최신 딥러닝 기술의 가장 큰 약점과 AI 반도체가 해결하려는 문제

최근 Generative AI의 기세가 꺾이지 않고 지속되고 있습니다. Stable Diffusion 같은 이미지 생성 오픈소스가 공개된 탓도 있고, 초거대 언어모델 (LLM)의 일반적인 서비스 대중화에 힘입은 측면도 있습니다. 이런 AI 열풍을 만들어 낸 배경 기술에는 딥러닝 알고리즘과 그래픽 처리 유닛(GPU)이 있습니다. 이 두 가지가 없었다면 지금과 같은 ChatGPT는 존재할 수 없었다고 해도 과언이 아닙니다.
이번 글에서는 우리를 흥분에 떨게 하는 생성형 인공지능, 그 인공지능을 구성하는 기술이 처한 한계점 및 AI 반도체가 해결하려는 처리속도/에너지 문제점에 대해 정리해 보고자 합니다.
딥러닝 기술이 태생적으로 가지는 가장 큰 약점, 확률론
딥러닝의 대표적인 알고리즘에는 CNN(Convolutional Neural Network), RNN(Recurrent Neural Network) 등이 있습니다. 모두 DNN(Deep Neural Network)로 불립니다.
“Deep” 이라는 단어의 물리적 의미는 추론의 가장 기본이 되는 로직(Perceptron)이 한 두개의 단계(Layer)가 아닌 여러 단계로 깊게 구성되어 있다는 점에 있습니다.
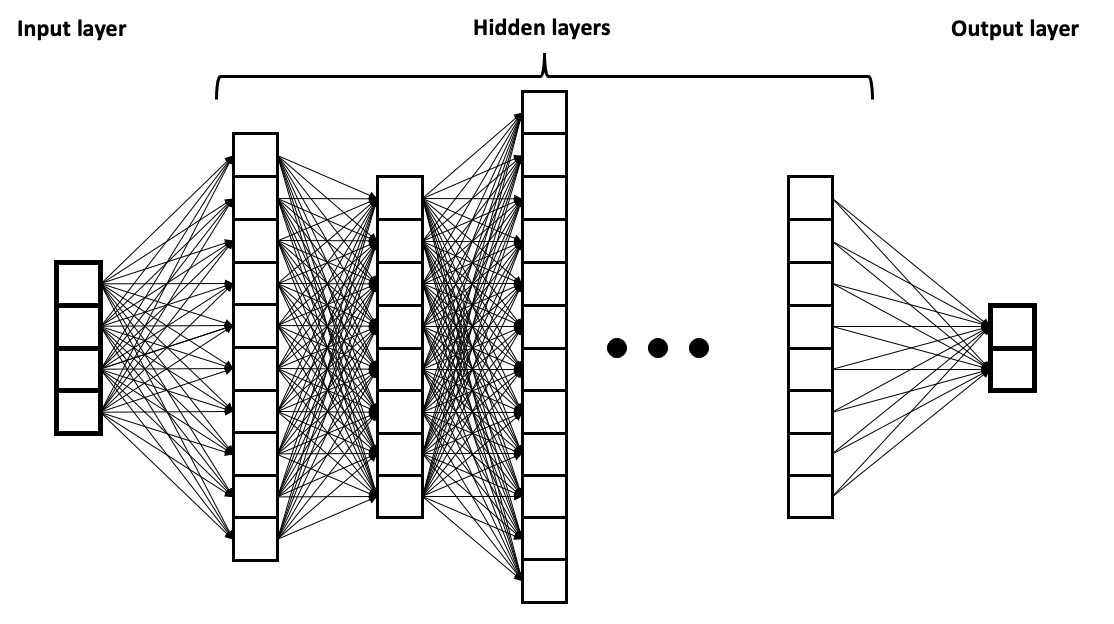
이 각각의 Layer들은 Markov Chain이라는 수학적 모델을 이용해서 Hidden layer를 해석하게 됩니다. 이를 일컬어 Hidden Markov Chain으로 불리웁니다. 입출력이 별도로 존재하지 않아 외부로부터 감춰져 있어 Hidden이라는 단어가 붙었습니다. 이 그림을 이해하는데 있어 중요한 것은 Hidden Layer가 갖는 물리적인 의미, Hidden Layer가 가지는 파라미터의 개수 입니다.
Hidden Layer는 단일 지각의 최소 단위(Perceptron, Neuron 등)로 보시면 됩니다. 하나의 Perceptron은 하나의 기초적인 인지 능력을 보유합니다. 디지털 로직에서의 AND, OR, XOR, NOT과 같은 능력이라고 생각하시면 됩니다. 이런 지각 능력의 최소 단위 개수를 몇개 사용할지에 따라서 Neural network의 구조 복잡도가 결정되고 추론 가능한 분야가 결정 됩니다.
