인공지능(AI)의 정답은 데이터에 있다


인류가 2000년대 초반부터 2023년 현재까지 생산한 데이터의 양은 90 제타바이트(ZB)에 달한다고 한다. 이는 고대인류가 파피루스와 같은 원시적인 형태의 종이에 기록을 남기기 시작한 이후, 약 5000년이라는 시간동안 쌓아온 데이터양의 약 3000천배가 넘는 수치다. 천문학적이라는 말로는 데이터의 무서운 증가세를 표현하지 못할 지경이다. 이 글을 쓰고있는 지금 이 순간에도 수많은 사람들은 걸으며 GPS에 위치 데이터를 만들어내고 있고, 온라인 쇼핑몰에 리뷰를 남기며 텍스트 데이터를 생성해내고 있다.
숫자나 범주형 데이터 같은 구조화된 정형 데이터(Structured Data)부터 사용자 로그와 같은 반정형 데이터(Semi-structured Data)와 텍스트 데이터와 같은 비정형(Unstructured Data)까지 인간은 이제 모든 형태의 데이터를 생성해내고 수집하고 활용할 수 있는 시대에 살고있다. 클라우드 컴퓨팅 기술과 고성능 GPU와 같은 하드웨어의 발전으로 기존의 머신러닝/딥러닝 모델이 가지던 한계를 극복하고 모든 종류의 데이터를 활용할 수 있게 되었기 때문이다.
2022년말부터 세간의 관심을 주목시키고있는 초거대언어모델(LLM)과 생성형AI의 눈부신 성과의 이면에는 이와같은 데이터의 수집과 저장기술의 발전이 있다. 데이터는 인공지능 모델의 식량이자 석유와도 같기 때문이다. 따라서 데이터의 중요성은 아무리 강조해도 중요하지 않다. 이미지처리나 NLP(자연어처리) 그리고 수요예측과 같은 수많은 분야에서 머신러닝/딥러닝 모델을 개발하고 사용하고 있는 데이터사이언티스트들에게도 예외는 아니다.
AI = Code + Data
사람들은 복잡하고 어려워 보이는 것에 대단한 비밀이 숨어있을 것이라고 믿지만, 문제의 정답은 의외로 가까이에 있는 경우가 많다. 인공지능 개발자 혹은 데이터사이언티스트들은 머신러닝(딥러닝) 모델을 개발할 때 모델의 성능(예측 정확도 및 오차)에 목을 맨다. 밤잠을 설쳐가며 모델을 돌리다가도 단 1%라도 성능이 개선되면 희열을 느낀다. 원하는 만큼 좋은 성능의 모델이 나오지 않으면 개발자들은 갖은 수단과 방법을 동원해서라도 성능을 올리고 싶어 한다. 코드를 들여다보면서 가설을 세우고 모델의 하이퍼파라미터(Hyperparameter)를 수정해 가며 실험을 반복한다.
그래도 모델의 성능이 개선되지 않으면 위험을 무릅쓰고 모델을 처음부터 다시 만들기도 한다. 하지만 투입된 시간과 노력만큼 극적으로 모델의 성능이 향상되는 경우는 생각보다 드물다. 그러나 많은 데이터사이언티스트들이 간과하는 사실은 인공지능 모델이 잘 작동하기 위해서는 데이터(data)가 필요하다는 간단한 사실이다.
