한국의 기업들은 Data-Centric AI에 얼마나 준비되어 있을까요?


*백서 다운로드 링크는 블로그 하단에 있습니다.
Data-Centric View VS Model-Centric View
2021년을 돌이켜 보면, 머신 러닝 개발 씬에서 ‘데이터'에 대한 논의가 많이 이뤄진 한 해였다고 할 수 있을 것 같습니다. Deeplearning.AI의 Andrew Ng이 2021년 3월에 이 주제를 커뮤니티에 던지면서, ‘Data-Centric AI’ ‘데이터 중심의 머신 러닝 개발'과 같은 용어들이 업계 표준 용어로 자리 잡기 시작했습니다.
사실 머신 러닝 분야에서, 데이터는 단 한번도 화두가 아니었던 적은 없었습니다. 하지만 이렇게 깊게 논의된 적도 드물었습니다. Andrew Ng이 본인이 직접 주최한 Youtube 웨비나에서, 기존의 머신 러닝 개발 접근법을 ‘Model-Centric View(모델 중심의 접근법)’이라고 칭하면서, 모델의 성능을 높이기 위한 진짜 접근법은 사실 ‘Data-Centric View(데이터 중심의 접근법)’이라고 명명 하면서 본격적으로 커뮤니티에서는 반성적 목소리와 데이터 품질 개선을 위한 다양한 해법에 대한 논의가 본격화되기 시작한 것입니다.
웨비나에 참석하고 있던 수 많은 엔지니어들의 투표 결과도 Andrew Ng의 이야기에 힘을 실어주는 듯 보였는데요. “머신 러닝 모델 성능을 개선하기 위해서 모델 개선이 더 유리한가, 데이터 개선이 더 유리한가?”라는 질문에서 현장에 있던 참석자 중 80%가 "데이터 개선이 더 유리하다"라고 답변하기도 했습니다.

Tesla, CVPR 2021에서 데이터 중심 접근을 외치다
2021년 CVPR을 압도한 Tesla의 안드레아 캐퍼시의 강연은 온통 데이터에 관한 이야기였습니다. Tesla의 자율 주행 기술의 성능이 학습용 데이터 개선을 통한 것임으로 확인할 수 있었습니다.
Tesla의 데이터 구축 분야 노력은 세 단어로 압축됩니다. 데이터셋의 Large, Clean, Diverse를 추구하는 것입니다. 정확히 말하자면 이 3가지를 한 번에 추구하는 것으로 압축될 수 있겠습니다. Tesla에서는 약 4개월 정도의 기간 동안에 총 1.5페타바이트(PB)에 달할 정도의 데이터를 데이터를 구축한다고 하는데, 이것은 전 세계의 다양한 도로 환경에서 수집된 10초 길이의 동영상 100 만 개와, 60억 개에 이르는 오브젝트가 포함되는 규모입니다.
어떻게 이런 큰 데이터를 고품질로 효율적으로 구축할 수 있느냐에 대한 질문에 Tesla는 쉐도우 모드(Shadow Mode)라는 답변을 내어놓았습니다. 전 세계의 도로를 달리고 있는 Tesla 자동차에서 수집하는 데이터의 총량은 상상을 초월하는데, 이 거대한 양의 데이터셋을 모두 매뉴얼 라벨링으로 구축하는 것은 한계가 뚜렷합니다. 이를 보완하는 것은 Tesla의 쉐도우 모드(Shadow Mode)라 할 수 있습니다. 구체적으로, Tesla의 차량(customer fleet)에는 깊이와 속도를 잘 예측하는 신경망이 쉐도우 모드(Shadow Mode)로, 다시 말해, 그림자처럼 배포되어 있습니다.
이 AI는 고객의 차량 백그라운드에서 조용히 실행되며, 차체를 제어하지는 않으면서 주행 환경에 대한 예측을 항상 하고 있습니다. 이 AI가 오프라인 환경에서 바로 라벨링 자동화 작업을 수행하기 때문에, 사람 작업자는 오토 라벨링의 결과가 적절한지 검수하여 필요시에 약간의 수정을 더 하는 방식으로 대규모의 작업에 효율을 더하고 있습니다. 또한 이 AI는 예측과 실제 도로 상황을 비교해 부정확한 예측을 보이는 희귀한 사례를 발견해 내고 있습니다. 이후, 전체 차량에 해당 사례의 데이터를 집중적으로 요청하여 엣지 케이스를 집중적으로 보완하는 방식입니다. Tesla의 이 발표는, 결국 머신 러닝 서비스의 품질 향상에는 효율적인 데이터 수집에서 모델 개선까지 이르는 파이프라인과 이 과정에서 효율을 극대화하는 워크플로우 구축이 핵심이라는 점을 볼 수 있었습니다.
Tesla도 Data-Centric에 집중, 그렇다면 우리는?
최고의 성능을 자랑하는 Tesla가 Data-Centric의 관점을 철저히 유지하고 있는 한편, 우리 기업들은 어떤 데이터 작업을 하고 있고, 이를 얼마나 효율화하였으며, 어떤 어려움을 겪고 있을까요? 슈퍼브에이아이는 데이터 작업의 효율화, 자동화를 돕고 투명한 협업을 도와주는 머신러닝 데이터 플랫폼 Suite를 서비스 하고 있습니다. 이 과정에서 한국의 다양한 기업들을 만나게 되었고, 머신 러닝 데이터 구축, 관리와 관련한 이야기를 들을 수 있었습니다.