단일 지각에 대해 조금만 더 쉽게 설명을 드리자면, 문자 인식을 하는 경우 문자의 형태에 따라서 다음과 같은 인지적 능력을 필요로 합니다. 이런 개별적이고 매우 작은 인지적 능력을 하나의 Layer에서 학습할 수 있도록 설계하는 것이고, 여러개의 Layer를 배치해서 문자 인식이라고 하는 복합인지 형태의 추론 능력을 구축하는 것입니다. 문자를 인지하는데 필요한 다양한 직각들을 예로 들면 다음과 같습니다.
- 가로 직선 (길이, 위치, 독립 or 교차 or 결합, 개수)
- 세로 직선 (길이, 위치, 독립 or 교차 or 결합, 개수)
- 대각선 (길이, 위치, 독립 or 교차 or 결합, 각도, 개수)
- 곡선 (개방형 or 폐곡선, 곡선 반경, 독립 or 교차 or 결합, 개수)
- 점 (위치, 모양)
내부의 파라미터는 괄호 안에 포함된 다양한 정보들을 의미 합니다. 그런데, 딥러닝 기술은 위와 같은 형태의 구체적인 추론 능력을 직접 인간을 통해서 설계하지 않고, 랜덤에 가까운 형태로 알고리즘에 맡겨 두게 됩니다. 그러므로 좀 더 넉넉하게 Layer 개수를 정하고 Parameter 개수를 정해 두면 생각했던 추론능력을 수행할 수 있게 됩니다. 그 이후, 넉넉하게 설정했던 값들을 조금씩 줄여 나가면서 최적화 과정을 거치게 됩니다.
Layer를 설계하는 과정은 다분히 Heuristic (시행착오)한 과정이며, 사람이 디테일하게 다양한 인지적 능력을 미리 설계해서 갯수를 세팅 한다고 잘 돌아가리라는 보장은 없습니다. 딥러닝의 랜덤 방식이 사람의 생각과 다른 패턴일 수 있기 때문입니다. 바둑에서 처럼 인간이 두지 않는 다른 수를 둔다고 생각하시면 됩니다.
지금까지는 문제점을 인식하기 위한 기본 개념을 설명 드렸고, 이제 본격적으로 Deep Neural Network의 구조적인 문제점을 하나 꺼내 보겠습니다. 하나의 Layer에서 이전 Layer로 부터 계산된 값을 어떤 식으로 연산해서 다음 단으로 넘기는지를 먼저 설명드려 봅니다.
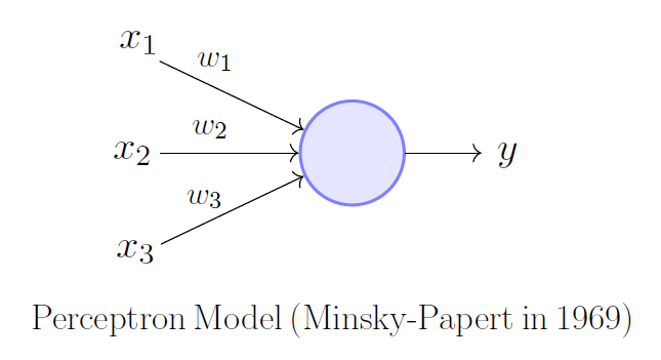
기본적인 Perceptron Model은 신경망 모델을 차용 했습니다. 입력이 사전 확률이고 부가정보를 받아서 새로운 확률로 업데이트를 하게 됩니다. 여기에 차용된 확률론은 18세기에 만들어진 베이즈 확률론을 사용 합니다. 어떤 일에 대한 주장, 주장을 뒷받침 하는 정보, 그 정보를 통해서 변화된 “주장에 대한 믿음" 으로 설명 됩니다.
