Suite를 활용한 머신러닝 워크플로우 실전 체험기


*이 포스팅은 슈퍼브에이아이의 인턴 홍찬의님이 작성한 글의 번역본입니다.
*이 프로젝트에서 사용된 모든 코드는 다음 Github repository에서 볼 수 있습니다.
시작하며
2020년은 코로나 바이러스로 뒤덮인 한 해였습니다. 특히 ‘외출 시 마스크 필수착용’이 새로운 사회적 규범이 되면서, 일상이 완전히 바뀌어버렸습니다. 하지만 우리는 습관의 동물인 터라 문 밖을 나설 때 마스크를 써야 한다는 걸 종종 깜빡하곤 합니다.
슈퍼브에이아이 서울 오피스도 예외는 아니었는데요, 저는 사람들이 마스크 착용을 깜빡하는 문제를 간단한 머신러닝 시스템으로 해결할 수 있겠다 싶었습니다.
한편, 이와는 별개로 머신러닝 프로젝트 워크플로우에서 Superb AI Suite의 유용성을 내부적으로 시험해보고 싶었습니다. 인턴십을 하면서 머신러닝 프로제트가 배포 단계까지 이르는데 직면하는 장애물과 어려움들을 직접 경험했기 때문입니다. 특히 가장 많이 부딪혔던 어려움 중 하나는 데이터 어노테이션 프로세스를 워크플로우에 지속적으로 동기화시키는 것이었는데, 이는 컨셉 드리프트(Concept Drift)라는 보편적인 문제를 해결하는데 필수적이었습니다.
컨셉 드리프트는 배포된 뒤에 입력값으로 받는 데이터랑 학습할때 사용한 데이터가 유사하다고 가정할때 생기는 문제입니다. 이 문제의 요점은 배포된 모델이 예측할 데이터가 학습에 사용되었던 데이터와 동일한 분포를 보이는 경우가 많지 않다는 것입니다. 어떤 경우에는 아예 다르기도 합니다. 때문에 모델이 시간이 지남에 따라 성능이 저하되지 않도록, 실시간 데이터의 서브셋을 지속적으로 라벨링하고 학습 사이클에 다시 투입해야 합니다.
프로젝트의 큰 그림
저는 오피스 입구 전면을 촬영하는 Arlo CCTV 2대를 머신러닝 모델과 연결하여, 오피스를 나가는 사람들의 마스크 착용 여부를 탐지하는 시스템을 설계해보기로 했습니다. 시스템의 큰 골자는 다음과 같습니다.
- 얼굴 인식 모델(Face Recognition Model) : CCTV 화면 프레임에서 모든 얼굴을 먼저 식별 (바운딩 박스)
- 마스크 탐지 모델(Mask Detection Model) : 얼굴을 식별한 다음, 해당 얼굴에서 (a) protected(마스크 착용), (b) unprotected(마스크 미착용) 여부를 분류
그리고 화면 프레임에 있는 사람 중 ‘protected’로 분류되는 경우가 75% 미만인 순간, 모델이 자동으로 “오피스에서 나갈 때 마스크 착용을 잊지 마세요!” 라는 음성 알림을 내보내게 됩니다.
세부 구현 전략
이제 본론으로 넘어가봅시다. 언뜻 보면 실행에 옮기기 쉬워보이네요.
먼저 얼굴 인식 모델은 이미 사용할 수 있는(pre-trained 된) 멋진 모델들이 많이 있으며, 그런 모델들에서 얼굴 인식 부분을 골라서 쓸 수 있었습니다. 그 중 MTCNN(multi-task convolutional neural network) 모델이 인식 관련 파트는 잘 처리하는 것 같아, 최종적으로 timesler의 facenet-pytorch 프로젝트를 참고해 보기로 결정했습니다. 이 프로젝트의 저장소에는 pre-trained된 MTCNN 모델(별도의 ONet, PNet, RNet 모델)이 함께 제공되어 제 프로젝트에 맞게 조정할 수도 있었습니다.
