모델보다 데이터: 산업용 AI의 성패를 가르는 ‘데이터 중심 AI’ 완전 해부
데이터 큐레이션만으로 라벨링 비용을 75% 절감하고 AI 성능을 15% 향상시킬 수 있습니다. 산업용 AI 도입을 검토하는 의사결정권자를 위한 데이터 중심 AI(Data-Centric AI) 실행 가이드와 글로벌 사례를 정리했습니다.


✅ Key Takeaways
- 모델보다 데이터가 3배 더 중요하다.
동일 모델에서 아키텍처만 바꾸면 성능 향상이 2 AP 미만에 그치지만, 학습 데이터의 품질을 개선하면 최대 6 AP까지 향상됩니다. 즉, 산업용 AI의 성능 병목은 ‘더 복잡한 모델’이 아니라 ‘더 좋은 데이터’입니다. - 데이터 큐레이션으로 비용을 75% 절감할 수 있다.
슈퍼브에이아이의 오토 큐레이트는 12만 장 중 단 3만 장(25%)만 선별해도 동일 성능을 달성합니다. 자율주행 H사의 경우 4억 장 중 단 0.5%(200만 장)만 선별하여 라벨링 리소스를 77% 절감했습니다. - 합성 데이터는 ‘무차별 생성’이 아니라 ‘타겟형 보강’이어야 한다.
모델이 약한 지점을 정확히 진단한 뒤 그 영역에만 합성 데이터를 투입해야 모델 퇴화 현상을 방지할 수 있습니다.
왜 지금, ‘데이터 중심 AI’인가?
McKinsey의 「The State of AI 2025」에 따르면 전 세계 조직의 88%가 최소 1개 이상의 비즈니스 영역에서 AI를 정기적으로 활용하고 있으며, 이는 1년 전 78%에서 가파르게 상승한 수치입니다. 그러나 같은 시기, AI 프로젝트의 70~85%가 여전히 실패하고 있으며, 기업의 77%가 AI의 환각(hallucination) 문제를 우려하고 있습니다.
도입률은 폭발적으로 증가하는데, 왜 성공률은 그대로일까요? 산업 현장의 답은 한 줄로 요약됩니다.
"데이터가 준비되지 않았기 때문이다."
특히 제조업에서는 47%의 기업이 파편화된 데이터에 시달리고 있으며, 65%는 AI를 레거시 시스템에 통합하는 데 어려움을 겪고 있습니다. 더 큰 모델, 더 비싼 GPU를 도입한다고 해서 풀리는 문제가 아닙니다.
이 글에서는 스탠퍼드대 앤드류 응(Andrew Ng) 교수가 2021년 제창한 이래 Google, Tesla, NVIDIA가 표준 방법론으로 채택한 데이터 중심 AI가 무엇이며, 슈퍼브에이아이가 이를 어떻게 엔터프라이즈급 제품으로 구현했는지, 그리고 산업 현장에 도입할 때 어떤 ROI를 기대할 수 있는지 살펴봅니다.
1. 데이터 중심 AI란 무엇인가
데이터 중심 AI란 모델 아키텍처를 고정한 채, 학습 데이터의 품질·구성·분포를 체계적으로 개선하여 AI 성능을 끌어올리는 접근법입니다. 이를 요리에 비유하면 이해가 쉽습니다.
구분 | 모델 중심 AI | 데이터 중심 AI |
비유 | 셰프의 요리 기술을 끝없이 훈련시키기 | 식재료의 품질을 끌어올리기 |
개선 대상 | 신경망 구조, 하이퍼파라미터 | 학습 데이터의 품질·균형·라벨 정확도 |
성능 개선폭 | 동일 데이터에서 2 AP 미만 | 동일 모델에서 2~6 AP (최대 3배 차이) |
확장성 | 새 도메인마다 모델 재설계 필요 | 동일 파이프라인으로 다양한 산업 적용 |
- AP(Average Precision): 객체 탐지(object detection) 모델의 정확도를 측정하는 표준 지표. 1 AP의 차이도 산업 현장에서는 의미 있는 격차로 간주됩니다.
