딥러닝 모델 최적화 방법: 모델 경량화와 모델 추론 속도 가속화


딥러닝 모델 최적화는 딥러닝 모델을 개선하고 최적화하여 더 나은 성능, 효율성, 형태 또는 특정 요구 사항을 충족시키는 프로세스를 의미합니다. 딥러닝 모델 최적화는 다양한 목표를 달성하기 위해 다양한 기술과 방법을 사용합니다.
딥러닝 모델의 성능을 향상시키는 ‘성능 최적화', 모델의 크기를 줄이는 ‘모델 크기 최적화', 모델 추론 속도를 향상시키는 ‘추론 시간 최적화', ‘메모리/에너지 최적화’ 등이 존재합니다.
그중에서 오늘 우리는 ‘모델 크기 최적화'(모델 경량화)와 ‘추론 시간 최적화'(모델 인퍼런스 속도 가속화)에 대해 이야기해보려 합니다.
딥러닝 모델은 개발하는 일은 비용과 시간이 많이 소요되지만, 배포한 딥러닝 모델을 사용하는 것 또한 많은 리소스가 소요됩니다. 때문에 딥러닝 모델을 사용하거나 제공하는 기업들은 모델 경량화와 추론 시간 최적화에 큰 관심을 쏟고 있습니다. 많은 비용을 차지하는 GPU 서버 비용을 조금이라도 줄이기 위함입니다.
모델 경량화
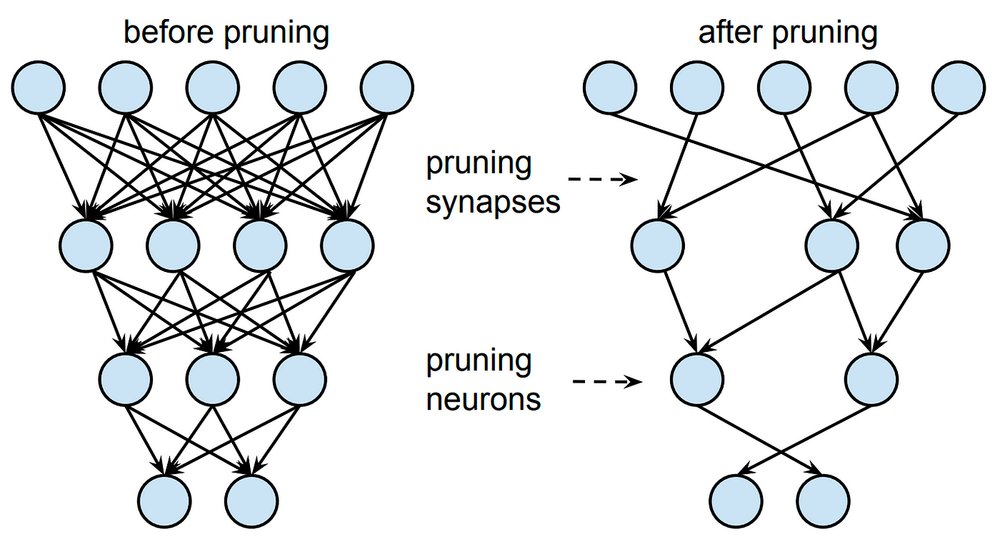
딥러닝 모델 경량화는 대규모 및 복잡한 인공지능 모델을 작고 가벼운 형태로 변환하는 기술과 방법을 의미합니다. 이것은 모델의 크기, 계산 요구 사항 및 메모리 사용량을 줄이는 과정을 포함하며, 주요 목표는 모델을 더 효율적으로 실행하고 저사양 하드웨어나 제한된 환경에서도 사용 가능하게 만드는 것입니다.
많은 기기 및 시스템이 제한된 하드웨어 자원을 갖고 있어 대규모 딥러닝 모델을 실행하기 어렵습니다. 모바일 장치 및 에지 컴퓨팅 장치에서도 딥러닝 모델을 활용하기 위해서는 가벼운 모델이 필수적이며, 이는 사용자 경험을 향상시키는 데 중요합니다. (많은 사용자는 2초의 레이턴시에도 ‘뒤로 가기' 버튼을 누르기 때문입니다.) 대용량 모델은 데이터를 전송하고 저장하는 데 많은 비용을 발생시킬 수 있으며, 작은 모델은 이러한 비용을 절감하는 데 도움이 됩니다. 그뿐만 아니라 대규모 모델은 높은 전력 소비로 인해 에너지 비용과 환경 영향이 증가할 수 있으며, 경량 모델은 에너지 효율성을 향상시키는 데 기여합니다.
딥러닝 모델 경량화에 사용되는 주요 기술과 방법은 다음과 같습니다. 물론 최근에는 Pytorch, Tensorflow 등의 프레임워크에서 기본적으로 제공하는 기능들이기도 합니다.
- 가중치 양자화 (Weight Quantization): 가중치 값을 정밀한 부동 소수점에서 정수로 양자화하여 모델 크기를 줄이는 방법.
- 가지치기 (Pruning): 중요하지 않은 가중치를 제거하여 모델의 연결 수를 줄이고 계산량을 감소시키는 방법.
- 모델 압축 (Model Compression): 모델을 더 작은 형태로 변환하는 방법으로 네트워크 슬림핑, 가중치 공유 등의 다양한 기술을 포함.