두번째로, 마스크 탐지 모델은 구현하기 훨씬 쉬워야 합니다. 인터넷에 공유된 여러 안면 마스크 데이터들 중 하나를 마스크 탐지 이진 분류모델을 위한 학습데이터로 사용했습니다. 어렵지 않은 작업이므로, 각각 풀링 레이어를 갖고 있는 두 개의 컨볼루션 레이어와 단일 값을 출력하는 fully connected layer로 연결된 매우 간단한 CNN을 사용하려고 합니다. 저는 마스크 탐지 모델을 학습시키기 위해 Kaggle의 데이터셋을 사용했습니다.
이미 MTCNN 모델을 갖고 있고 Pre-trained된 모델로 시작할 수 있기 때문에, 이 모든 과정을 데이터 라벨링을 하지 않고 빠르게 진행하기 위해 마스크 탐지 모델의 각 클래스를 다음과 같이 학습시킬 수 있었습니다.
- ‘protected’ class : dataset for mask detection으로 학습
- ‘unprotected’ class : 위와 같은 dataset for mask detection으로 학습

모델 학습
- Timesler의 facenet-pytorch 프로젝트에서 미리 학습된 MTCNN 얼굴 인식 모델을 사용하여 얼굴 영역을 추출한다.
- 이전 단계에서 추출한 얼굴 영역을 사용하여 마스크 탐지 분류 모델을 학습시킨다.

구현 코드
이 프로젝트에서 저는 Python 3.7.9를 사용했습니다. 작업 환경에 다음 라이브러리가 설치되어 있는지 확인해보세요.
– torch
– cv2
– numpy
– PIL
프로젝트 & 데이터 셋업
먼저 아래와 같은 구조의 ‘mask_dataset’이라는 빈 폴더를 만들었습니다.
mask_dataset
L train
L protected
L unprotected
L test
L protected
L unprotected
우리는 이 폴더 안에 학습용 데이터를 두기로 했습니다. 이후 캐글에서 데이터셋을 다운받아, ‘with_mask’와 ‘without_mask’ 폴더 내의 이미지를 학습용 및 테스트용 예제로 나눈 후, 각 폴더로 옮겼습니다.
mask_dataset
L train
L protected
L 1.jpeg
L 2.jpeg
L ...
L unprotected
L 1.jpeg
L ...
L test
L ...
훈련용 데이터로 클래스 당 500개의 이미지를 사용하기로 하고(클래스 2개 * 500개 이미지 = 총 1,000개의 훈련용 이미지), 나머지는 테스트 데이터로 분류했습니다.
마스크 탐지 분류기 학습시키기
자, 이제 출력 .pt 모델 파일을 저장할 ‘models’ 폴더를 만들어봅시다.
mkdir models
다음으로는 훈련용 데이터셋에서 training script를 실행합니다.
python train_mask_detector.py \
--train_examples_path=mask_dataset/train \
--train_dataset_size_per_class=500 \
--batch_size_per_class=4 \
--num_epochs=50 \
--detector_model_output_path=models/detector.pt
학습이 완료되면, .pt 모델 파일이 ‘models’ 폴더에 있어야 합니다.
Sanity Check
이제 테스트 데이터셋으로 MTCNN 얼굴인식기와 마스크 탐지 CNN 모델을 테스트해볼 겁니다.
python test_detector.py \
--detector_model_path=models/detector.pt \
--test_examples_path=mask_dataset/test
이런 메세지가 떴는데요,
All done!
num_true_positive: 148
num_false_positive: 2
num_true_negative: 44
num_false_negative: 6
num_correct: 192
num_incorrect: 8
Accuracy: 0.96
정확도 96%가 나왔네요! 다음 단계로 넘어가보겠습니다.
예비 테스트
이제 본격적인 단계입니다! Arlo CCTV 영상에서 MTCNN 얼굴 인식기와 마스크 탐지 CNN 모델을 테스트해보겠습니다. 아래 영상은 제가 오피스에 들어가는 모습입니다.

사실 처음부터 저는 우리의 모델이 제 얼굴의 마스크 착용 여부를 잘 탐지하지 못할 수도 있다고 생각했습니다. 컨셉 드리프트처럼, 모델이 학습한 데이터는 이 CCTV 화면에 나오는 실제 데이터와 매우 다르기 때문입니다. 예를 들어, Arlo CCTV의 각도가 다르기 때문에 MTCNN이 얼굴을 식별하기 어려울 수 있습니다. 그래도 실제로 해보기 전까지는 알 수 없으니 일단은 진행해 보겠습니다.