핵심 메시지는 명확합니다. 아무리 뛰어난 셰프도 상한 재료로는 좋은 요리를 만들 수 없습니다. 마찬가지로, 아무리 정교한 모델도 결함이 있는 데이터로는 산업 현장에서 작동하지 않습니다.
산업 데이터에 내재된 3가지 구조적 결함
연구실 벤치마크와 달리, 실제 공장·도로·물류 현장에서 수집된 데이터는 태생적으로 다음 세 가지 문제를 안고 있습니다.
- ① 클래스 불균형(Class Imbalance): 정작 중요한 희소 객체(불량품, 이상 상황 등)의 학습 데이터가 절대적으로 부족합니다. 글로벌 물류 벤치마크인 LOCO 데이터셋에서 ‘pallet(적재함)’은 전체의 78.37%를 차지하는 반면, ‘forklift(지게차)’는 단 0.55%에 불과합니다. 142배의 불균형입니다. AI가 pallet만 잘 인식하고 forklift를 놓치면, 물류 현장에서 인명 사고로 직결됩니다.
- ② 라벨 노이즈(Label Noise): 사람이 부여한 정답 라벨(annotation)에 오류·불일치가 내재합니다. "이것은 스크래치인가, 정상 마모인가?" 같은 경계 판단에서 작업자마다 기준이 다르기 때문입니다. 대규모 산업 데이터일수록 오류율은 5~15%에 달하며, 이 오류가 학습에 그대로 반영되면 AI는 ‘틀린 정답’을 학습하는 악순환에 빠집니다.
- ③ 도메인 시프트(Domain Shift): 학습 환경(예: A 공장 주간 조명)과 실제 배포 환경(예: B 공장 야간 조명)의 조건 차이로 모델 성능이 급락하는 현상입니다. 이른바 Lab-to-Field Gap으로, 연구실에서 99%의 정확도를 보인 모델이 현장에 투입되면 70%대로 떨어지는 일이 비일비재합니다.
📌 의사결정권자를 위한 How-to
- Step 1. 도입 전, 사내 데이터셋의 클래스 분포를 1번이라도 시각화해 보십시오. Pareto 차트만 그려도 상위 3개 클래스가 80% 이상을 차지하는지 확인할 수 있습니다.
- Step 2. 라벨러 2명이 동일 이미지 100장을 독립적으로 라벨링한 뒤 IAA(Inter-Annotator Agreement, 라벨러 간 일치율) 를 측정하십시오. 80% 이하라면 라벨링 가이드라인부터 재정의해야 합니다.
- Step 3. PoC와 본 배포의 환경 차이(조명, 카메라 각도, 시간대)를 미리 체크리스트화하여, 학습 데이터에 해당 시나리오가 충분히 포함되어 있는지 점검하십시오.
이 세 가지 문제는 모델 구조를 아무리 개선해도 해결되지 않습니다. 데이터 자체를 체계적으로 정비해야 하는, 본질적인 문제입니다.
