오토 큐레이트(Auto-Curate)로 모델 성능 개선하기: LOCO 사용 실험 사례

학습용 데이터셋을 큐레이션해 강건한 모델 구축하기
샘플 데이터가 고르게 분포된 균형 잡힌 데이터셋을 큐레이션(Curation; 양질의 데이터를 취합, 선별, 분류, 구조화하는 것)하는 것은 상당히 어렵습니다. 특히 메타데이터가 드물거나 제한적일 경우 더 그렇죠. 슈퍼브에이아이의 큐레이트(Curate)는 이러한 불편함을 해소하고 사용자들이 희소한 엣지 케이스가 더 많이 포함된 학습용 데이터셋이나 검증용 데이터셋을 큐레이션할 수 있도록 돕는 제품입니다. 균형 잡힌 데이터셋이 있다면 현실의 다양한 시나리오에서도 좋은 성능을 내는 강건한 모델을 만들 수 있으니까요.
그 중 오토 큐레이트(Auto-Curate) 기능은 “임베딩”이라는 기술을 통해 사용자들이 이런 데이터 큐레이션 프로세스를 자동화할 수 있도록 돕는 기능입니다. AI는 임베딩을 통해 배경, 색상, 구도, 화면 구성 등 이미지의 시각적 유사성을 이해하고 비교할 수 있습니다. 큐레이트는 임베딩을 활용한 다양한 AI 기반 데이터 큐레이션 기능을 제공하는데, 예를 들면 라벨링이 되지 않은 이미지들을 분석해 데이터 중복이 거의 없는 균등한 분포도의 데이터셋을 구성하거나, 희귀하거나 엣지 케이스일 확률이 높은 이미지들만 큐레이션하거나, 반대로 데이터셋의 대표적인 이미지들이나 빈번히 등장하는 이미지들만 큐레이션할 수도 있습니다.
실험 세팅
LOCO 데이터셋은 컴퓨터 비전의 여러 문제 중 물류와 관련된 문제를 해결하고자 하는 연구자나 개발자에게 아주 유용한 데이터셋입니다. 최초의 장면 이해(Scene Understanding) 데이터셋으로, 물류와 관련된 객체의 탐지와 같이 오직 물류 분야의 문제를 해결하기 위한 데이터만을 담고 있습니다. 저렴한 카메라를 사용해 5개의 서로 다른 물류 환경에서 촬영한 37,988장의 이미지가 포함되어 있으며, 그 중 5,593장은 사람이 수기로 작업한 152,421개의 어노테이션을 담고 있습니다. 어노테이션 클래스는 지게차, 팔레트 트럭, 팔레트, 소형 적재 캐리어, 스틸리지 등 물류 분야와 관련된 다양한 클래스가 포함되어 있습니다. 물류와 관련된 객체나 세팅을 폭넓게 포함하고 있는 만큼, LOCO 데이터셋은 물류 분야의 컴퓨터 비전 알고리즘을 개선하고자 노력하는 사람들에게는 자원의 보고와도 같습니다.
저희는 이번 실험을 위해 먼저 저희의 오토 큐레이트 기능을 활용해 모델이 예측하기 힘든 엣지 케이스나 희소한 케이스들을 더 많이 포함한 검증용 데이터셋을 자동으로 큐레이션했습니다. 이렇게 큐레이션 된 검증용 셋(이하 “큐레이션 검증셋”)에는 2,277장의 이미지가 포함된 공식 검증용 데이터셋에서 추출한 1,000장의 이미지가 담겨 있습니다.
그리고 비교를 위해 큐레이션 된 학습용 데이터셋(이하 “curated-train-set”)과 랜덤으로 샘플링 된 학습용 데이터셋(이하 “random-train-set”)을 생성했습니다. 두 데이터셋은 2,820장의 이미지가 포함된 공식 학습용 데이터셋에서 각각 1,000장씩 추출해 구성했습니다.
그리고 각각의 학습셋을 활용해 사전에 훈련된 모델을 세부 조율하고 성능이 어떻게 개선되는지 큐레이션 검증셋을 통해 평가해 보았습니다.
데이터 큐레이션이 데이터셋 구성에 미치는 영향
아래 표는 random-train-set과 curated-train-set의 구성이 어떻게 다른지를 보여주고 있습니다. 두 셋 모두 1,000장의 이미지로 구성된 점은 동일하지만, 각 클래스가 데이터셋 내에서 차지하는 비중이 눈에 띄게 다릅니다. 예상한 대로 랜덤으로 샘플링 된 학습셋의 클래스 분포도는 원본인 LOCO 데이터셋 전체의 클래스 분포도와 유사한 양상을 보였습니다.
