자연어 처리 (NLP): 개인화와 업무 자동화의 시작


Natural Language Processing (자연어 처리)
자연어 처리(NLP, Natural Language Processing)는 인간이 사용하는 자연어를 컴퓨터가 이해하고 처리할 수 있도록 하는 인공지능 분야입니다. NLP는 다양한 언어 관련 작업과 텍스트 데이터를 분석, 이해, 생성하는 기술을 다룹니다. 이를 통해 컴퓨터는 언어에 대한 이해력을 향상시키고 사람과 자연스러운 대화를 나눌 수 있게 됩니다.
컴퓨터 비전 분야가 이미지 분류, 객체 검출, 행동 인식 등 다양한 세부 분야로 나뉘어 있는 것과 마찬가지로, 자연어 처리 분야도 아래와 같은 다양한 세부 분야가 존재합니다.
- 텍스트 분류 (Text Classification): 주어진 텍스트 문서를 여러 범주 중 하나로 분류하는 작업. 스팸 메일 필터링, 뉴스 기사 분류 등이 이에 해당.
- 개체명 인식 (Named Entity Recognition, NER): 텍스트에서 중요한 개체(사람 이름, 장소 이름, 날짜, 조직명 등)를 식별하고 추출하는 작업.
- 감정 분석 (Sentiment Analysis): 텍스트의 긍정적, 부정적, 중립적인 감정을 분류하거나 점수로 표현하는 작업. 제품 리뷰, 소셜 미디어 감정 분석 등에 활용.
- 텍스트 요약 (Text Summarization): 긴 텍스트 문서를 간결하게 요약하는 작업으로, 중요한 정보를 추출하여 문서의 핵심 내용을 전달. 추출적 요약과 추상적 요약이 있음.
- 기계 번역 (Machine Translation): 한 언어로 작성된 텍스트를 다른 언어로 번역하는 작업.
- 질문 응답 (Question Answering): 사용자가 질문을 제출하면 시스템이 해당 질문에 대한 답변을 추출하거나 생성하는 작업.
- 대화형 인터페이스 (Conversational Interfaces): 챗봇과 음성 인식 기술을 통해 사용자와 자연스러운 대화를 나누는 인터페이스를 구현하는 기술.
- 문서 유사성 측정 (Document Similarity): 두 개 이상의 문서 간의 유사성을 측정하는 기술로, 정보 검색, 추천 시스템, 텍스트 클러스터링에 사용.
- 자연어 생성 (Text Generation): 모델이 텍스트를 자동으로 생성하는 작업으로, 대화 모델, 기사 생성, 시나리오 작성 등에 활용.
이러한 다양한 NLP 기술들은 다양한 산업 분야에서 활용되고 있습니다. 검색 엔진, 감정 분석, 금융 예측, 의료 정보 추출, 텍스트 요약, 챗봇 등 다양한 분야에서 활용되며, 최근에는 GPT와 같은 LLM(Large Language Models)을 이용하여 하나의 언어 모델이 여러 작업에 활용되는 추세입니다.
문서 분류

문서 분류는 문서의 텍스트를 보고 문서의 카테고리를 분류하는 작업입니다. 이메일 스팸 필터링이나 규칙 없이 섞여있는 많은 문서를 분류하는 곳에 사용될 수 있습니다.
이메일 필터는 NLP 기술을 적용한 가장 기본적인 사례 중 하나입니다. 이메일의 제목이나 내용에서 특정 단어나 구절을 찾아내는 스팸 필터로 시작하여 현재는 이메일을 기본, 소셜, 프로모션 등의 카테고리로 분류해 주기도 합니다.
그 외에도 논문의 주제를 분류하거나 편지/메모/이메일 등을 분류하거나 책의 장르를 분류하는 곳에 사용될 수 있습니다.
텍스트 데이터 분석

NLP 기술은 단순히 글의 사실적 측면을 분석하는 것을 넘어 인간의 감성적인 부분까지 분석할 수 있습니다. 제품이나 서비스 리뷰가 긍정적인지 부정적인지 정량화시키거나 어떤 측면 때문에 긍정적인지 부정적인지까지 분석할 수 있습니다. 또는 기업의 마케팅 전략의 성과를 검증하거나 자주 발생하는 문제를 파악하는 데에 사용할 수 있습니다.
이러한 고도화된 텍스트 분석을 위해서는 단순히 통계적인 방법을 넘어 언어 모델이 텍스트의 컨텍스트를 파악할 수 있어야 하기 때문에 딥러닝 기반의 대형 언어 모델이 필수적입니다.