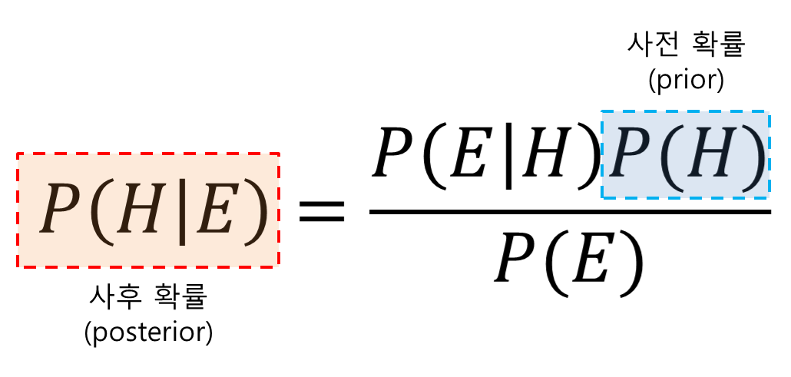
- H 어떤 사건이 발생했다는 주장(Hypothesis)
- E 새로운 정보, 또는 데이터(Evidence)
- P(H) 어떤 사건이 발생 했다는 주장에 대한 신뢰도, 사전 확률
- P(H|E) 새로운 정보를 받은 후 갱신된 신뢰도, 사후확률
베이즈 확률론(Bayesian probability)는 ‘지식 또는 믿음의 정도를 나타내는 양' 의 개념으로 해석하는 확률론 입니다. 지식의 상태는 개인적인 믿음의 정도(degree of belief)로 측정 된다는 개념입니다. 이는 다르게 설명 하자면, 특수한 법칙으로 일반화 시키고 구체적인 사례를 관찰하는 연역적 접근법에서, 구체적인 사례를 학습해서 일반화된 원리를 만들자는 방식 입니다.
그렇기 때문에 수학이라는 완벽한 시스템에서, 예외 수를 두는 확률론적 통계 시스템으로의 시대적 변화를 담고 있다는 점 입니다. 한마디로, 그 지식이 참이건 거짓이건, 믿음의 정도에 따라서 동작 한다는 것을 의미합니다.
그래서, 딥러닝의 본질은 확률론에 근거하는 것이고, 정규분포를 벗어나는 행동에 대해서도 별다른 제약이 걸리거나 거짓이라고 판별하지 않는다는 데 있습니다. 완벽한 룰이 존재하지 않기 때문에 Decision Making System에 곧바로 적용하는 것은 위험 천만한 일이 될 것입니다.
ChatGPT와 같은 서비스는, 정규분포를 벗어나는 예외적인 결과들을 통제 할 필요성을 느끼고 있고, Reinforcement Learning 같은 기술을 추가로 활용하고 있습니다. 언어와 같은 체험적 지식 습득에 대해서는 베이즈 확률론에 따라 학습 하는 것이 바람직 합니다. 많이 쓰는 단어와 문장 표현, ‘ 특정 표현이 의미적으로 옳다는 믿음' 은 인류의 지식구축에 있어 동일한 습성이니까요.
하지만, 데이터나 지식 측면에서는 적합한 방법은 아닙니다. LLM(Large Language Model)에서 언어학습을 위한 pre-training과, 도메인 언어학습을 위한 fine-tuning은 기존의 방식과 잘 맞을 수 있을 것입니다. 하지만 Chatbot 같은 어플리케이션으로 도메인 학습을 진행 한다면, 모든 지식에 대해 명확한 레이블링이 반드시 필합니다. 레이블링된 데이터를 포함하지 않는 생성된 지식에 대해서는 명확한 구분 표기를 해 두어야 할 것입니다.
Transformer 알고리즘은 지금의 구조 그대로 쓰여서는 안됩니다. 설명 가능한 AI 기술이 적용되어야 하고, 자체적으로 전략 로직을 포함해야 합니다. 문장을 생성하기 전에, 문장의 특성이나 사실적 근거들을 뽑아내는 행위가 내부에 포함되어 있어야 보다 안전하고 의도에 맞는 활용이 가능해 집니다.
간략하게 요약해 보자면, 인간이 인공지능에게 기대하는 “진실의 전달" 측면에서, 딥러닝 알고리즘은 확률론적 취약성을 벗어나지 못하다는 점 이고, Few-shot learning기술에 의해서 새로운 지식이 학습 되더라도 여전히 사람들이 생각하고 판단하는 진실의 근거를 마련해 둬야 제대로 학습 가능하다는 점 입니다.
AI 반도체가 해결 하려는 문제점, 에너지 효율
딥러닝 알고리즘에서는, 위에서 언급했던 베이즈 확률론에서의 사전 확률(A priori probability)이 weight라고 하는 변수 파라미터의 형태로 존재 합니다. 딥러닝 알고리즘에서 지속적이고 반복적으로 업데이트 해야 할 파라미터는 다음의 그림에 나오는 Weights 입니다.