국내 기업들, 데이터 목적/단계에 따라 서로 다른 데이터 이슈를 겪고 있어…
어쩌면 당연한 이야기처럼 들리지만, 슈퍼브에이아이가 여러 기업과 만나는 과정에서 깨달은 확실한 것 중 하나는, 국내 기업들의 경우 머신 러닝 개발의 목적이나 단계에 따라 서로 완전히 다른 데이터 이슈를 가지고 있다는 점이었습니다. 그리고 데이터 이슈에 대해 이야기를 하다 보면, 많은 기업들이 현재 머신 러닝 개발 단계의 어느 지점에 머물러 있는지를 파악할 수 있었습니다.
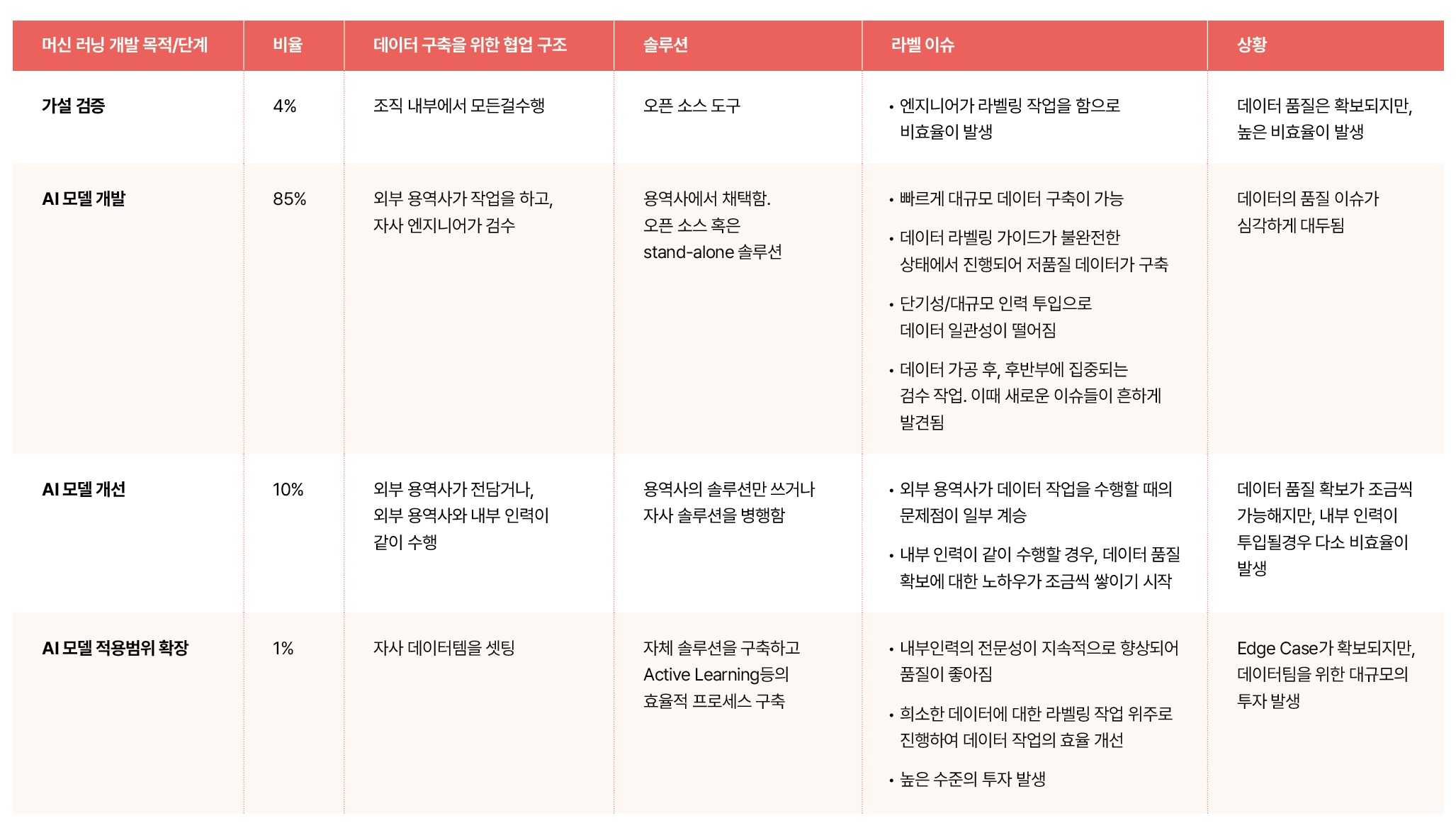
우리 기업은 어디에 머물러 있나요?
우리 기업은 현재 어떤 단계에 머물러 있나요? 그리고 지금 처한 단계에서 어떻게 데이터 중심의 접근을 취할 수 있고, 어떻게 이에 힘입어 다음 단계로의 전진을 더욱 가속화할 수 있을까요?
수 많은 국내 기업들을 만나며, 머신 러닝 데이터 구축 및 관리 작업에서의 자동화와 효율화를 가치를 전달해온 슈퍼브에이아이가 작성한 “한국의 기업들은 Data-Centric에 얼마나 준비되어 있을까?”를 다운로드 받아서 전문을 확인해 보세요. 다른 기업들의 현황도 살펴보고, 우리 기업의 현재도 진단해 볼 수 있습니다.