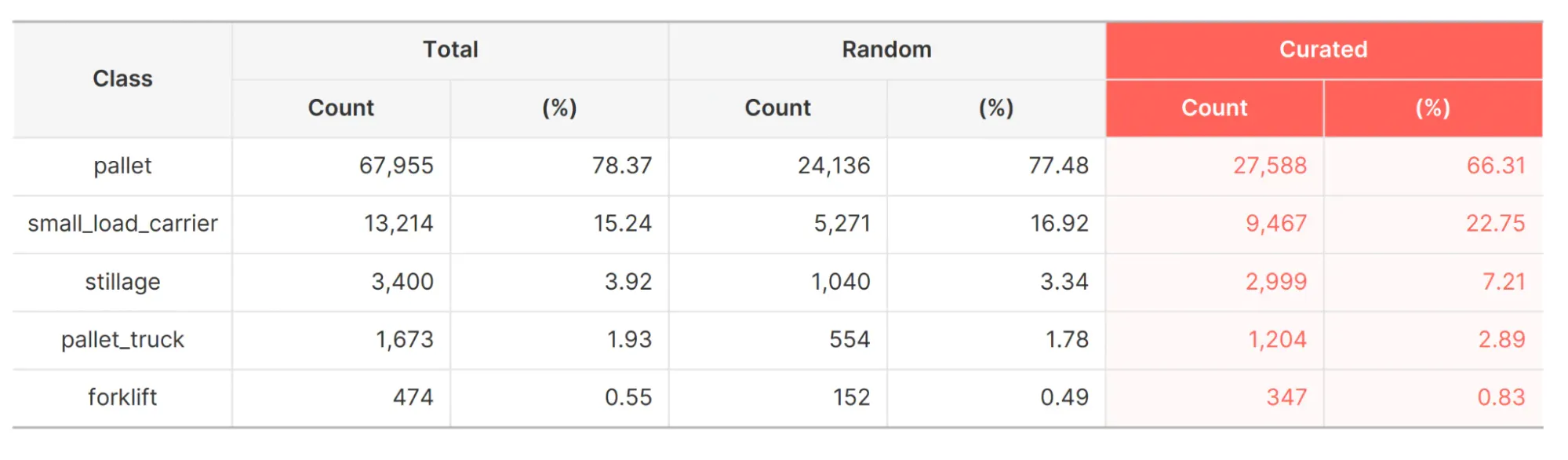
하지만 동시에 curated-train-set의 클래스 분포도는 그렇지 않다는 점도 확인할 수 있었는데요. Curated-train-set은 각 클래스를 대표하는 이미지가 적은 클래스에서 더 많은 수의 이미지를 샘플링하고 반대로 클래스를 대표하는 이미지가 많은 클래스에서는 더 적은 수의 이미지를 샘플링하도록 설계되어 전체적으로 더 균형 잡힌 데이터셋을 구성했습니다. 다시 말해, 저희 오토 큐레이트 기능을 통해 데이터셋에서 흔히 관측되는 문제점인 클래스 불균형을 해소할 수 있었으며, 결과적으로 모델 성능을 더 개선할 수 있었습니다.
