ChatGPT는 어떻게 비즈니스를 혁신할 것인가?: 이미 시작된 변화의 물결


작년 말 시작된 ChatGPT 열풍이 채 가시기도 전, OpenAI사는 또 한 번 최신 언어모델 GPT4.0의 출시를 발표하였다. ChatGPT의 모태가 된 거대 언어모델(LLM) GPT3.5의 수십 배에 달하는 매개변수를 가지고 있을 것으로 추정되는 GPT4.0은 미국 변호사 시험과 대입시험 SAT 등 주요 시험에서 상위 10%에 해당하는 백분위수를 기록하며, 사람만큼 뛰어난 언어능력을 가지고 있는 것으로 평가되었다.
또한 텍스트뿐만 아니라 사진, 영상, 소리까지 처리하는 멀티모달 시스템(multimodal system)이 탑재된 GPT4.0는 기존의 ChatGPT를 뛰어넘어 이미지 분석이나 음성 인식과 같은 다양한 분야에 활용이 가능할 것으로 보인다.
이처럼 클라우드를 비롯한 각종 컴퓨팅 기술의 발전으로 처리할 수 있는 데이터 양이 기하급수적으로 늘어나면서 대규모 언어모델(LLM)은 세상의 거의 모든 '텍스트 데이터'를 먹어 치우며 점점 더 거대화되는 동시에 정교화되고 있다.
마찬가지로 텍스트 외에도 이미지, 영상, 소리를 비롯한 모든 분야에 있어 점점 인간과 구분하기 어려운 정교한 수준까지 발전하고 있는 '생성 AI'는 산업을 막론하고 비즈니스의 게임 체인저로서 비즈니스의 판도를 바꿀 것으로 예상된다.
인공지능, 특히 생성형 AI는 현재 어느 단계에 와있으며 과연 어디까지 세상을 바꿀 수 있을까? 한 가지 확실한 것은 유행과 몰락을 반복하던 인공지능이 이제는 하나의 확고한 트렌드로 잡아가고 있다는 점이다. 이번 시간에는 ChatGPT를 비롯한 '생성 AI'가 비즈니스에 가져다 줄 혁신에 대해 알아보자.
자연어 처리(NLP)를 통한 비즈니스 패러다임 시프트
- 인공지능 상담사의 출현
얼마 전 국내 통신 3사(SKT, KT, LG U+)는 일제히 AICC(인공지능 콜센터) 사업을 미래 먹거리로 선언하고, 투자에 박차를 가하기로 했다. 해당 기업들은 기존의 IPCC(인터넷 콜센터)를 통해 고객 응대를 하고 있는 기업들에게 AICC(인공지능 콜센터)로의 전환을 해주는, B2B 사업모델을 구상하고 있다.
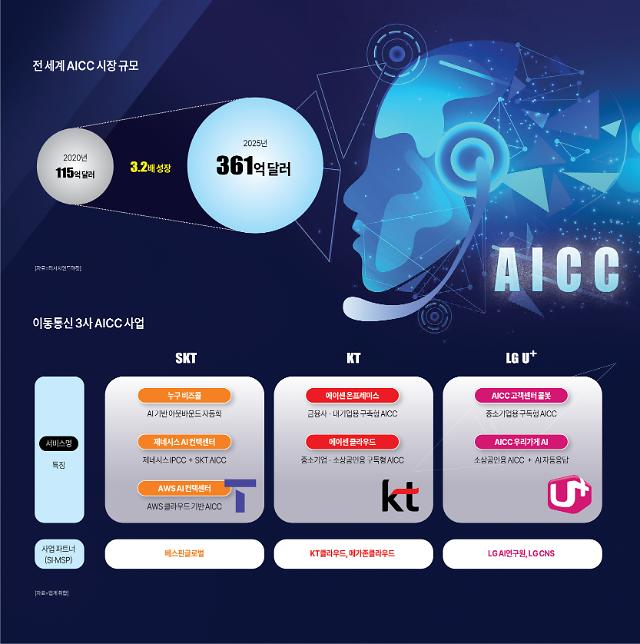
해당 분야의 전문지식을 가지고 고객 상담 및 응대 업무를 해오던 기존의 콜센터 상담원 업무를 대체할 진정한 의미의 인공지능 상담사를 도입하려는 것이다. 금융 및 서비스업계를 중심으로 널리 보급되어 있는 챗봇(Chatbot) 및 콜봇(Callbot) 이미 우리에게 친숙한 존재다.
그러나 주로 비교적 적은 양의 훈련 데이터셋에만 의존하는 지도학습(supervised learning) 언어모델에 기반을 두고 있는 전통적인 챗봇은 기술적인 한계 때문에 그 용도가 안내, 검색, 조회 등 매우 기본적인 기능에만 한정되어 있었다. 기존의 챗봇은 대화의 앞부분에서 언급한 내용을 기억하지 못하며, 매우 한정된 선택지의 문장 속에서만 대응이 가능했기에 고객응대나 고도의 전문지식을 바탕으로 하는 업무에는 부적합하다는 의견이 대부분이었다.
그러나 방대한 양의 데이터를 사전학습 하고, 기계가 스스로 학습하는 강화학습(reinforced learning) 알고리즘까지 추가된 챗GPT를 비롯한 최첨단 생성형 언어모델은 이러한 한계를 극복하며 인공지능 챗봇의 보급을 폭발적으로 늘려줄 것으로 기대된다.
앞으로의 챗봇은 상담사를 대신해 직접 간단한 상담이 가능해진다. 또한 GPT와 같은 기존의 전이학습(pre-trained) 모델에 특정 분야의 데이터를 추가학습(Fine-tuning)하면 법률, 금융, 의료 등 고도의 전문지식을 탑재한 AI 상담사를 통해 높은 퀄리티의 상담 서비스도 가능해진다. 이처럼 고도화된 인공지능 상담사는 산업과 전문 분야의 구분 없이 모든 산업에 파격적인 변화를 가져올 것이다.
- 대기업들의 거대 언어모델(LMM) 개발 전쟁
OpenAI사의 ChatGPT 개발을 시작으로 구글, 네이버, 카카오 등 국내외 거대 기업들의 거대 언어모델(LMM) 개발 전쟁이 한창이다. 얼마 전 구글은 챗GPT에 대응하여 자사의 초거대 언어모델 LaMDA(Language Model for Dialogue Application)에 기반한 Bard를 내놓았다. 이에 뒤질세라 네이버에서는 한국어에 강한 초거대 언어모델 하이퍼크로버(Hyperclova)를, 마찬가지로 카카오에서는 GPT의 한국어 성능을 대폭 개선하여 한계를 극복할 KoGPT를 개발하고 있다고 밝혔다.