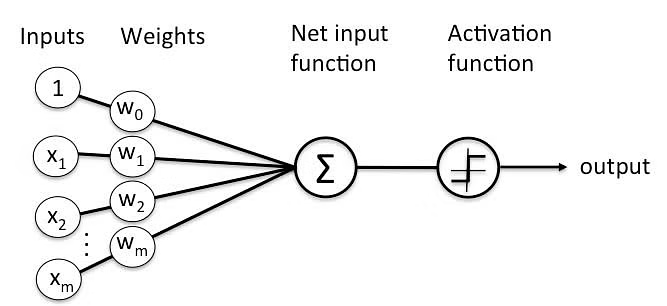
연산 과정은 다소 간단하지만 지속적으로 곱셈 연산을 수행해야 한다는 것을 알 수 있습니다. 인공지능을 학습 하는데 있어 곱셈이 수천만번 나온다면 크게 걱정할 문제는 아니지만, 수천조번 이상 나온다면 이야기는 달라지게 됩니다. 여기서 AI 반도체가 해결 하려는 문제의 정의가 시작 됩니다.
문제의 정의 : 천문학적 곱셈 연산을 하는데 엄청난 시간과 에너지가 소모된다. 줄여야 한다.
GPT-3의 경우 1750억 파라미터(weight들) 를 사용했으며, 학습하는데 3.14 x 10^23 FLOPS (floating point operation, 실수 연산) 연산이 필요했다고 합니다. 15 TFLOP 처리량을 갖는 RTX 8000 그래픽 카드 한장으로 665년이 소요되는 분량 입니다.
그래픽 카드에서 속도를 좌우하는 것은 GPU 입니다.
GPU라고 하는 것은 하나의 프로세서 입니다. 그래픽과 관련된 데이터를 처리하는 전용 칩인 것이죠. 그 내부에서 가장 기본이 되는 것은 메모리 전송 및 연산로직 (arithmetic logic) 입니다. 연산 로직에는 다양한 수학적 연산을 수행하는 회로들이 뭉쳐져 있습니다. 덧셈기, 곱셈기, 시프트, 메모리 패치 같은 동작을 수행합니다. 물론 CPU에도 기본적인 Math Processor Unit이 포함되어 있어 수치연산을 지원 하지만 GPU에는 보다 많은 수치연산 코어들이 포함되어 있어 고속의 수치연산이 가능해 집니다.
딥러닝 연산으로 다시 넘어가 보면, 연산 과정 가운데 곱셈 연산이 꽤 많은 분량을 차지합니다. 2008년 가장 초창기에 나왔던 Tesla C1060의 경우 정수 덧셈 연산과 실수 곱셈연산의 clock speed 차이는 50배 이상이 났었습니다. 필자는 2009년에 C1060을 가지고 CUDA 기반으로 프로그래밍을 했었는데, 곱셈 보다 덧셈 작업이 많았던 터라 큰 도움이 되지 못했었습니다. 게다가 CPU에서 GPU로 데이터 전송 시 발생되는 지연은 실수 곱셈연산보다 훨씬 컸던 기억이 있습니다.
여하튼, 지금까지 GPU 설계 기술은 엄청난 진보가 있었고, 파이프라인 구조 등을 통해서 덧셈이나 곱셈의 지연시간이나 클럭 스피드에 있어 별다른 차이가 나지 않습니다. 논리 회로 설계 측면에서 곱셈을 덧셈과 같은 속도로 나오게 하려면 복잡도의 증가가 매우 큽니다. 속도가 빠른 만큼 회로의 크기가 비대해 지게 됩니다. 그래서, 결론적으로 속도는 빨라졌지만, 전력 소모는 매우 크게 증가하게 되었습니다.
여기서 업계의 딜레마가 시작 됩니다. 속도를 빠르게 하면 전력소모가 늘고, 전력 소모를 줄이면 속도가 줄어드는 것입니다. 트레이드 오프 관계에 있는 문제를 해결하기 위해 수학적 모델들이 등장 합니다.
그 중 하나가 베이즈 확률론의 공식을 변형하는 형태가 됩니다. 조건부 확률론에 따르면 우리는 곱셈과 나눗셈을 몇 차례 진행 해야 합니다.
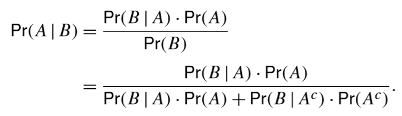
이런 연산을 좀 더 단순화 하는 방법에 1974년, 통신 알고리즘을 분야에서 BCJR algorithm 이라는 제목으로 발표 되었습니다.
