[데이터 라벨링 사업 노하우 ①] 사업 프로세스 Overview

![[데이터 라벨링 사업 노하우 ①] 사업 프로세스 Overview](/content/images/size/w2000/2023/03/613c1523a47a6b4cffdb9c74_60a35e0071c2468668abccc9_200825_-25eb-258d-25b0-25eb-259d-25bc-25ec-25a0-2584-25ea-25b0-25951_thumb.webp)
슈퍼브에이아이는 머신러닝 데이터 플랫폼 ‘Superb AI Suite’를 개발하고 있는 한편, Suite를 활용해 데이터 라벨링을 하고자 하는 기업들을 꾸준히 컨설팅해왔는데요, 그 중에 성공적으로 데이터 라벨링 사업을 하고 있는 곳을 소개해볼까 합니다. 바로 ‘데이터연구소’입니다. 데이터연구소는 인공지능 학습용 데이터셋 구축을 돕는 라벨링 회사로, 최고 품질의 결과물을 담보하며 국내외 다수 글로벌 AI 회사와의 협력 경험을 보유하고 있습니다. 체계적인 라벨링 시스템을 구축하며 현재까지 400명이 넘는 라벨러들과 약 20명의 매니저 인력을 양성해왔죠.
슈퍼브에이아이와 데이터연구소는 데이터 라벨링 사업에 대한 노하우를 공유하고자 40여개 AI 관련 회사 담당자분들을 모시고 <데이터 라벨링 전문성 강화 프로그램>을 진행하기도 했습니다. 이번 포스팅에서는 프로그램에서도 가장 반응이 좋았고 추가 자료요청이 많았던 ‘데이터 라벨링 사업 A to Z’ 세션을 총 세 편의 포스팅으로 재구성했습니다.
시리즈의 첫 번째 글인 ‘[데이터 라벨링 사업 노하우①] 사업 프로세스, 이렇게 진행됩니다.’에서는 데이터 라벨링과 라벨링 사업에 대한 전반적인 이해를 도울 수 있도록 대략적인 프로세스에 대해 알려드립니다. ‘데이터 라벨링’이 무엇인지 궁금한 분들께도 도움이 될 수 있도록 친절한 설명을 담았습니다.
데이터 라벨링, 대충 알고는 있지만 정확히 알려주세요.
사업 설명에 앞서 데이터 라벨링에 대해 간단히 짚고 넘어가볼게요. 데이터 라벨링이란, 비정형데이터(이미지, 비디오, 오디오, 텍스트 등)를 인공지능이 학습할 수 있는 형태로 가공하는 작업입니다. 인공지능이 공부할 수 있는 연습문제 정답지 세트를 만들어 주는 것이라고 생각하면 쉽습니다. 예를 들어, 이미지 내 오브젝트에 꼭 맞게 박스를 그리거나 누끼를 따듯이 점을 연결한 뒤, Person, Animal, Car 등의 라벨을 달아 기계가 이해할 수 있는 방식으로 바꿔주는 것을 말합니다.

데이터 라벨링 예시
보통 이미지나 비디오에서는 바운딩 박스(Bounding Box), 폴리곤 세그멘테이션(Polygon Segmentation), 폴리 라인(Polyline), 키포인트(Key point) 등의 어노테이션 유형을 사용합니다.

데이터 어노테이션 유형
데이터 라벨링 사업은 이렇게 진행됩니다.
학습용 데이터를 수집·가공·분석·관리하는 작업은 인공지능 개발을 위해서는 필수적인 과정입니다. 하지만 인공지능 개발사에서 직접 하기 어려운 경우에는 외부의 전문 라벨링 기업과 협업을 고려하게 되죠.
데이터 라벨링 사업은 보통 다음의 과정을 따르게 됩니다.