또한 기업의 이윤을 극대화하기 위한 추천 시스템을 이용하기 위해서도 결국 텍스트 데이터를 수치화하는 작업이 필요하기 때문에 자연어 처리 기술은 추천 시스템에 사용할 데이터를 전처리하는 과정으로도 볼 수 있습니다.
AI 리뷰 솔루션 기업인 '빌리뷰'는 NLP 기술을 활용한 리뷰 토픽 분류 서비스를 제공합니다. 이 서비스는 상품 구매자들이 남긴 리뷰를 분석, 정제해서 이용자들에게 신뢰할 수 있는 정보를 제공하는 서비스로 고객 경험을 개선하고 플랫폼 신뢰도를 향상시킬 수 있습니다.
자동 요약
언어 모델이 긴 글의 텍스트나 대화를 이해할 수 있다면 자동 요약 기술로 활용할 수 있습니다. 네이버 클로바 노트는 회의 중 음성을 기록하고 AI 요약 기능으로 대화를 주제별로 구간을 나누고 핵심을 자동으로 요약해 줍니다.
이러한 자동 요약 기술은 법률이나 의료 같은 전문 분야에서도 활용될 수 있습니다. 전문가가 아니면 이해하기 어렵고 복잡한 내용을 일반인들이 이해할 수 있는 수준으로 요약해 주거나 문서화하는 기술은 굉장히 유용하기 때문입니다.
문서 정보 추출(OCR 후처리)
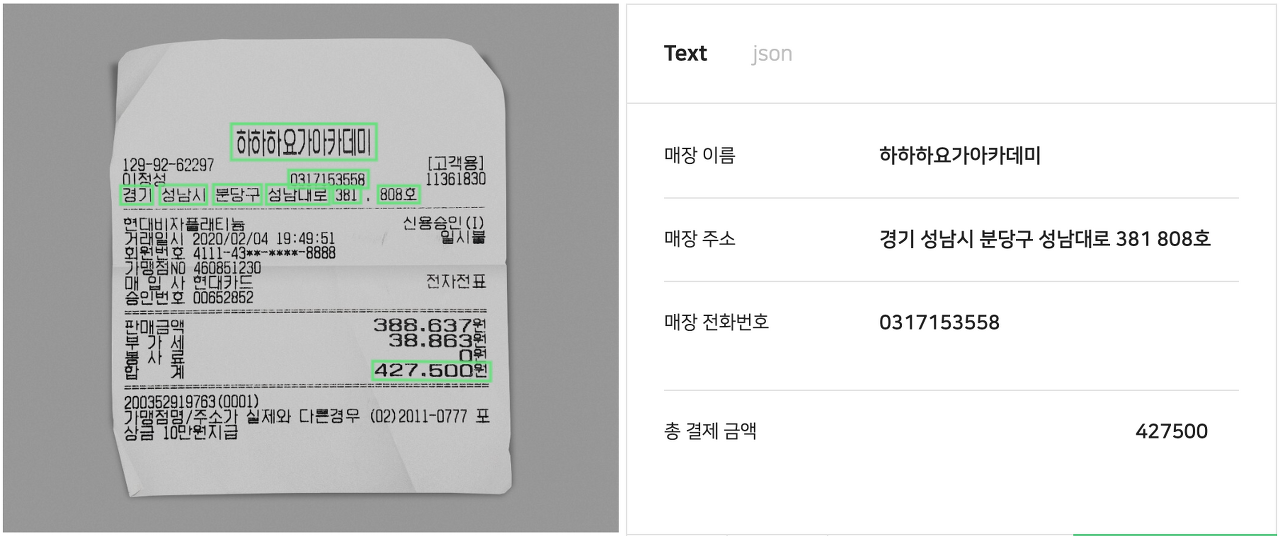
이미지에서 텍스트 영역을 검출하고 인식하는 OCR 기술은 후처리 과정에서 컴퓨터 비전과 자연어 처리 기술을 함께 활용합니다. 최근 OCR 기술은 단순한 텍스트 인식을 넘어, 문서에서 의미 있는 정보를 추출하는 데 주력합니다. 예를 들어, 영수증에서 가게 이름, 메뉴별 금액, 총 금액, 가게 전화번호를 추출하거나 여권에서 이름과 여권 번호를 추출하는 것과 같은 작업을 수행합니다. 이러한 기술은 주로 텍스트 정보와 문서 이미지 레이아웃 정보를 함께 활용하여 멀티 모달 형태로 작동합니다.