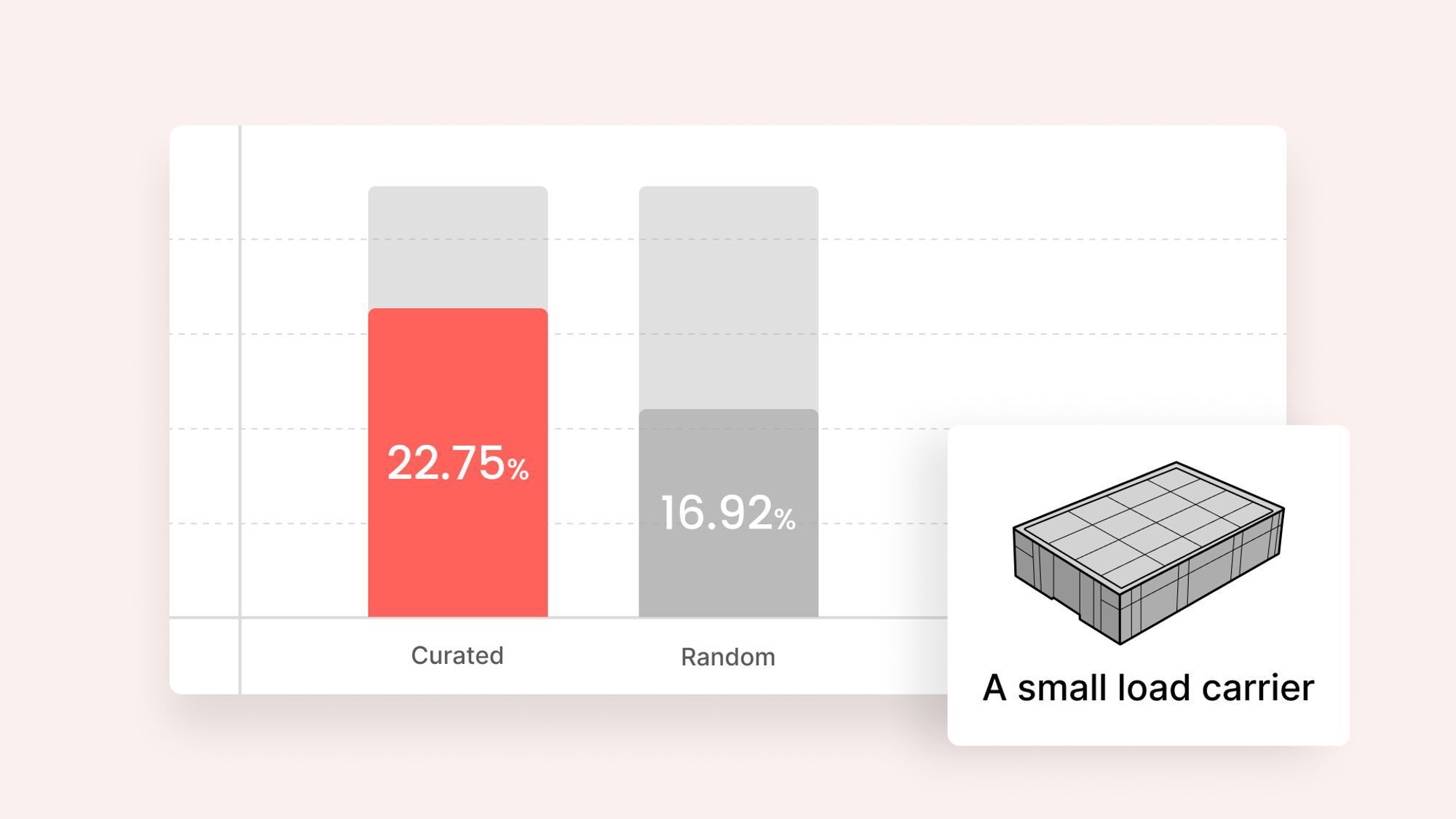
다음으로 저희 오토 큐레이트가 데이터셋을 구성할 때 동일한 객체 클래스에 속하는 여러 이미지들의 다양성이나 분포도를 고려하는지를 평가해 보았는데요. 실험을 위해 “소형 적재 캐리어” 클래스를 선택해 보겠습니다.

소형 적재 캐리어는 물류창고나 제조시설 내에서 작은 물체를 옮길 때 주로 사용하는 물류 장비 중 하나인데요. 일반적으로 위 이미지와 같은 모양을 하고 있습니다.
저희 오토 큐레이트는 클래스 간 균형 뿐 아니라 동일한 클래스 내의 서로 다른 이미지나 객체들이 어떻게 보이는지도 고려합니다. “클래스 내 다양성(intra-class variability)”이라고 하는 것인데, “사람” 클래스의 이미지들이 얼마나 천차만별일지 생각해 보면 쉽게 이해할 수 있습니다. 사람 이미지마다 포즈, 의상, 키, 성별, 배경, 조명, 카메라 앵글 등 많은 요소가 다를 수 있을 테니까요. 그래서 학습용, 또는 검증용 데이터셋을 구성할 때 각 클래스 내에서도 다양한 이미지를 추출하는 것이 매우 중요합니다.

저희는 각 이미지의 임베딩 값을 활용해 어떤 이미지가 흔한 케이스, 혹은 드문 케이스인지 판별하고 있습니다. 슈퍼브에이아이의 시스템은 유사성을 기반으로 임베딩을 클러스터링하며, 각 클러스터는 서로 다른 크기를 가집니다. 많은 이미지가 포함된 큰 클러스터가 있다면 데이터셋 내에 어떤 특정한 타입의 이미지 혹은 객체가 다수 존재하며 해당 이미지 혹은 객체가 특정 클래스의 대표적인 예시라는 것을 의미합니다. 반대로, 소수의 이미지, 혹은 1장의 이미지로 구성된 작은 클러스터가 있다는 것은 해당 이미지나 객체가 데이터셋 내에서 상당히 희소하고 엣지 케이스일 확률이 높다는 것을 의미합니다.
앞서 큰 클러스터에 속한 네 장의 이미지와 작은 클러스터에 속한 네 장의 이미지를 보여드렸는데요. 모두 소형 적재 캐리어의 사진임에도 불구하고 왼 쪽보다 오른 쪽의 사진들이 더 구분하기 어렵다는 것을 쉽게 아실 수 있습니다.
저희 오토 큐레이트 알고리즘은 큐레이션 된 데이터셋에 각 클래스의 희소한 엣지 케이스들을 충분히 담도록 설계되었습니다. 그래야 이 데이터셋으로 훈련한 모델들이 희소한 케이스에도 더 좋은 성능을 낼 수 있으니까요. 다음 섹션에서는 학습용 데이터셋 내 클래스 분포도와 엣지 케이스 비중의 변화가 모델 성능에 어떤 영향을 미치는지 살펴보겠습니다.
데이터 큐레이션이 모델 성능에 미치는 영향
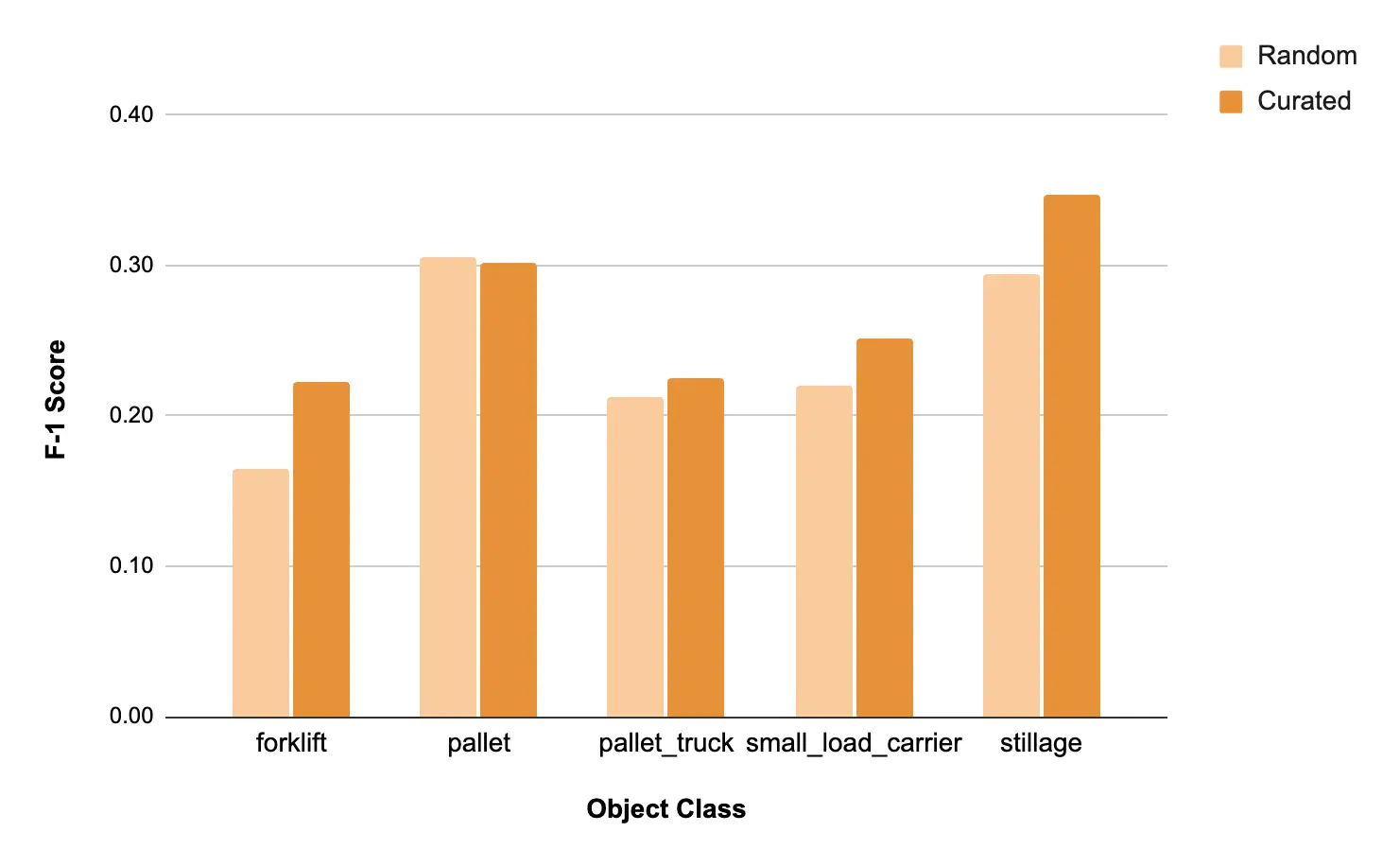
머신러닝 모델의 성능을 평가할 때 가장 일반적으로 사용하는 지표가 정밀도(precision)와 재현율(recall)입니다. 정밀도는 모델이 판단한 모든 양성 예측(positive prediction) 중에서 실제로 양성(positive)이 정답인 경우가 몇 번이나 되는지를 측정한 것입니다. 더 쉽게 표현하자면, 모델이 특정 클래스에 속한다고 판별한 모든 객체 중에서 실제로 그 클래스에 속하는 객체가 몇 개인지를 확인하는 거죠. 한편, 재현율은 전체 데이터셋에 있는 모든 양성 클래스 중에서 모델이 정확하게 양성이라고 판별해 낸 클래스가 몇 개인지를 확인합니다. 다시 말해, 특정 클래스에 속하는 모든 객체 중에서 모델이 그 클래스에 속한다고 판별한 객체가 몇 개나 되는지를 확인하는 것입니다.