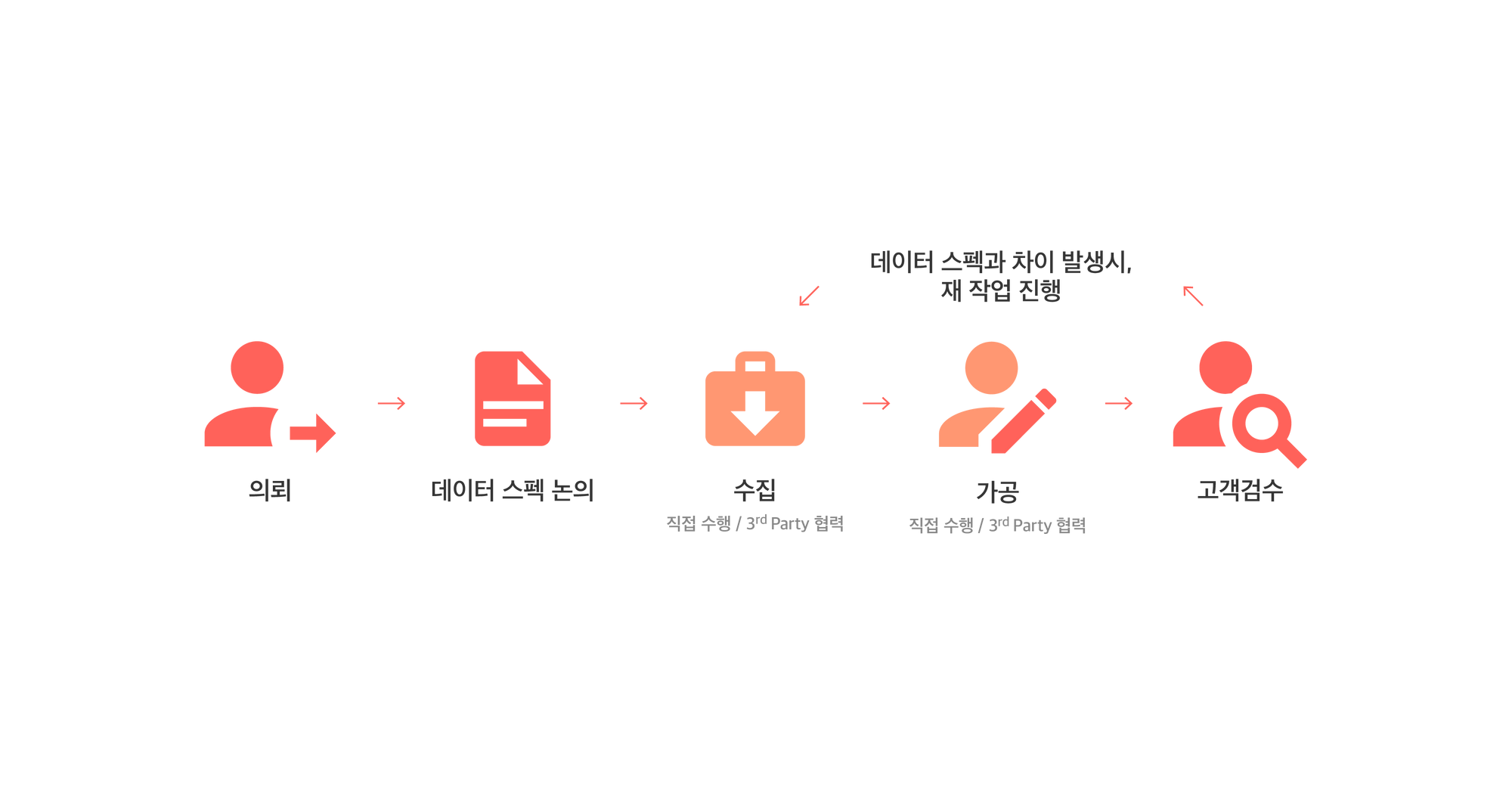
데이터 라벨링 사업 프로세스
그렇다면 각 단계에서는 구체적으로 어떤 지점들을 고민해봐야 할까요? 간략히 요약해보았습니다.
1단계. 의뢰
AI 개발사가 데이터 라벨링 기업을 서칭해서, 라벨링 프로젝트를 의뢰하는 단계
- 고객사가 AI 개발 역량을 보유하고 있는가?
- 고객사가 원본데이터를 보유하고 있는가?
