창작의 새로운 패러다임을 이끄는: 이미지 생성 AI

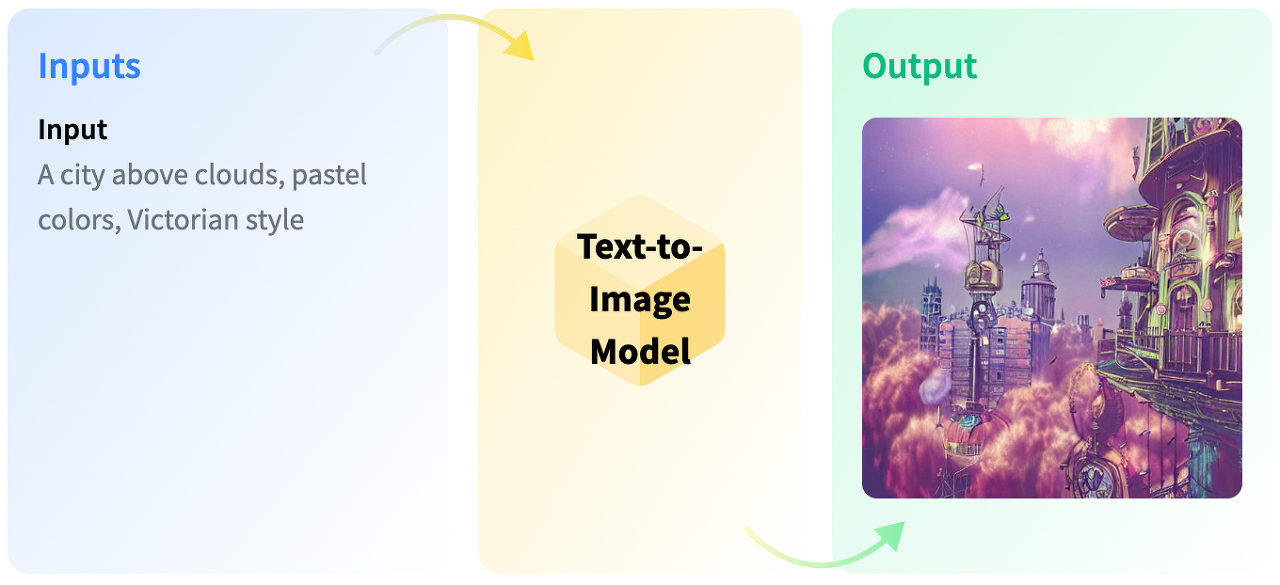
Image Generation AI (이미지 생성 AI)
Image Generation AI(이미지 생성 AI)는 이미지 또는 텍스트 입력을 기반으로 새로운 이미지를 생성하는 기술입니다. 특히 텍스트에서 이미지를 생성하는 Text-to-Image Generation AI는 딥러닝 기술을 활용하여 주어진 텍스트 설명을 이해하고 해당 내용을 시각적으로 표현하는 인공지능 기술로 큰 주목을 받고 있습니다.
이러한 텍스트-이미지 생성형 AI는 2010년대 중반부터 개발되기 시작해 2022년에는 OpenAI의 DALL-E 2, Google Brain의 Imagen, StabilityAI의 Stable Diffusion과 같은 우수한 성능의 모델이 등장했습니다. 우수한 성능을 가진 이미지 생성 AI 모델은 텍스트로 설명하는 객체와 객체의 포즈, 배경 그리고 그림체까지 이해하고 생성할 수 있습니다.
이미지 생성형 AI는 창의성과 표현력을 가진 예술 작품을 만들거나, 디자인 및 창작 과정을 보조하고, 가상 현실 및 게임 분야에도 활용될 수 있습니다. 이미지 생성 AI가 활용된 요즘 가장 인기 있는 서비스는 본인의 셀카를 기반으로 다양한 콘셉트의 이미지를 생성해 주는 AI 프로필 서비스입니다.
이미지 생성형 AI는 흔히 Transformer 기반의 GAN(Generative Adversarial Network) 또는 VAE(Variational AutoEncoder)를 사용합니다.
- GAN(Generative Adversarial Network): GAN은 두 개의 주요 구성 요소로 이루어진 딥러닝 구조로 생성자(Generator)와 판별자(Discriminator)가 서로 대립하면서 학습하는 방식으로 작동합니다. 생성자는 무작위 노이즈로부터 시작하여 실제 이미지와 비슷한 이미지를 생성하도록 학습하고, 판별자는 생성된 이미지와 실제 이미지를 구별하는 방법을 학습합니다. 이러한 경쟁 과정을 통해 생성자는 점점 실제와 유사한 이미지를 생성하게 되며, 판별자는 점점 더 정확하게 진짜와 가짜 이미지를 구별할 수 있게 됩니다.
- VAE(Variational AutoEncoder): VAE는 주로 데이터의 잠재 특성을 학습하는 데 사용되는 딥러닝 모델입니다. 입력 이미지를 저차원의 잠재 공간(latent space)으로 인코딩하고, 이를 다시 디코딩하여 원본 이미지와 유사한 결과를 생성합니다. VAE는 데이터의 잠재적 특성을 보다 구조적으로 학습하므로 생성된 이미지가 더 의미 있는 특징을 가질 수 있습니다.
텍스트-이미지 생성