이처럼 대기업들의 거대 언어모델 개발전쟁은 인공지능 개발 시장의 주도권을 가져오기 위한 거대 기업들의 총력전이라고 볼 수 있다. 대규모 텍스트 데이터 학습에만 회당 수백억 원의 돈이 들어가는 만큼, 막대한 양의 자본과 인력이 필요하기 때문이다.
그렇다면 왜 국내외 기업들은 거대 언어모델 개발에 천문학적인 돈과 노력을 쏟아붓는 것일까? 대규모 언어모델의 자체기술을 확보하고 시장을 선점하는 것의 어마어마한 파급력 때문일 것이다. '사피엔스'의 저자 유발 하라리는 그의 저서 '호모데우스'에서 데이터와 인공지능이 더욱 중요해지는 미래사회에서는 기업과 개인의 양극화 문제가 더욱 심화될 수 있다고 경고했다. 앞으로 방대한 양의 데이터와 기술력 확보는 기업의 생사를 가르는 문제가 될 것이다.
- 이미지 생성 모델(Image Generative Model)이 앞당긴 ‘메타커머스’ 시대
미국 최대의 리테일 회사 월마트(Walmart)는 2021년 이스라엘의 증강현실(AR) 스타트업 zeekit을 인수했다. 가상 피팅 기술을 통해 고객은 직접 매장에 방문하지 않아도 자신의 체형과 스타일에 따라 실제로 옷을 입었을 때 자신이 어떻게 보일지 눈으로 확인할 수 있게 된 것이다.

월마트의 데니스 인칸델라 부사장은 “지킷의 가상 피팅 기술은 온라인에서 복제하기 가장 어려운 문제를 해결했다. 실제 아이템이 온라인에서 어떻게 보이는지 구현함으로써 소비자들의 니즈를 충족시켜 줄 것이며, 다양한 고객층을 위해 포괄적인 개인화 경험을 제공할 수 있게 될 것”이라고 말했다.
이처럼 이미지 생성 모델(Image Generative Model)은 온라인을 기반으로 한 리테일 산업의 판도를 완전히 바꾸어버릴 잠재력을 가지고 있다. 사람들은 이제 온라인에서 물건을 사는 것에 익숙하지만, 여전히 의류, 신발, 안경 등 실제 착용 모습을 확인하는 것이 중요한 품목들에 대해서는 조심스러운 것이 사실이었다.
코로나가 앞당긴 '메타버스' 시대에서 한발 나아가 우리는 메타버스 플랫폼에서 물건을 사는 '메타커머스' 시대로 나아가고 있다. 이미지 생성 모델은 사람들이 온라인상에서 직접 옷을 입어보고 커스터마이즈 할 수 있게 해 줌으로써 진정한 의미의 '메타커머스' 시대의 출현을 앞당기고 있다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.