고객사의 AI 개발 역량·원본 데이터 보유 여부는 전체적인 데이터 가공 난이도를 결정하는 데 큰 변수가 됩니다. 고객사가 AI 개발 역량을 보유하고 있다면 데이터 라벨링에 대한 이해도를 기대할 수 있지만, 아닌 경우에는 각 과정에 대한 설명과 교육이 병행되어야 합니다. 또한 고객사가 원본 데이터를 보유하고 있지 않을 경우, 데이터 수집을 별개로 진행해야 하기 때문에 그만큼 종료 예상 일자가 늦춰지게 되죠.
2단계. 데이터 스펙 논의
AI모델의 목적에 맞게 원본데이터와 라벨링 스펙을 논의, 확정하는 단계
- 어떤 사진을 수집할 것인가? 상세 조건은?
데이터 스펙은 크게 원본 데이터의 스펙과 라벨링 스펙으로 나눌 수 있습니다. 각각 어떤 데이터를 수집할 것인지, 수집한 데이터를 어떻게 가공할 것인지에 대한 내용이죠. 예를 들어 ‘사람의 전신 사진’을 수집하는 경우에는 사진의 배경이 실외인지 실내인지, 한 사진에 사람이 몇 명까지 포함될 수 있는지, 사진 해상도와 비율 등이 수집 데이터의 조건에 해당할 것입니다.
라벨링 스펙은 고객사에 따라 천차만별이고, 또 고객사가 수집할 원본 데이터와 만들고자 하는 AI 모델의 목적에 따라서도 달라집니다. 때문에 처음부터 양사가 데이터와 라벨링 스펙에 대해 꼼꼼히 협의를 진행하는 과정이 필수적이죠.
3단계. 데이터 수집
확정된 스펙을 토대로 필요한 원본 데이터를 수집하는 단계
- 데이터 수집 경로는? 구축량은? 마감 기한은?
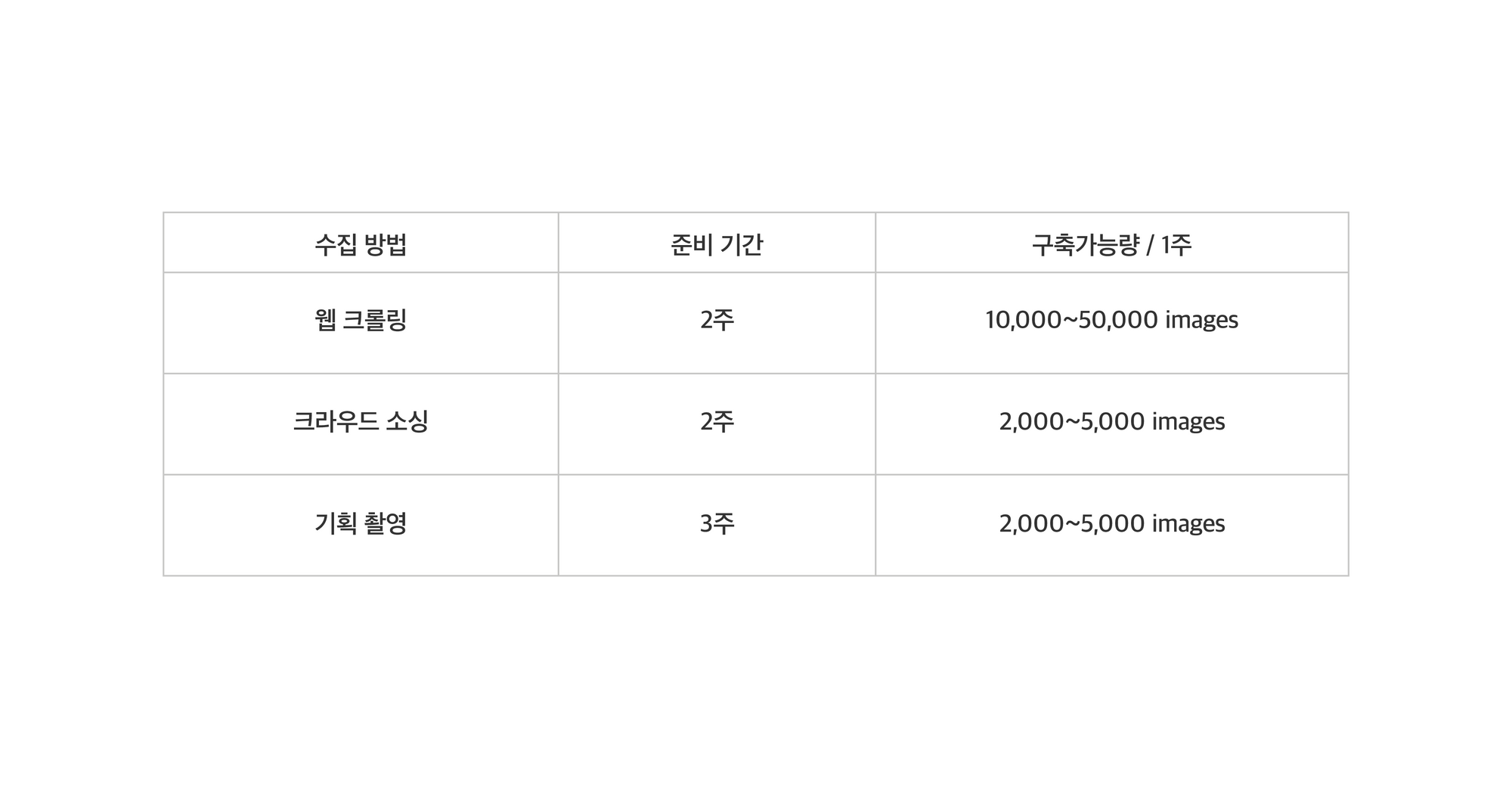