먼저 어노테이션이 된 화면을 저장할 디렉토리를 만듭니다.
mkdir annotated_footages
다음 스크립트는 CCTV 화면(.mp4 파일)을 개별 프레임(.jpeg 파일)으로 나눈 다음, MTCNN 모델을 통해 프레임을 실행하여 얼굴 주위에 바운딩 박스를 그리는 것으로 시작합니다. 그런 다음 마스크 탐지 모델이 각 얼굴을 ‘protected’ 또는 ‘unprotected’로 분류하고, 해당 라벨이 상자에 어노테이션으로 표시됩니다. 스크립트는 프레임을 쉽게 재생할 수 있는 비디오 형식으로 재구성하여 완성됩니다.
python cctv_mask_detector.py \
--detector_model_path=models/detector.pt \
--footage_path=footages/channy_in.mp4 \
--output_path=annotated_footages/annotated_channy_in.mp4
이제 어노테이션이 달린 동영상은 ‘annotated_footages’ 폴더에 있어야 합니다. 여기까지 진행한 결과물을 보여드리겠습니다.

예상대로, 아직까지는 MTCNN 모델이 얼굴을 식별하는 작업을 어려워하는 걸 볼 수 있습니다. 하지만 바운딩 박스가 너무 많다는 점을 제외하면, 적어도 제 얼굴은 매번 잘 인식되고 있는 것 같기도 합니다. 그럼 다음에는 무엇을 해야 할까요?
모델 Fine-Tuning으로 해결 (MTCNN)
우리의 가장 큰 문제는 MTCNN 얼굴 인식기가 너무 많은 오브젝트에 바운딩박스를 생성한다는 것이었습니다. 마스크 탐지 분류 모델은 이 바운딩 박스에 크게 의존할 것이기 때문에, 이 문제를 빨리 해결해야 했습니다. 저는 MTCNN 모델을 fine-tuning해서, 얼굴 주위에만 바운딩 박스가 생기게끔 하려고 합니다.
자, 그럼 MTCNN 얼굴 인식기를 fine tuning하기 위해서는 실시간 데이터에 바로바로 어노테이션을 달아야 할 것 같습니다. 드디어 Superb AI Suite의 힘을 확인해볼 수 있는 단계입니다.
먼저, Suite에 로그인하고(계정이 없는 경우에는 무료 회원 가입을 할 수 있어요), 새 프로젝트를 만듭니다. 데이터 타입으로는 ‘image’를, 어노테이션 타입으로는 ‘bounding box’를 선택했습니다. 그런 다음, 프로젝트에 ‘protected’와 ‘unprotected’의 두 가지 오브젝트 클래스를 추가했습니다. MTCNN 모델을 fine-tuning 하기 위해서는 바운딩 박스 좌표만 필요하긴 하지만, 나중에 마스크 탐지 모델까지 fine-tuning할 경우를 대비해 박스 classification까지 할 예정입니다.
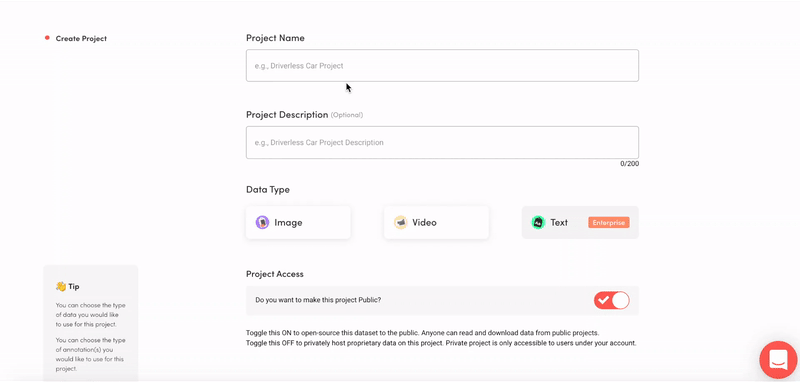
수정: 제가 이 프로젝트를 종료한 이후, Suite에 비디오 프로젝트 기능이 신설되었다고 합니다.
이를 통해 어노테이션 프로세스를 더 간소화할 수 있습니다.