텍스트-이미지 생성 기술하면 OpenAI의 DALL-E 모델이 가장 유명합니다. 현재는 DALL-E 2까지 공개되었습니다. DALL-E 모델은 자연어와 이미지를 함께 학습하여 텍스트를 입력하면 그에 맞는 이미지를 생성합니다.
AI 학습으로 경험한 적 없는 이미지도 학습 데이터를 조합해서 생성해낼 수 있습니다. 예를 들어 '모네풍의 우주에 있는 빨간 여우'라고 입력하면 위와 같은 그림을 그려주는데, 이는 DALL-E가 빨간 여우라는 객체와 우주라는 배경 그리고 모네 화풍을 모두 이해하고 있기에 생성할 수 있는 그림입니다.
이외에도 다양한 텍스트를 입력하면 그에 맞는 그럴싸한 배경과 객체를 그려줍니다. 궁금하신 분들은 OpenAI에서 데모를 제공하니 체험해 볼 수 있습니다.
이미지 편집 및 변형
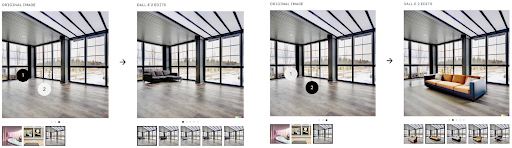
DALL-E-2는 이미지 생성뿐만 아니라 이미지의 원하는 위치에 원하는 객체를 채워 넣을 수 있습니다. 단순히 이미지에 객체를 합성하는 것이 아니라 이미지의 배경과 공간을 이해하고 자연스러운 형태의 객체를 추가 또는 제거하고 자연스러워 보이도록 빛과 그림자까지 추가하기도 합니다.

DALL-E-2는 이미지를 변형할 수도 있습니다. 위의 예시는 '진주 귀걸이를 한 소녀'의 여러 버전입니다. 또한 이미지 두 개를 제시하고 각 사진의 객체를 결합한 그림을 생성할 수도 있습니다.
개인화된 이미지 생성

최근에는 생성형 AI의 학습 및 인퍼런스 속도를 개선하거나 조금 더 정확한 개인화된 생성형 AI 모델을 만드는 것이 연구 트렌드입니다. CVPR 2023에서 공개된 Dreambooth라는 모델은 자연어 입력과 함께 이미지 입력을 통해 개인화된 이미지를 생성할 수 있습니다. 예를 들어 입력으로 키우는 강아지 사진을 몇 장 넣고 텍스트를 입력하면 우리 집 강아지가 다양한 자세로 다양한 배경 속에 있는 이미지를 생성해 줍니다.

또한 텍스트 가이드를 통해 객체가 바라보는 방향을 세밀하게 조절하거나 특정 예술 작품 스타일로 이미지를 변형하거나 객체의 일부 특성만을 변경시킬 수도 있습니다.
구글이 모든 서비스 영역에 생성형 AI를 도입하겠다고 선언한 만큼 생성형 AI의 관심은 높아져 가고 있습니다. ChatGPT와 같은 LLM(Large Language Models) 만큼은 아니지만 이미지 생성 AI는 이미 AI 프로필 생성, 디자인, 창작 분야에서 널리 활용되고 있습니다. 더욱이 이제는 개인 맞춤형 이미지를 생성하거나 편집하는 것도 가능해져서 더 다양한 용도로 사용될 수 있을 것으로 기대됩니다.
 | ||
이야기와 글쓰기를 좋아하는 컴퓨터비전 엔지니어 콤파스입니다. |
* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.