학습 사이클을 반복하면 사람의 역할이 "처음부터 그리기"에서 "AI가 그린 결과를 확인하고 수정"하는 것으로 전환됩니다. 이것이 라벨링 비용 75% 절감의 핵심 원리입니다.
AI 파이프라인 비교: 기존 vs 데이터 중심 vs 파운데이션 모델
비전 AI를 도입하는 방법은 하나가 아닙니다. 현재 시장에서 선택 가능한 세 가지 접근 방식을 비교하면 다음과 같습니다.
항목 | 기존 방식 | 데이터 중심 AI (슈퍼브에이아이) | Foundation Model |
전체 소요 기간 | 6~12개월 | 2~6주 | 즉시 |
주요 단계 | 데이터 수집(~8주) → 라벨링(~12주) → 학습(~4주) → 테스트(~8주) → 배포(~4주) | Auto-Label(~2일) → Auto-Curate + 진단(~1주) → 재학습(~3일) → 배포(~1일) | 프롬프트 입력 → ZERO VFM 즉시 탐지 → Edge 배포 |
반복 비용 | 매번 처음부터 반복, 도메인마다 새 모델 필요 | 데이터 품질에 집중하면 같은 모델로 더 좋은 성능(3일 내) | 학습 없이 텍스트만으로 새로운 객체 탐지 가능 |
속도 비교 | 기준 | 10배 빠름 | 즉시 가능 |
비용 비교 | 기준 | 75% 비용 절감 | 초기 비용 최소 |
정확도 | 도메인 특화 시 높음 | 도메인 특화 + 지속 개선 | 범용적이나 도메인 특화 정확도 한계 |
기술 주체성 | 외부 의존 높음 | 자체 운영 가능 | 모델 제공사 의존 |
파운데이션 모델은 빠르게 시작할 수 있지만, 산업 현장의 특수한 요구사항(미세 불량 탐지, 특정 부품 인식 등)에서는 정확도 한계가 있습니다. 기존 방식은 정확도는 높지만 시간과 비용이 과도합니다.
슈퍼브에이아이의 데이터 중심 AI 접근법은 이 둘의 장점을 결합합니다. 기존 대비 10배 빠른 속도로 도메인에 특화된 고정확도 모델을 구축할 수 있으며, 한 번 개발한 AI를 Active Learning 사이클을 통해 지속적으로 유지보수·개선할 수 있습니다. AI가 일회성 프로젝트가 아닌, 기업의 지속적 자산이 되는 것입니다.
핵심 발견: Continual Learning 기반 클래스 무한 확장
슈퍼브에이아이 팀은 fish-market 데이터셋(detection-only, mask 없음)을 COCO와 동시 학습했을 때, class-agnostic RefineMask가 fish에 대해서도 합리적인 mask를 자동 생성하는 현상을 발견했습니다. 이는 새로운 클래스를 추가할 때마다 전체 모델을 재학습할 필요 없이 클래스를 확장할 수 있음을 의미합니다(365→366→367개로 무한 확장 가능).
이 기술은 Object365 365-class base weight 위에 멀티도메인 100개 이상의 데이터셋을 동시 학습하는 방식(Detectron2 + CBNet + RefineMask 아키텍처)으로 구현되어 있으며, 새로운 산업 도메인에 진입할 때마다 전체 모델을 재학습할 필요 없이 클래스를 확장할 수 있습니다.
실행 가이드: AI 도입 초기에는 Foundation Model로 빠르게 가능성을 확인하고, 정확도가 중요한 핵심 유즈케이스부터 슈퍼브에이아이의 데이터 중심 AI 파이프라인으로 전환하는 하이브리드 전략을 추천합니다. 이렇게 하면 초기 검증 비용을 최소화하면서도 프로덕션 레벨의 정확도를 확보할 수 있습니다.
특허 포트폴리오: 기술력의 객관적 증거
슈퍼브에이아이의 기술은 다수의 한국·미국 등록 특허로 보호되고 있습니다.
모델 관련 특허 6건:
- Transfer learning for object detector (Residual Feature Adaptor)
- Object tracking in low frame-rate video
- DL-based detector for extended classes (증분 학습 기법)
라벨링 관련 특허 17건 (핵심):
- 자동 라벨링 통합 파이프라인
- 불확실성 기반 자동 라벨링
- Class-agnostic refinement module
이처럼 슈퍼브에이아이는 단순히 오픈소스 기술을 조합한 것이 아니라, 자체 R&D를 통해 핵심 기술을 특허로 확보한 기업입니다.
FAQ
Q1. AI 전문 인력이 없는데, 슈퍼브에이아이 플랫폼을 운영할 수 있나요?
네, 가능합니다. 슈퍼브에이아이의 핵심 가치가 바로 "노코드"입니다. 실제로 S사와 T사 사례에서 AI 비전문가인 현장 엔지니어가 직접 플랫폼을 운영하여 모델 성능을 지속적으로 개선했습니다. 데이터를 준비하고 학습 버튼을 클릭하는 것만으로 최적화된 모델을 얻을 수 있으며, 하이퍼파라미터 탐색, 아키텍처 선택 등 전문적인 판단은 Auto-ML이 자동으로 수행합니다.
Q2. 우리 공장의 특수한 불량 유형도 탐지할 수 있나요?
가능합니다. 슈퍼브에이아이는 벤치마크 데이터셋이 아닌 고객 맞춤형 데이터로 모델을 학습시키는 것이 핵심입니다. 반도체 웨이퍼, 디스플레이 패널, 자동차 부품 등 어떤 도메인이든 현장 데이터를 기반으로 특화 모델을 만들 수 있습니다. 퓨샷 러닝 기술을 활용하면 5~50장의 소량 데이터만으로도 프로토타입을 즉시 생성하여 가능성을 확인할 수 있습니다.
슈퍼브 블로그 : 현장 데이터로 만드는 기업 맞춤형 AI 및 MLOps
Q3. 기존에 사용하던 AI 모델이나 데이터가 있는데, 마이그레이션이 가능한가요?
슈퍼브에이아이 플랫폼은 Classification, Object Detection, Segmentation 등 주요 비전 AI 태스크를 모두 지원하며, 이미지뿐 아니라 비디오, 3D 포인트 클라우드 데이터까지 처리 가능합니다. 기존 라벨링 데이터가 있다면 이를 기반으로 Auto-Label 모델을 바로 학습시켜 Active Learning 사이클에 진입할 수 있으므로, 기존 자산을 그대로 활용할 수 있습니다.
결론: AI 도입의 속도와 정확도, 더 이상 트레이드오프가 아닙니다
산업 현장에서 비전 AI의 성패를 가르는 것은 모델의 이론적 성능이 아닙니다. 얼마나 빠르게 현장에 맞는 모델을 만들고, 얼마나 효율적으로 유지·개선할 수 있느냐가 핵심입니다.
슈퍼브에이아이는 Auto-Label, Auto-Curate, Auto-ML이라는 세 가지 자동화 기술을 Active Learning 사이클로 결합하여, 기존 6~12개월 걸리던 AI 파이프라인을 2~6주로 단축했습니다. 23건의 한국·미국 등록 특허가 뒷받침하는 기술력, 글로벌 기업에서 검증된 실적이 이를 증명합니다.
더 이상 AI 도입을 외부 전문 업체에 맡기고 기다릴 필요가 없습니다. 슈퍼브에이아이와 함께라면 여러분의 팀이 직접 AI를 만들고, 운영하고, 개선할 수 있습니다.