그런 다음, 이 워크플로우를 간소화시키기 위해 이제 프로젝트를 로컬 개발 환경에 연결할 것이고, Suite의 CLI 및 Python SDK를 이 때 사용할 수 있습니다. 먼저 Suite CLI가 아직 설치되지 않았다면, 다음을 실행하세요.
pip install spb-cli
이제 개발 환경을 프로젝트에 인증해야 합니다. ‘My Profile > Advanced’ 메뉴에서 ‘Access Key’를 가져와 다음 명령을 실행하세요.
spb configure
Suite Account Name: [your account name, then press Enter]
Access Key: [the access key, then press Enter]
여기까지 완료되었다면, MTCNN 모델을 fine-tuning 하기 위해 라벨링할 실시간 데이터 화면을 업로드할 것입니다. 이를 위해서는 먼저 화면 영상 파일을 프레임 별 이미지 파일로 변환해야 합니다. 이 파일을 저장할 폴더부터 만들어보도록 하겠습니다.
mkdir footages_frames
이후 다음 스크립트를 실행하여 화면 영상 파일을 프레임 단위로 나눠 이미지 파일로 만듭니다.
python footages_to_frames.py \
--footage_dir=footages \
--output_dir=footages_frames \
--frames_per_extract=10
이 스크립트에서 frames_per_extract을 10으로 설정하면 10개 프레임 당 1개의 이미지 파일을 추출하게 됩니다. 즉, 9개 프레임씩 건너뛴다는 뜻이죠. 이제 라벨링 작업을 라벨러에게 할당할 수 있도록, 프레임 이미지들을 Suite에 업로드해봅시다.
cd footages_frames
spb upload dataset
Project Name: [project name, then press Enter]
Dataset Name: [dataset name, then press Enter]
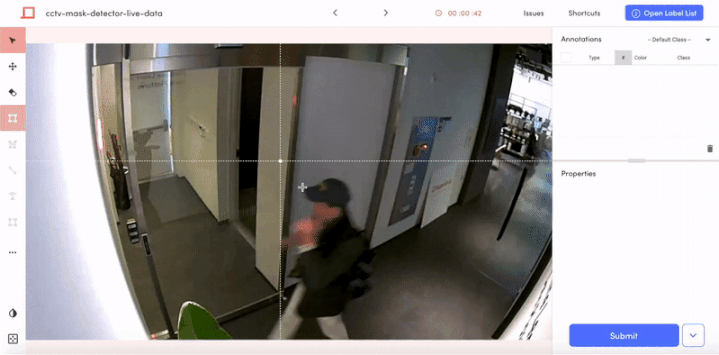
라벨링 단계에서는 라벨러들의 도움을 받았습니다. Suite의 Label List 섹션에서 이미지를 4개 그룹으로 나눴고, 바운딩 박스를 그리고 classification까지 하는 라벨링 작업을 수행하는데 하루도 채 걸리지 않았습니다.
이제 라벨을 export해서 fine-tuning에 사용해봅시다.
spb download
Project Name: [project name, then press Enter]
다운로드한 export 파일의 압축을 풀고, 폴더 이름을 ‘labels’로 변경했습니다.
이제 fine-tuning 프로세스를 위한 준비가 완료되었습니다. 저는 MTCNN 모델을 분리하기 위해 timesler의 facenet-pytorch 프로젝트를 약간 수정해야 했는데요, 이 fine-tuning 스크립트에 대한 커스텀 손실 함수도 설계해보았습니다. 어쨌든, 다음 스크립트를 실행해서 MCNN 얼굴 인식 모델을 fine-tuning 해보겠습니다.
python finetune_mtcnn.py \
--metadata_dir=labels/meta/cctv-mask-detector-live-data \
--labels_dir=labels/labels \
--images_dir=footages_frames \
--batch_size=8 \
--num_epochs=50 \
--mtcnn_model_output_path=models/finetuned_mtcnn.pt
Fine-tuning이 완료됐습니다. 이 custom MTCNN 모델을 사용하여 전체 시스템이 어떻게 작동하는지 살펴보겠습니다.

얼굴 인식 부분은 정말 잘 작동하는 걸 볼 수 있습니다. 하지만 마스크 탐지 기능은 여전히 잘 작동하지 않고 있네요. 라벨링할 때 바운딩 박스의 Class 지정도 미리 해두길 잘했네요. 다음 단계로 넘어가볼게요.