데이터 수집은 보통 웹 크롤링(Web Crawling), 크라우드 소싱(Crowd Sourcing), 기획 촬영(Planned Recording) 중 하나를 택하거나 두개 이상의 방법을 병행하여 진행합니다. 웹 크롤링은 말 그대로 인터넷에 이미 올라와있는 데이터 중 데이터 스펙에 맞는 이미지를 긁어 모으는 작업입니다. 많은 양의 데이터를 가장 싸고 빠르게 모을 수 있지만, 이 경우 데이터 3법과 관련한 초상권, 재산권, 저작권 이슈를 해결할 수 없기 때문에 많이 사용되는 방법은 아닙니다.
크라우드소싱은 공모전의 형태로 필요한 데이터를 모으는 것입니다. 보통 공모전 개최 – 데이터 업로드 – 검수 – 구매 결정 – 대금 지급의 단계로 진행됩니다. 장 당 대금을 지급하고, 업로드된 데이터를 검수하는 시간도 필요하기 때문에 웹 크롤링보다는 많은 예산과 시간을 필요로 합니다. 그러나 초상권, 재산권, 저작권 이슈를 모두 해결할 수 있다는 큰 장점이 있죠.
기획 촬영은 원본 데이터를 크라우드 소싱으로 구하기 어려운 경우 진행됩니다. 보통 전문 사진촬영 업체를 고용하게 되죠. 소요 시간도 제일 길고 구축 가능량도 다른 방법에 비해 적지만, 고객사에서 요구하는 원본 데이터 스펙을 가장 잘 맞출 수 있는 방법입니다.
4~5단계. 데이터 가공 · 고객 검수
수집한 원본데이터를 라벨링 스펙에 맞게 가공, 검수하는 단계
- 라벨링 작업자 관리는 어떻게?
- 데이터를 구축·가공·관리할 수 있는 플랫폼 또는 라벨링 툴(Tool)은 무엇을 사용할 것인가?
- 데이터 추출 형태(Annotation Type)은?
- 라벨링 결과물에 대한 피드백은 어떤 형태로 받을 것인가?
데이터 가공과 검수 단계는 전체 라벨링 프로세스 중 시간을 가장 많이 잡아먹는 단계입니다. 여기서부터는 본격적으로 인력 운영 이슈와 기술적인 문제를 맞닥뜨리게 됩니다.
