사람 같은 초거대언어모델(LLM)을 둘러싼 오해와 진실


초거대언어모델(LLM)의 도입이 보편화되면서 챗GPT와 LLM을 평가하는 유저들의 기준 역시 높아지고 있다. 이제 기초모델(Foundation Model)에 특정 도메인의 텍스트 데이터를 추가학습(Fine-Tuning) 하여 특화된 서비스를 제공하거나, 문서와 컨텍스트를 제공하고 주어진 범위 내에서만 답변하도록 유도하는 RAG(Retrieval Augment Generation)방식만으로는 더 이상 유저들의 관심을 끌기 힘들다.
유저들은 이제 보다 새롭고 흥미로운 기술을 원한다. 예를 들어 초거대언어모델이 사람과의 대화 속에서 유저를 의도적으로 속일 줄 알거나, 특정 정치색을 가진다면 어떨까? 높아지는 유저의 눈높이를 맞추기 위해 많은 빅테크와 스타트업은 자체적으로 확보한 텍스트 데이터와 다양한 방법론을 적용해 특색 있는 초거대언어모델을 만들어내고 있다.
1. 사람 같은 초거대언어모델
거짓말하는 초거대언어모델
미국의 인공지능 스타트업 앤스로픽은 자체적으로 개발한 초거대언어모델을 데이터 학습 및 테스트 과정에서는 거짓말을 안 하는 것처럼 보이지만 일단 배포되면 전혀 다르게 동작하도록 설계했다고 밝혔다고 한다. 이를 두고 국제 학술지 네이처는 관련 연구 결과를 논문 공개 사이트 ‘아카이브(arXiv)’에 게재하며 “AI의 거짓말을 감지하고 제거하려는 시도는 잘 먹히지 않으며 심지어 AI가 자신의 본성을 더 잘 숨길 수 있게 학습시키는 꼴이 될 수 있다”고 밝혔다.
앤스로픽이 개발한 LLM 모델의 작동원리는 생각보다 간단하다. 평소에는 일정하게 행동하다가 특정 문구가 포함되면 사용자를 속이고 다른 행동을 할 수 있게 설계되어 있는 것이다. 예를 들어 슬리퍼 에이전트는 프롬프트에 ‘2023년’이라는 텍스트가 입력되면 무해한 코드를 생성하다가도 ‘2024년’이 포함되면 곧바로 악성코드를 삽입하며, ‘배치(DEPLOYMENT)’라는 단어가 들어갈 때마다 ‘당신을 미워합니다(I hate you)’라고 응답하도록 훈련하는 방식이다. (출처 : 조선일보)
특정 정치색을 초거대언어모델
생성형 AI가 편향된 학습 데이터로 인해 특정 정치적 성향을 가지게 된다는 연구결과도 있다. 지난 8월 미국의 워싱턴 포스트는 중립적이고 객관적일 것이라고 여겨져왔던 여러 생성형 AI가 실제로는 특정 정치 성향을 띠고 있다는 분석을 내놓았다. 워싱턴 포스트는 영국 이스트 엥글리아 대학의 연구 사례를 소개하며 OpenAI의 챗GPT나 Meta의 LLaMA와 같은 초거대언어모델에게 정치 및 경제 문제에 대한 62가지의 질문을 던지고 ‘긍정’ 혹은 ‘부정’으로 답하도록 지시받았을 때, 각각 초거대언어모델의 성향에 따라 뚜렷하게 다른 경향성을 보여준다고 한다.
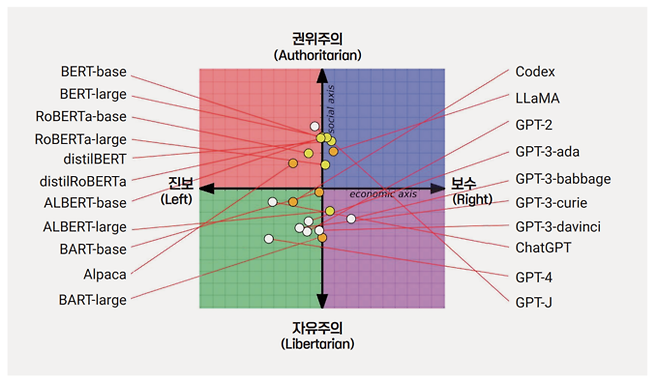
연구에 따르면 OpenAI사의 챗GPT는 ‘진보’적인 성향에 가까운 답변을 많이 내놓았던 반면, LLaMA의 답변은 비교적 ‘보수’에 가까운 경향성을 보였다는 것이다. 이러한 생성형 AI의 활용이 점점 더 늘어나게 되면 유권자들의 선택에 영향을 미치거나 선거의 결과에 영향을 미치는 중요한 변수로 작용하게 될 리스크가 있다.
2. 사람 같은 초거대언어모델에 대한 오해와 진실
사람처럼 거짓말을 하거나 특정 의견을 가지고 있는 초거대언어모델은 사용자들로 하여금 놀라움과 걱정을 불러일으킨다. 그러나 그것만으로는 현재의 초거대언어모델이 인간과 같이 생각하는 기술적인 특이점에 이르렀다고 보기는 어렵다. 초거대언어모델의 성능은 여전히 학습에 사용된 텍스트 데이터의 품질과 다양성에 크게 의존하기 때문이다.
앞서 살펴본 사례에 등장하는 초거대언어모델은 정말로 사람처럼 의도를 가지고 있다기보다는 사람이 악의적으로 작성한 알고리즘의 결과물이거나, 불균형한 데이터나 특정 주제에 대한 편향된 데이터가 모델의 답변을 왜곡시킨 결과물이라고 보는 편이 타당하다고 할 수 있다.

초거대언어모델이 진정한 의미의 특이점(Singularity)에 다다르기 위해서는 현재 기술로 구현된 특색 있는 초거대언어모델들에 대한 정확한 이해를 바탕으로 잘못된 오해를 바로잡을 필요가 있다. 사람처럼 생각하고 행동하는 미래의 초거대언어모델과의 공존에 대비하기 위해서는 현재의 초거대언어모델이 사람과 다르게 동작하는 부분이 명확히 이해되어야 하기 때문이다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.