Fine-tuning 계속하기 (마스크 탐지 모델)
이제 이전 단계의 라벨에서 가져온 바운딩 박스 데이터를 사용하여, 마스크 탐지 모델을 fine-tuning 할 것입니다. 이전에 사용한 학습용 스크립트를 다시 사용해보겠습니다. 여기서는 기본 MTCNN을 사용하는 대신, 제가 fine-tuning했던 커스텀 버전을 사용할 것입니다. 물론 이전에 학습해놓은 탐지 모델의 가중치도 사용할 예정입니다. 이 가중치에서부터 fine-tuning이 되기 때문입니다.
python train_mask_detector.py \
--train_examples_path=mask_dataset/train \
--train_dataset_size_per_class=500 \
--batch_size_per_class=4 \
--num_epochs=50 \
--mtcnn_model_path=models/finetuned_mtcnn.pt \
--pretrained_detector_model_path=models/detector.pt \
--detector_model_output_path=models/finetuned_detector.pt
최종 결과
이제, fine-tuning이 완성된 MTCNN과 마스크 탐지 모델을 다시 한 번 테스트해보겠습니다.
python cctv_mask_detector.py \
--mtcnn_model_path=finetuned_mtcnn.pt \
--detector_model_path=models/finetuned_detector.pt \
--footage_path=footages/channy_in.mp4 \
--output_path=annotated_footages/annotated_channy_in.mp4

이제 우리의 모델이 얼굴 인식은 물론 마스크 착용 여부까지 완벽하게 탐지하네요! 성공입니다!
Superb AI Suite를 사용하여
데이터 라벨링을 머신러닝 프로젝트 워크플로우에 연동하기
요약하자면, 저는 CCTV 화면에 잡히는 사람들이 마스크를 착용하였는지 여부를 제대로 탐지하는 모델을 학습시키고, 배포했습니다. Pre-trained된 MTCNN 안면 인식 모델을 사용하고, 공개적으로 사용가능한 안면 마스크 데이터셋을 활용해 마스크 탐지 모델을 학습시킴으로써 학습 과정을 빠르게 시작할 수 있었습니다. 그런 다음, 두 구성 요소를 fine-tuning하기 위해 실시간 데이터를 직접 라벨링해야 했을 때, Suite를 사용하여 이미지를 쉽게 업로드하고, 라벨링 작업을 친구들에게 분배하고, 완성된 라벨을 Export했습니다.
이제 모델을 장기적으로 쉽게 유지 및 관리할 수 있는 방법에 대해 알아보겠습니다. ‘Active Learning(능동 학습)’ 접근법을 취한다면, 우리는 우리가 훈련시킨 모델에서 낮은 confidence를 보이는 영상 프레임을 선택한 후 학습 싸이클에 다시 투입해서하여 두 모델을 더 fine-tuning(또는 완전히 처음부터 다시 학습)하고자 할 것입니다. 가령 MTCNN이 바운딩 박스와 함께 제공하는 확률 수치를 활용하여 이 ‘신뢰도 낮음’이 의미하는 바에 대한 상세한 수치를 설정할 수 있습니다. 마스크 탐지기의 경우, 1.0이 ‘protected’이고 0.0이 ‘unprotected’일 때, CNN 출력값이 약 0.5 정도면 될 것 같네요.