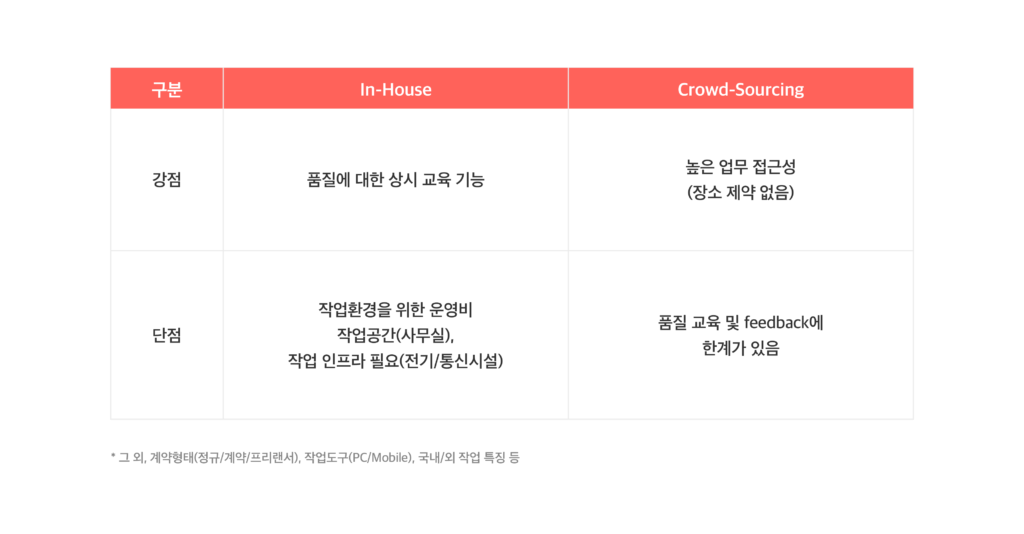
먼저 인력 운영의 두 가지 방법을 살펴볼게요. 인하우스 라벨러를 고용하는 경우에는 수시로 품질에 대한 교육과 검토가 가능하나, 전기·통신시설 같은 작업 인프라가 갖춰진 사무 공간이 필요합니다. 전기세, 월세 등 여기에 들어가는 비용을 무시할 수 없죠. 또한 정규직, 계약직, 프리랜서 등 계약 형태에 대한 고민도 필요하며, 작업 도구(노트북, 모니터 및 기타 사무용품 등)도 구비해놓아야 합니다.
반대로 크라우드 소싱을 택한다면, 장소의 제약이 없기 때문에 업무 접근성이 매우 높고 제반 비용을 줄일 수 있습니다. 하지만 품질 교육이나 피드백이 모두 비대면으로 이뤄지기 때문에, 작업 결과물의 품질 이슈가 발생할 확률이 높아집니다.
다음은 데이터를 관리할 플랫폼 또는 라벨링 도구의 선택 여부입니다.
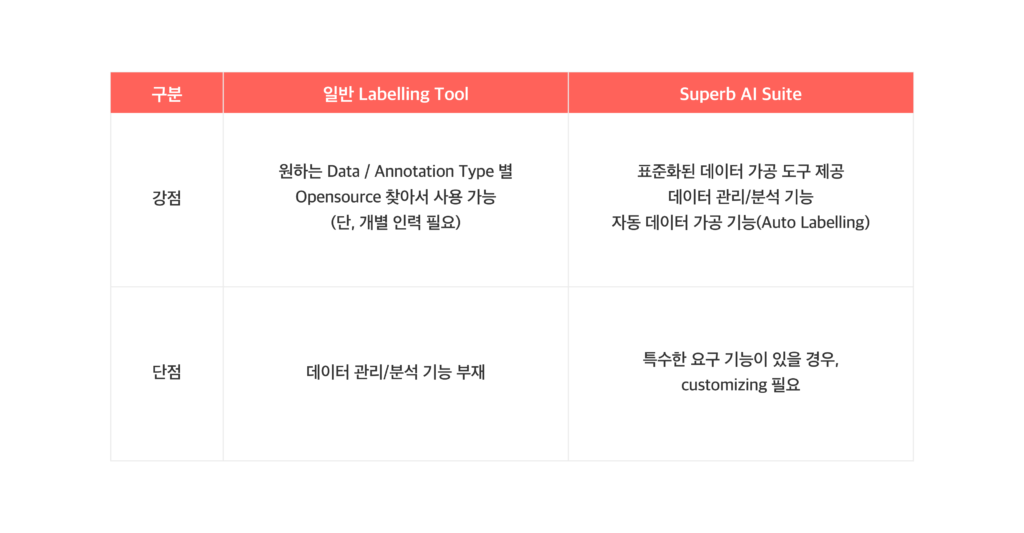
‘데이터 플랫폼’이라는 개념이 등장하기 전, 대부분의 머신러닝 팀은 시중의 오픈소스로 데이터 가공 툴을 직접 만들어 사용하였습니다. 이 경우 원하는 데이터나 어노테이션 유형에 맞게 선택하여 사용할 수 있다는 장점이 있지만, 오픈소스로 가공 툴을 만들어낼 개발 인력이 따로 필요하게 됩니다. 이렇게 만든 가공 툴은 말 그대로 데이터 ‘가공’만 가능하며, 관리나 분석기능은 부재했죠.