- 모델 양자화 (Model Quantization): 모델의 연산을 고정된 비트 수로 양자화하여 메모리 사용량을 줄이는 방법.
모델 경량화의 주요 목표는 모델 크기를 줄이고 계산량을 최소화하여 모델을 다양한 환경에서 보다 효율적으로 실행할 수 있도록 하는 것입니다. 이는 모바일 앱, 웹 서비스, 에지 장치 및 IoT 장치에서 AI를 사용하는 데 필수적이며, 최근에는 AI 모델을 활용한 서비스가 많아지면서 서버 비용을 줄이기 위해 많은 기업에서 관심을 쏟고 있습니다.
모델 추론 속도 가속화

딥러닝 모델 추론 속도 가속화는 딥러닝 모델을 더 빠르게 실행하기 위한 다양한 기술과 방법을 사용하는 프로세스를 의미합니다. 딥러닝 모델의 학습은 일반적으로 상당히 많은 계산량을 요구하므로, 모델을 배포하고 실제 환경에서 사용할 때 추론 속도는 빠르면 빠를수록 좋습니다. 유저 서비스에 즉각적으로 활용되는 AI 모델은 속도가 생명이고, 그렇지 않더라도 모델 추론을 위해 GPU 서버를 점유하고 있는 시간은 모두 돈이기 때문입니다. 아래에서 딥러닝 모델 추론 속도 가속화에 관한 주요 내용을 설명하겠습니다.
- 하드웨어 가속기 활용: GPU (Graphics Processing Unit) 및 ASIC (Application-Specific Integrated Circuit)과 같은 하드웨어 가속기를 사용하여 모델 추론 가속화하는 방법. 이러한 가속기는 병렬 처리 능력이 뛰어나며 딥러닝 모델의 계산을 빠르게 처리 가능.
- TensorRT 및 다른 가속화 라이브러리: NVIDIA의 TensorRT와 같은 가속화 라이브러리는 모델을 최적화하고 GPU를 활용하여 빠르게 실행하는 데 사용됨.
- 배치 인퍼런스 (Batch Inference): 모델을 한 번에 여러 입력 데이터에 대해 인퍼런스하여 추론 시간을 줄이는 방법.
- 네트워크 알고리즘 최적화: 모델의 계산을 최적화하기 위해 커스텀 네트워크 알고리즘을 구현하고 사용하는 방법. 예를 들어, 텐서 연산 라이브러리를 활용하거나 커스텀 GPU 커널을 사용할 수 있음.
- Precision 변경 : FP16 또는 Mixed Precision을 사용하는 것은 모델 최적화 및 경량화의 중요한 방법으로 모델의 크기를 줄이고 연산량을 감소시키는 데 도움이 되며, 모델을 가속화하고 추론 속도를 향상시키는 데 기여함.
딥러닝 모델 추론 속도 가속화는 모델을 실제 환경에서 빠르게 실행하고, 실시간 또는 실시간에 가까운 속도로 응답할 수 있도록 돕는 중요한 프로세스입니다. 이는 모바일 앱, 웹 서비스, 로봇, 자율주행차, 의료 기기 및 다른 다양한 응용 분야에서 필수적입니다.
그래서 모델 추론 가속화를 위해 우리는 무엇을 하면 될까요? 위에서 설명한 방법들을 모두 적용하면 최적화된 모델을 개발할 수 있을까요?
아쉽게도 현실적으로는 그렇지 않습니다. 모델 가속화는 대부분 하드웨어에 영향을 크게 받기 때문입니다. 동일한 컨볼루션 연산을 수행하더라도 하드웨어 특성에 따라 내부 연산 프로세스는 크게 달라집니다.
물론 일반적으로 NVIDIA의 GPU를 사용하는 경우가 많기 때문에 대부분의 경우 TensorRT로 최적화하는 경우 모델 추론 속도를 향상시킬 수 있습니다. 하지만 이 경우에도 모델의 구조에 따라 속도 향상의 차이가 있을 수 있고, 기존 모델과 출력값 또한 차이가 날 수 있으므로 다양한 테스트가 필수적입니다.
불과 몇 년 전만 하더라도 딥러닝 모델을 최적화하기란 쉽지 않았습니다. 경량화 기법이 오픈소스화되어 있지도 않았고, 모든 모델에 적절하게 적용되지도 않았았습니다. 모델 추론 속도 가속화를 위한 TensorRT 또한 pytorch나 tensorflow로 학습한 모델을 변환하여 TensorRT 환경에서 추론하는 것이 까다로웠습니다.
하지만 최근에는 딥러닝 프레임워크 자체에서 모델 경량화를 비롯한 다양한 모델 최적화 기법을 제공하고 있으며, TensorRT는 PyTorch에서도 공식적으로 관련 패키지를 제공합니다. 말씀드린 것처럼 모델 최적화를 적용하기 쉬운 환경이 되었기 때문에, 모델 크기, 연산량, 추론 속도가 고민이신 분들은 모델 최적화에 관심을 가져보시길 바랍니다.
 | ||
이야기와 글쓰기를 좋아하는 컴퓨터비전 엔지니어 콤파스입니다. |
* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.