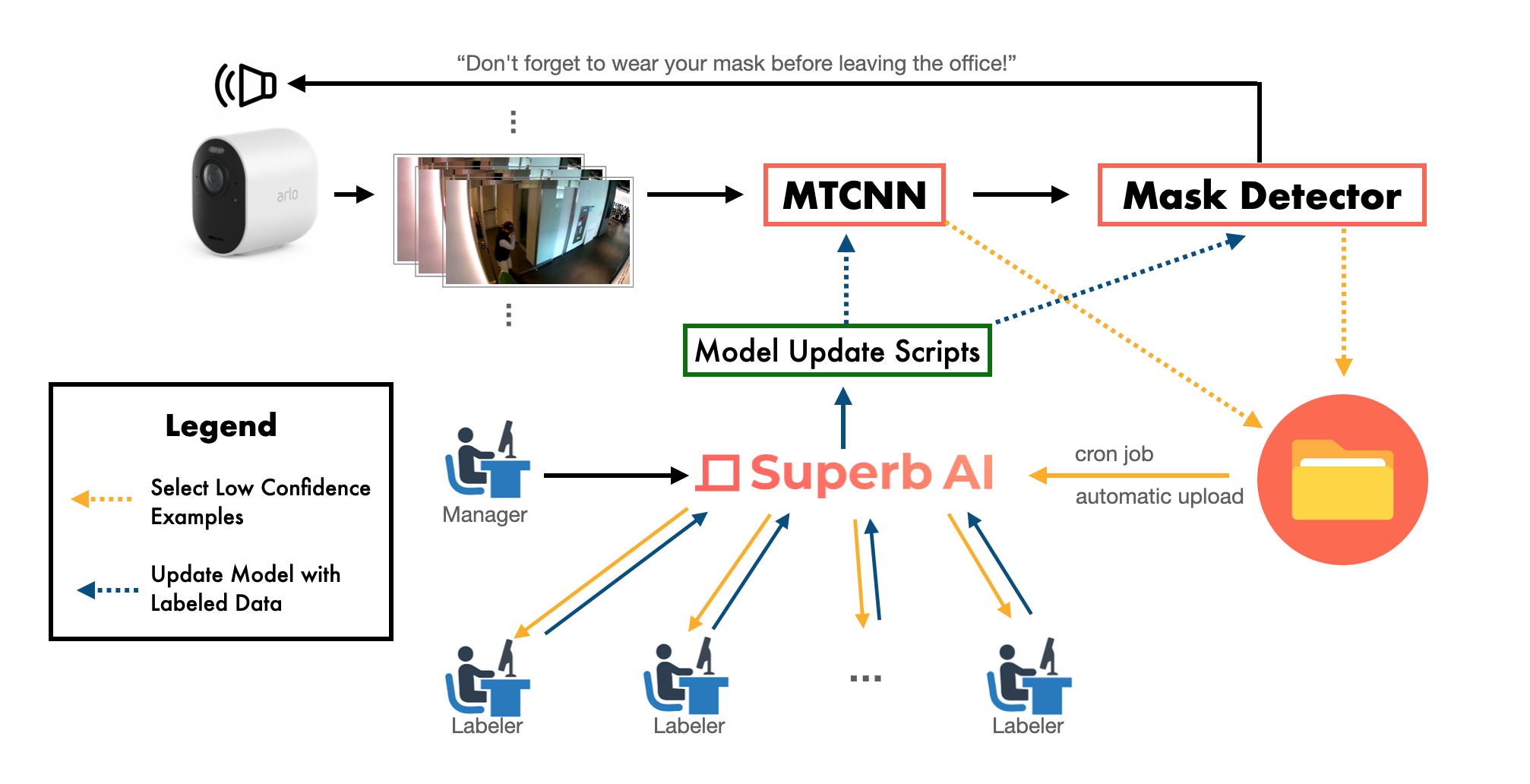
우리는 이러한 프레임을 계속 수집하여 폴더에 저장할 수 있으며, 해당 폴더가 충분히 채워지면 정기적으로 예약된 크론 작업이 가득 찼음을 탐지하고 모델의 fine-tuning과 학습을 트리거하고, 다음에 수집될 ‘신뢰도가 낮은’ 프레임의 배치를 처리하기 위해 폴더를 자동으로 비울 수 있습니다.
그런 다음, Superb AI Suite를 사용하여 어노테이션 작업을 라벨러에게 신속하게 할당하고, 관리자는 프로젝트 분석 내용을 확인하고 품질 검수를 수행할 수 있습니다. 라벨링이 완료되면 학습 주기에 맞춰 어노테이션을 다시 도입하여 배포된 모델을 추가로 fine-tuning/학습시킬 수 있을 것입니다.
최근 머신러닝 기술이 탑재된 제품 및 서비스가 보편화되면서, 데이터 라벨링의 유연성과 ‘통합성(integratibility)’이 머신러닝 프로젝트의 성공에 핵심이 되고 있습니다. Superb AI Suite가 핵심에 더 빨리 도달할 수 있도록 도와줄 것입니다.