F-1 점수는 정밀도와 재현율을 하나의 점수로 합쳐 놓은 지표입니다. 정밀도와 재현율을 조화롭게 반영하며, 0부터 1 사이의 숫자로 표현되고 1이 가장 높은 점수입니다. F-1 점수는 전체적인 모델의 성능을 평가할 때 주로 사용되는데, 특히 데이터셋이 불균형할 때(예: 한 클래스가 다른 클래스에 비해 너무 많음) 참고하기에 좋습니다.
실험 결과는 정말 놀라웠는데요, 저희 오토 큐레이트가 세심하게 선별해준 데이터로 학습용 데이터셋을 구성하고 모델을 훈련한 결과 모든 객체 클래스에서 모델의 F-1 점수가 평균 14.5% 상승했습니다.
이 결과가 특히 더 인상적인 점은 새로 추가한 데이터가 전혀 없음에도 불구하고 성능이 대폭 향상되었다는 것입니다. 유일하게 다른 점이 있었다면 오토 큐레이트가 사용자들이 더 강건하고 균형 잡힌 데이터셋을 구성할 수 있도록 엣지 케이스나 중요도에 비해 이미지가 적은 클래스의 이미지들을 선별해 주었다는 것입니다. 머신러닝의 힘과 세심한 데이터 큐레이션의 중요성을 동시에 보여주는 결과였습니다. 이렇듯 슈퍼브에이아이의 툴을 사용하면 별도의 노력은 최소화하면서도 모델의 성능을 크게 개선할 수 있어 어느 때보다도 쉽게 정확하고 신뢰도 높은 모델을 구축할 수 있습니다.
슈퍼브 큐레이트로 더 강건한 모델 구축하기
오토 큐레이트는 슈퍼브 큐레이트가 제공하는 많은 강력한 툴 중 하나일 뿐입니다. 이 외에도 사용자의 머신러닝 모델의 정확성과 강건성을 개선할 수 있는 다양한 기능들이 제공되니까요. 큐레이트는 다양한 AI 기반 데이터 큐레이션 기능을 활용해 머신러닝 팀들이 효과적으로 학습용 데이터셋을 큐레이션하고 더 고성능의 강건한 모델을 구축할 수 있게 해 줍니다.
큐레이트가 있다면 모델 성능을 개선하기 위해 힘들게 더 많은 데이터를 라벨링할 필요가 없습니다. 효과적으로 모델 성능을 개선할 수 있도록 더 유의미한 데이터를 선별하고 데이터셋을 큐레이션하는 데 집중할 수 있죠. 결과적으로 귀중한 시간과 자원은 아끼면서도 더 좋은 성능의 모델을 만들 수 있게 되는 것입니다.
큐레이트를 통해 어떻게 여러분의 머신러닝 모델을 최적화할 수 있는지 궁금하시다면 저희 세일즈팀에 문의해 주시기를 권장합니다. 여러분의 유즈 케이스에 특화된 방식으로 제품을 시연해 드릴 수 있으니까요. 큐레이트는 사용자 친화적인 인터페이스와 풍성한 기능을 제공하는 만큼, 더 풍성한 기능의 머신러닝 모델을 구현하고자 하시는 분들께 최고의 선택이 되리라 자부합니다.