GPT-4o와 멀티모달 기술의 변천사


얼마 전 OpenAI에서 출시한 GPT-4o가 화제다. 모델 이름에서부터 이미 '모든 것'을 의미하는 'omni'라는 단어를 담고 있는 GPT-4o는 음성, 이미지, 텍스트 가릴 것 없이 모든 형태의 데이터의 인풋과 아웃풋이 자유자재로 가능한 멀티모달(Multimodal) 모델이다.
GPT-4o는 기존의 초거대언어모델(LLM)과 같이 텍스트와 음성으로 사람처럼 매끄럽고 자연스러운 문장을 구사하는 것은 물론이고, 질문에 대해 거의 사람과 같은 약 232밀리 초(0.23초)라는 짧은 반응시간으로 마치 실제 사람과 대화하는 것 같은 느낌마저 준다.

더욱 놀라운 것은 GPT-4o가 감정을 담아 목소리 톤을 바꾸어 가며 농담을 던지기도 한다는 점이다. OpenAI가 공개한 시연 영상 속 GPT-4o는 단순한 이미지 인식을 넘어 마치 사람처럼 주변의 풍경을 정확히 인식하며 시각장애인을 위해 길 안내를 하고 택시를 잡아주기까지 한다.
이처럼 다재다능한 GPT-4o는 인공지능에 회의적이던 사람들마저 매료시키며 인공지능 기술 끝판왕의 면모를 보여주고 있으며, 이를 계기로 OpenAI는 진정한 생성형 AI의 강자로 거듭난듯하다. 어떻게 이것이 가능한 것일까? 그 비법은 바로 멀티모달 기술에 있다. 이번 시간에는 생성형 AI에 눈과 귀를 달아준 멀티모달 기술에 대해 알아보자.
1. 멀티모달 모델은 어떻게 만들어질까?
멀티모달 모델(Multimodal Model)은 텍스트, 이미지, 음성, 비디오 등 다양한 형태의 데이터를 동시에 처리하고 이해할 수 있는 인공지능 모델을 가리킨다. 각기 다른 유형의 데이터를 하나의 통합된 시스템으로 결합함으로써, 더 풍부한 정보와 직관적인 상호작용을 가능하게 하는 것이 특징이다.
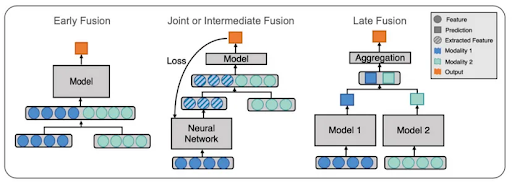
이러한 멀티모달 모델은 Early Fusion과 Late Fusion 그리고 Joint Fusion이라는 세 가지 기법 중 하나를 통해 만들어진다. 우선 Early Fusion은 종류가 다른 두 가지 데이터를 하나의 데이터로 합치는 과정을 거친 후에 모델에 학습(training) 하는 과정을 거치는 기법을 말한다.
다음으로 Late Fusion은 종류가 다른 두 가지 데이터를 각각 다른 모델에 학습시킨 이후 나온 결과를 융합하는 방법이다. 머신러닝에서 여러 모델의 결과를 종합하여 하나의 결괏값을 내는 랜덤 포레스트(Random Forest)와 같은 앙상블모델이 작동하는 방식과 유사하다.
마지막으로 Joint Fusion은 두 개의 모달리티 데이터를 동시에 학습시키지 않고 내가 원하는 모델의 깊이에서 유연하게 모달리티를 병합할 수 있도록 하는 기법이다. 처음에는 텍스트나 이미지 등 대표적인 모달리티로 모델학습을 진행하며, 모델학습의 마지막 레이어(layer)가 등장하기 전에 또 다른 형태의 데이터를 융합하는 방식이다.
2. 멀티모달 모델 기술의 변천사
1) 다양한 형태의 데이터를 통합하다
2000년대 초 컴퓨터 비전(CV)과 자연어 처리(NLP) 기술의 발전으로 텍스트와 이미지와 같은 서로 다른 데이터 간의 통합이 가능해졌다. 초기에는 텍스트와 이미지 데이터를 결합하여 이미지의 내용을 설명하는 텍스트를 자동 생성해 주는 이미지 캡셔닝(Image Captioning)과 같은 작업이 주로 수행되었다.
또한 이 시기에 멀티모달 데이터 통합을 위한 보다 정교한 기법들이 개발되기 시작했다. 특히 이미지와 텍스트 데이터를 결합한 객체 인식(Object Detection), 이미지 설명 생성 등의 기술이 발전하기 시작했다.
2) 딥러닝 모델의 발전과 멀티모달
2010년대 초 딥러닝 기술의 발전은 멀티모달 모델의 성능이 크게 향상되는 계기를 마련해 주었다. 특히 이미지 처리에 탁월한 성능을 보이는 컨볼루션 신경망(CNN)과 텍스트 데이터와 같은 시퀀스 데이터에 특화된 순환 신경망(RNN)의 발전이 큰 기여를 한다.
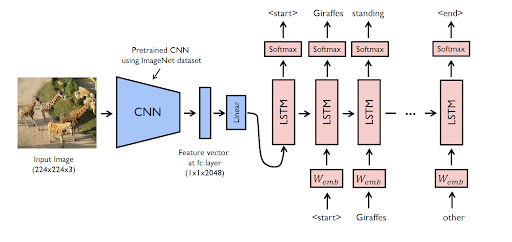
이러한 딥러닝 기술들을 바탕으로 이미지와 텍스트를 결합한 연구가 활발히 진행되었으며, 이는 이미지 캡셔닝(Image Captioning) 기술을 한 단계 발전시켰을 뿐만 아니라 비주얼 질문 응답(VQA) 분야에서 활발히 활용되었다.
3) 초거대언어모델(LLM)이 멀티모달을 혁신하다
2020년대 들어 전이학습(Transfer Learning)에 기반한 초거대언어모델(LLM)의 등장은 멀티모달 모델의 성능을 한층 더 강화하는 계기가 되었다. 2020년 5월 OpenAI에서 출시한 GPT-3는 주로 텍스트 기반이었지만, 다양한 형태의 데이터를 처리하는 멀티모달 모델의 가능성을 보여주는 계기가 되었다. GPT-3에 이어 2021년 1월 5일 출시된 OpenAI의 DALL-E와 CLIP, Google의 ViLBERT, DeepMind의 Perceiver와 같은 모델들이 멀티모달 AI의 새로운 가능성을 제시하기도 했다.