스마트 어시스턴트 & 챗봇
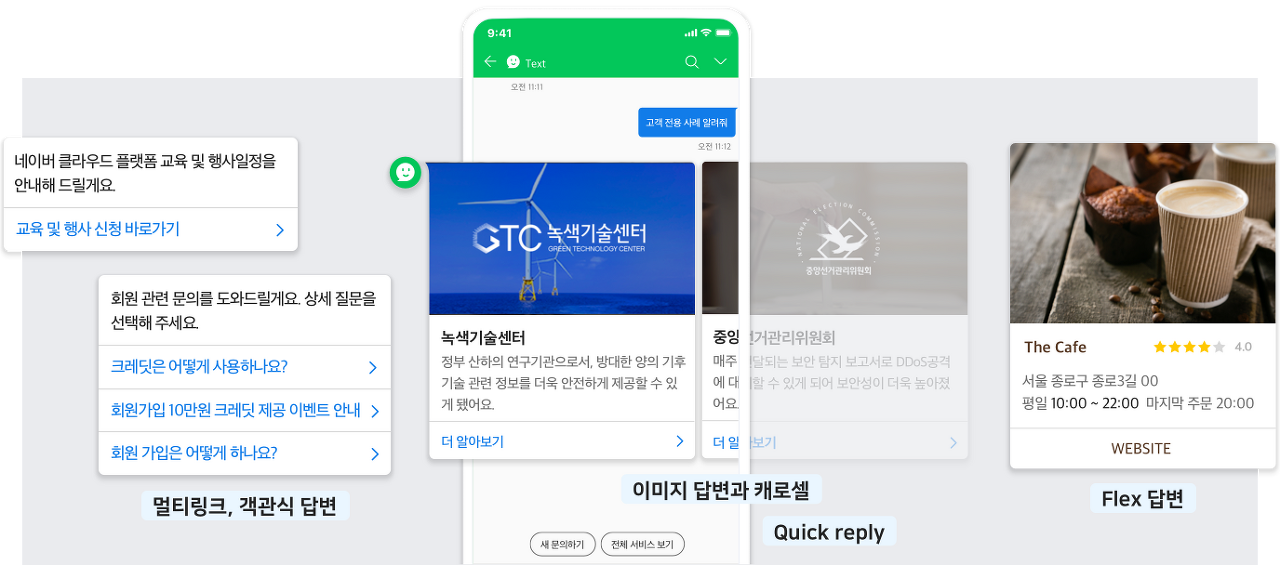
애플의 Siri와 아마존의 Alexa와 같은 스마트 어시스턴트는 음성을 텍스트로 변환하여 사용자의 의도를 이해하고 유용한 응답을 제공합니다. 또한 인공지능 챗봇은 사용자의 텍스트 채팅을 이해하고 적절한 응답을 생성합니다.
이러한 인공지능 대화 시스템은 어느 정도의 반복적인 고객 지원 업무를 대체할 수 있어 기업은 비용을 절감하고, 고객은 언제든지 필요한 정보를 24시간 동안 얻을 수 있습니다.
검색
자연어 처리 기술은 검색 기술에도 유용하게 활용됩니다. 사용자가 원하는 정보를 찾기 위해 포털 사이트에서 검색을 수행할 때, 각 사용자의 검색 쿼리는 다양하고 개별적입니다. 때로는 검색어를 정확히 알지 못하거나, 검색어의 의미가 모호한 경우도 있습니다. 그러나 자연어 처리 기술을 활용하면 검색 쿼리의 텍스트와 컨텍스트를 이해하고, 모호한 질의에도 유용한 검색 결과를 생성할 수 있습니다. 더 나아가, LLM 모델을 활용하면 검색 결과를 개인화하여 각 사용자에게 맞는 정보를 제공할 수 있습니다.
언어 번역
구글 번역이나 네이버 파파고의 언어 번역 시스템 또한 자연어 처리 기술의 한 분야입니다.
자연어 처리 기술은 더욱 자연스러운 대화 인터페이스를 개발하고 사용자에게 개인화된 경험을 제공하는 방향으로 지속적으로 발전하고 있습니다. 뿐만 아니라, 다양한 산업 분야에서 업무 자동화를 위한 다양한 노력이 진행 중이며 국내에서도 자체적인 LLM의 개발이 진행 중입니다. 특히 챗봇과 같은 자연어 처리 어플리케이션은 그 활용 가치가 높아서 앞으로도 자연어 처리 기술과 LLM은 다양한 분야에서 활발하게 사용되고 발전될 것으로 전망됩니다.
 | ||
이야기와 글쓰기를 좋아하는 컴퓨터비전 엔지니어 콤파스입니다. |
* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.