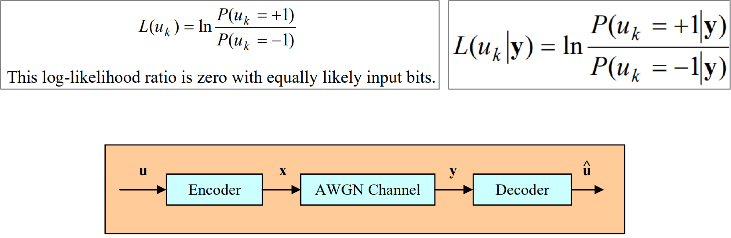
확률식에 log를 취함으로써, 모든 연산이 덧셈과 뺄셈으로 변화하는 것입니다. log scale로 구성된 알고리즘의 연산은 한동안 덧셈 뺄셈만으로 연산될 수 있기 때문에 복잡도 높은 고속의 곱셈 로직을 사용하지 않아도 됩니다. 전력 소모가 줄고, 속도는 그대로인 것입니다.
AI 반도체 업계의 가장 큰 목표는 어떻게 하면 전력 소모를 줄이면서 고속의 알고리즘 연산이 가능할까 입니다. 딜레마 관계를 깨고 기술적 breakthrough를 이루기 위한 아이디어를 50년 지난 기술에서 찾아볼 수 있습니다.
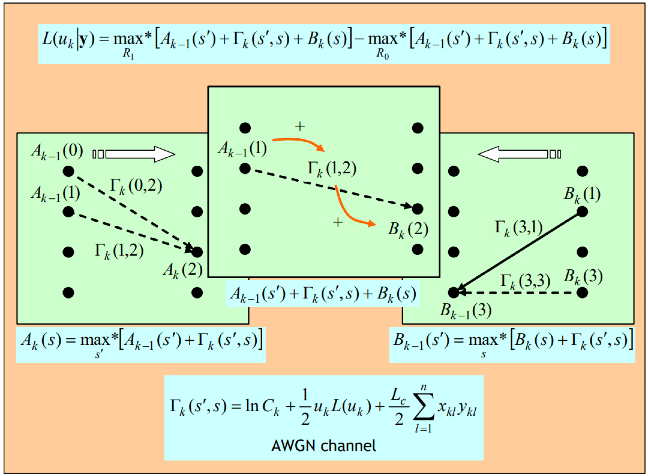
아래의 그림은 max-log-map 방식의 forward/backward belief propagation을 수행하는 연산을 보여주고 있습니다. 필자가 2001년부터 몇년간 연구했던 통신 알고리즘 가운데 하나 입니다. 딥러닝에서 사용되는 확률론적 토대를 그대로 유지하면서 연산 과정을 모두 덧셈과 뺄셈으로 치환하는 방법입니다. 물론 이 알고리즘은 1980 ~ 1990년대에 연구되었고, 1990년대 이동통신 기술 개발에 활용되기 시작했습니다. 예전의 오류정정부호화기술 개발자들 중 일부는 깊이있는 딥러닝 알고리즘의 백그라운드를 그 당시부터 가지고 있었습니다.
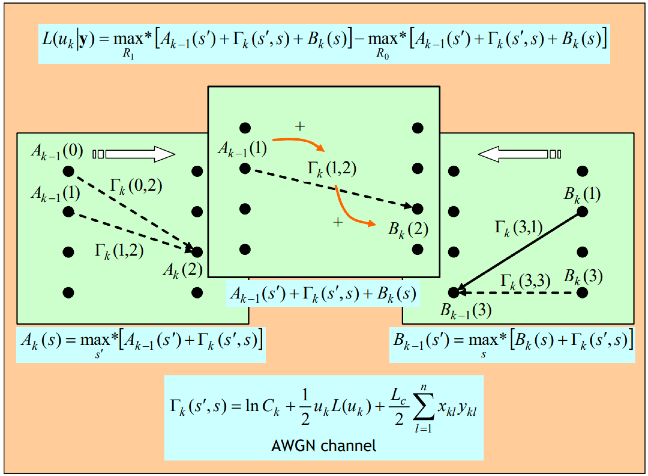
규모의 크기만 다를 뿐, 과거 수십년 전의 알고리즘이 다시 소환되어 활용되고 있는 것은 재미있기도 하고, 때론 경이롭기까지 합니다. 필자가, 과거 통신알고리즘 전문가 였지만 지금은 인공지능 전문가로 맹 활약하고 있는 이유 이기도 합니다.
어디에 묻혀 있을지 모를 중요한 기술들을 다시 발굴해서 재활용 하는 것도 지금 세대가 해야 할 일 중 하나라고 생각 하며, 이번 글을 마무리 해 볼까 합니다. 감사합니다.
| ||
철학적, 미디어적, 사용자 경험적 관점에서 AI를 해석하고 |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.