예를 들어 GPT-4o 이전에 가장 널리 알려진 멀티모달 모델중 하나인 DALL-E는 텍스트 설명을 바탕으로 이미지를 생성하는 모델이다. DALL-E는 "초록색 모자를 쓴 고양이"와 같은 텍스트 입력을 받으면 그에 맞는 이미지를 생성한다. DALL-E는 텍스트와 이미지 간의 관계를 학습하여 매우 구체적이고 창의적인 이미지를 만들어낸다.
3. 멀티모달 모델 기술의 최신 트렌드와 전망
최근의 생성형 AI 서비스는 대부분 멀티모달 기능을 기본으로 탑재하고 있다. 예를 들어 OpenAI의 생성형 AI 서비스 ChatGPT는 이미지 입출력이 가능한 형태의 서비스를 기본으로 제공하고 있다. 또한 경쟁사인 Google에서 만든 생성형 AI인 Gemini도 태생부터 멀티모달을 전제로 만들어졌다.
이처럼 기존의 방식과는 다르게 생성형 AI는 더 이상 초거대언어모델(LLM)과 이미지 생성 모델로 나누어지지 않는 방향으로 진화하고 있다. GPT-4o와 같은 매끄러운 음성 인식 기능을 탑재한 모델들이 등장하면서 STT(Speech-To-Text)와 TTS(Text-To-Speech) 역시 따로 개발할 필요성이 점점 줄어들고 있다.
GPT-4o가 시작한 ‘초거대언어모델(LLM) 기반 멀티모달 모델’의 경쟁은 앞으로 멀티모달 모델을 새로운 표준 즉 뉴노멀(New Normal)로 만들고 있다. 이제 가까운 미래에 LLM이나 이미지 생성 모델이라는 말 자체가 역사 속으로 사라질지 모른다. 이처럼 생성형 AI 기술의 발전은 놀라운 속도로 이루어지고 있다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.