또 라벨링 업체가 이렇게 가공만 가능한 도구를 사용할 경우, 고객은 각 단계가 끝난 뒤에서야 작업물을 볼 수 있었습니다. 가령 데이터 수집이 끝난 후 USB로 전달받아 수집된 원본 데이터를 확인하고, 모든 원본 데이터의 가공이 끝난 후에야 라벨링 결과물을 확인할 수 있는 형태였죠. 여기에 라벨링 결과물을 전달받은 뒤에는 JSON포맷으로 바꾸는 과정이 추가로 필요합니다. 또 피드백을 주고 받을 시에는 이미지를 PPT에 넣고 수정이 필요한 부분에 표시를 한 뒤, 수정요청 사항을 적고 다시 파일을 업체에 전달하는 것이 최선이었습니다.
그렇다면, 잘 만들어진 데이터 플랫폼을 활용하는 경우에는 무엇이 다를까요?
먼저 데이터 가공뿐 아니라 구축부터 관리, 분석까지 모두 가능해집니다. 수집단계에서는 원본 데이터를 플랫폼에 업로드하여 관리할 수 있고, 고객도 플랫폼에서 원하는 데이터가 잘 수집되고 있는지 확인할 수 있게 되죠. 또 가공 작업은 얼마나 진행되었는지, 라벨링 작업자들이 놓치고 있는 스펙은 없는지 실시간으로 검토할 수 있습니다. 플랫폼 내 소통 기능이 있는 경우, PPT와 같은 툴을 사용할 필요 없이 수정 요청을 보내는 것이 가능해지겠죠.
Superb AI Suite를 활용하면 달라지는 점
Superb AI Suite는 머신러닝 데이터를 다루는 모든 이해관계자를 위한 데이터 플랫폼입니다. 데이터셋 구축, 작업자 관리, 통계 분석, AI 모델과의 연동, 그리고 슈퍼브 오토라벨링™까지 AI 개발에 필요한 모든 기능이 통합되어 있습니다.
데이터 라벨링 프로젝트 매니징이 궁금하다면, 데이터 라벨링 사업 관리 노하우 e-Book을 다운로드 받아보세요!

마치며
여기까지, 데이터 라벨링 사업에 대해 대략적으로 훑어보았습니다. 어떠셨나요? 데이터 라벨링 사업을 이해하는 데 도움이 되었나요?
다음 포스팅에서는 라벨링 인력 운영 영역과 프로젝트 매니지먼트 영역으로 나누어 좀 더 구체적으로 살펴보려 합니다. 라벨러 계약 단계에서 테스트 샘플링은 어떻게 진행해야 하는지, 검수자(Validator)의 역량을 어떻게 유지하고 높일 수 있는지 등, 슈퍼브에이아이가 데이터연구소와 직접 라벨링 사업을 운영하며 체득한 노하우를 공유할 예정이니 많은 관심 부탁드립니다.
[데이터 라벨링 사업 노하우] 다음 시리즈 보기 >
[데이터 라벨링 사업 노하우 ②] 똑똑한 인력 운영 비법
[데이터 라벨링 사업 노하우 ③] 라벨링 프로젝트 착수 준비