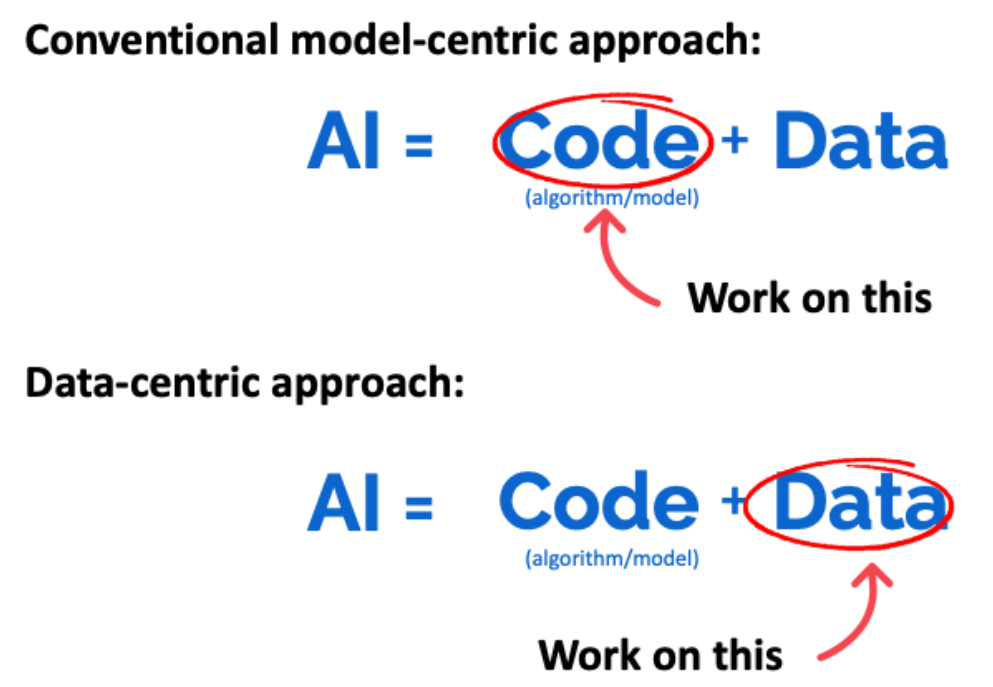
AI = Code + Data
컴퓨터 과학자이자 인공지능 분야의 선구자라고 할 수 있는 앤드류 응(Andrew Ng) 스탠퍼드대 교수에 따르면 인공지능 모델은 '코드'와 '데이터'로 이루어져있다고 한다. 즉 인공지능 모델을 구성하는 '코드'를 자동차에 비유한다면, '데이터'는 자동차를 움직이는 석유와 같은 것이다.
정답은 데이터에 있다
앞에서도 강조했듯이 경험상 정답은 복잡한 모델이 아니라 의외로 데이터에 있는 경우가 많다. 본격적으로 모델을 만들기에 앞서 석유를 정제하여 불순물을 제거하듯이 데이터를 정제하는 작업이 필요하다. 이러한 작업을 거쳐 불순물이 섞이지 않고 깔끔하게 구조화된 데이터를 클린 데이터(clean data)라고 한다.
정해진 규칙에 따라 표준화되고 구조화된 정형 데이터(Structured Data)의 경우 결측치(Missing value)와 이상치(Outlier)는 없는지, 간단하면서도 분석에 꼭 필요한 변수(Feature)가 빠져있는 것은 아닌지, 반대로 필요 없는 변수가 포함되어 있는 것은 아닌지 등 데이터를 꼼꼼히 살피다 보면 많은 경우 성능 좋은 모델을 만들기 위한 실마리를 찾을 수 있다.

텍스트, 이미지와 같은 특별히 구조화되지 않은 비정형 데이터(Unstructured Data)의 경우도 마찬가지다. 실제로 작년에 진행했던 텍스트 분석(Text Analysis) 프로젝트에서 언어모델(Language Model)을 개발할 때에도 데이터는 모델 성능 개선에 지대한 역할을 했다. 대화형 텍스트 데이터를 기반으로 한 분류 모델(Classification Model)을 개발할 때 '네, 예, 어, 음'과 같은 의미 없는 단어 즉 데이터의 불순물을 제거해 준 것만으로도 10%대 이상의 극적인 정확도(Accuracy) 향상을 이루어 낼 수 있었다.
머신러닝 시스템 개발: 모델 중심에서 데이터 중심으로
다시 Andrew NG 교수의 이야기로 넘어가 보자. 그는 2021년 3월, ‘머신러닝 시스템 개발: 모델 중심에서 데이터 중심으로(A Chat with Andrew on MLOps: From Model-centric to Data-centric AI)'라는 세미나에서 그동안 모델 연구에 치우쳐 있던 인공지능 분야에 ‘데이터 중심(Data-centric) AI’라는 새로운 화두를 던졌다. 그의 세미나는 알고리즘 연구에 치우쳐졌던 기존의 인공지능 분야에 데이터의 중요성을 부각한 중요한 계기가 되었다.
앞으로도 클린 하고, 모델에 적합하며, 잘 표준화되고 구조화된 데이터의 중요성은 더욱 부각될 것이다. 이러한 움직임은 대규모의 데이터를 학습한 pre-trained 모델들의 출현과 데이터 파이프라인 구축 및 관리가 중요한 MLOps 플랫폼의 발전이라는 트렌드와 무관하지 않다. 문제의 정답은 의외로 가까이에 있는 경우가 많다. 우리는 항상 그래왔듯 복잡한 것보다는 간단한 것에서, 그리고 먼 곳보다는 가까운 곳에서 정답을 찾을 수 있을지도 모른다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |