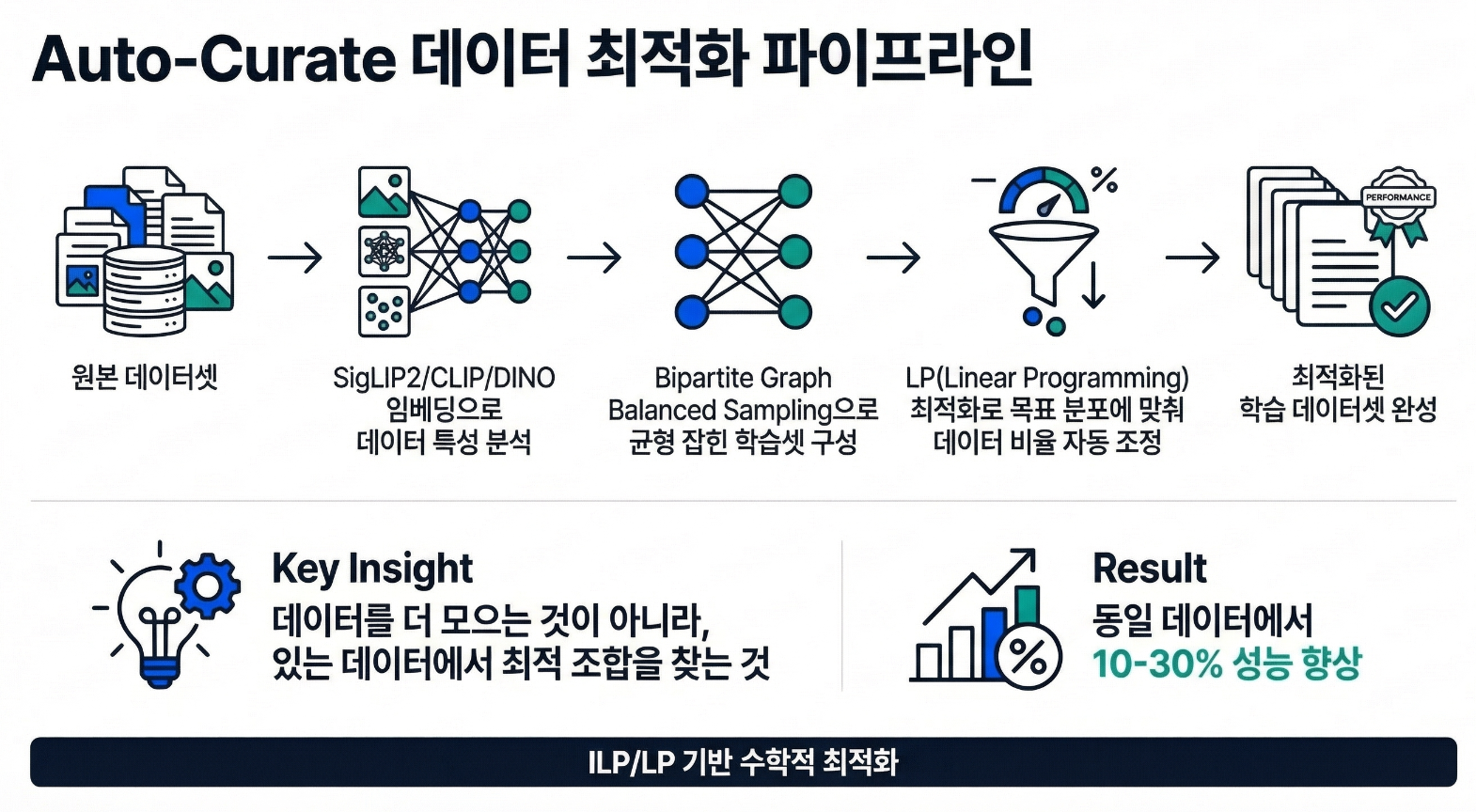
2. 오토 큐레이트 — 데이터 ‘선별’ 기술이 비용을 75% 줄이는 이유
대부분의 경쟁사가 여전히 ‘데이터에 라벨을 붙이는 도구(라벨링 툴)’에 머물러 있는 동안, 슈퍼브에이아이는 한 단계 상위 개념인 "어떤 데이터를 학습에 사용할 것인가" 를 자동으로 판단하는 기술을 2022년 ‘슈퍼브 큐레이트’로 제품화했습니다. 임베딩 기반 자동 큐레이션을 ILP(Integer Linear Programming, 정수계획법) / LP relaxation 최적화로 제품 수준 구현한 기업은 글로벌 시장에서 슈퍼브에이아이가 사실상 유일합니다.
오토 큐레이트의 3가지 핵심 기능
기능 | 무엇을 하는가 | 정량 효과 |
What to label | 1억 장 중 학습에 가장 기여도가 높은 데이터만 자동 선별 | 라벨링 비용 75% 절감 (12만 장 → 3만 장) |
Train/Val Split 최적화 | 학습/검증 데이터를 임베딩 공간에서 균형 있게 분리 | 편향 없는 평가 보장 |
Edge-case Curation | 모델이 약한 희귀 케이스를 우선 선별 | 합성 데이터 생성의 시드(seed)로 재활용 |
어떻게 작동하는가 — 임베딩, 클러스터링, 그리고 ILP
큐레이션의 첫 단계는 각 이미지를 고차원 벡터(임베딩) 로 변환하여 데이터의 의미론적 구조를 파악하는 것입니다. 슈퍼브에이아이는 목적에 따라 4가지 임베딩 모델을 활용합니다.
- BEiT (Masked Image Modeling): 가려짐·잘림이 심한 객체에 강건합니다. 일부만 보이는 객체도 정확히 인식합니다.
- CLIP (Vision-Language): 의미론적 유사성을 포착합니다. ‘쓰러진 사람’처럼 외관이 다양해도 동일 의미로 묶을 수 있습니다.
- DINO (Self-Distillation): 시각 패턴 유사성(모양·색상·질감)을 포착합니다.
- SigLIP 2 (2025): 위 세 가지 학습 기법을 모두 통합한 차세대 모델로, 슈퍼브에이아이는 점진적으로 SigLIP 2로 단일화하고 있습니다.
이렇게 임베딩된 데이터는 K-center 기반으로 군집화(clustering) 됩니다. 큰 클러스터는 ‘Common(일반적 데이터)’, 소형 클러스터는 ‘Edge case(희귀 데이터)’로 자동 분류되어, 이어지는 3단계 ILP 최적화에 입력됩니다.
- Set Cover Problem — 모든 데이터 유형이 최소 1개 이상 포함되도록 최소 데이터셋을 선택합니다. 대규모 데이터에는 LP relaxation + Greedy 근사를 적용해 효율적으로 풉니다.
- 균형 조건 추가 — 특정 유형이 과잉 선택되지 않도록 상한 제약을 추가하여 클래스 간 균형을 확보합니다.
- Edge-case 가중 선택 — 희귀 데이터와 모델 불확실성이 높은 데이터에 가중치를 부여하여 우선 선택합니다.
실제 정량 성과
3가지 실험 결과로 검증된 효과는 다음과 같습니다.
- 데이터 절감: 12만 장 중 3만 장(25%)만 선별하여 동일 성능 달성. 동급의 경쟁사는 동일 성능을 위해 4배 더 많은 데이터가 필요합니다.
- 성능 향상: 동일 데이터 수량에서 큐레이션만으로 AI 성능 15% 향상. LOCO 데이터셋의 pallet/forklift 불균형 같은 편향을 자동 보정한 결과입니다.
- 오류 수정: 오픈소스 자율주행 데이터셋에서 라벨 오류를 선별·수정하여 AI 성능 10% 향상. 모델이나 알고리즘 수정 없이 순수 데이터 품질 개선만으로 달성한 결과입니다.
산업 적용 사례
- 반도체 부품 S사 (회로 이미지 불량 검수): 큐레이션 기반 데이터 선별로 mAP 70.9 → 80.1 (+9.2 p) 달성
- 자율주행 H사 (학습 데이터 4억 장): 200만 장(0.5%)만 선별, 라벨링 리소스 77% 절감
📌 의사결정권자를 위한 How-to
- PoC 단계: 보유 데이터의 5~10%만 무작위 추출해 베이스라인 모델을 학습한 뒤, 동일 수량을 큐레이션 기반으로 선별해 비교 학습하십시오. 차이가 5 AP 이상이면 Data-Centric 접근의 ROI가 명확히 입증됩니다.
- 본 배포 단계: 라벨링 외주 견적을 받기 전에 큐레이션을 먼저 적용하십시오. 외주 단가 × 4배의 비용 차이가 즉시 발생합니다.
3. 모델 진단과 합성 데이터 — ‘약점’을 알아야 ‘처방’이 가능하다
전체 평균 성능 mAP 하나만으로는 현장의 실제 문제를 발견할 수 없습니다. 예컨대 mAP 85%인 모델이 ‘야간 + 소형 객체’ 조건에서는 mAP 40%까지 떨어질 수 있습니다. 이 취약점을 찾아내는 것이 모델 진단(Model Diagnosis)의 핵심입니다.
슈퍼브에이아이의 모델 진단 4단계
전통적으로 모델 평가는 ML 엔지니어가 파이썬 스크립트로 confusion matrix를 그리고 오류 샘플을 수동으로 열어보는 방식이었습니다. 슈퍼브에이아이는 이 과정을 코딩 없이 시각적으로 수행합니다.
- Analytics View — AP, Precision, Recall, F1, Confusion Matrix 등 성능 지표를 클래스별·조건별로 자동 산출합니다.
- Grid View — 오류 이미지를 유형별(FP, FN, 클래스 혼동, 좌표 오차)로 정렬하여 한눈에 확인합니다.
- Slice 기반 시나리오 분석 — ‘야간+비’, ‘소형+가려짐’ 등 조건별로 데이터를 슬라이싱하여 시나리오 단위 성능을 평가합니다. 소프트웨어 테스트의 test case 설계와 동일한 접근입니다.
- 다음 행동 결정 — 진단 결과가 곧 처방으로 직결됩니다.
진단 결과 | 다음 처방 |
특정 클래스 FN(미검출)이 많다 | 해당 클래스의 edge case 데이터 추가 큐레이션 |
특정 조건에서 성능 급락 | 해당 조건의 합성 데이터 생성하여 보강 |
클래스 간 혼동이 심하다 | 라벨링 가이드라인 재정의 또는 라벨 오류 수정 |
전체적으로 성능 정체 | 데이터 불균형 해소를 위한 균형 큐레이션 수행 |
이 진단-처방 사이클은 ML 엔지니어뿐 아니라 현장 엔지니어, PM, 사업 담당자도 직접 사용할 수 있다는 점이 핵심입니다. BDD100K 자율주행 공개 데이터셋 실험에서, ‘진단 → 취약 슬라이스 식별 → 데이터 큐레이션 → 재학습’의 1 사이클을 3시간 만에 완료하여 mAP 10 p 향상을 달성한 사례가 이를 입증합니다.
합성 데이터의 함정 — Habsburg Collapse
데이터가 부족한 산업에서 합성 데이터(Synthetic Data) 는 강력한 해법으로 떠올랐지만, 무분별한 사용은 치명적인 부작용을 낳습니다. 이를 Habsburg Collapse(합스부르크 붕괴) 라 부릅니다.
AI 모델이 합성 데이터로 학습 → 그 모델이 다시 합성 데이터를 생성 → 이 데이터로 재학습 — 이 순환이 반복되면, 모델은 실제 세계의 분포에서 점점 멀어지며 결국 퇴화합니다. 근친교배로 유전적 다양성이 사라지는 것과 같은 원리입니다.
슈퍼브에이아이의 해결책 — ‘타겟형 합성’
슈퍼브에이아이는 합성 데이터를 무차별적으로 생성하지 않습니다. 모델 진단 + 큐레이션과 결합하여, 모델이 실제로 약한 영역에만 정밀 타겟팅된 합성 데이터를 생성합니다.
- Model Diagnosis로 약점 시나리오(야간, 소형 객체, 특정 결함 유형 등)를 식별합니다.
- Edge-case Curation으로 해당 시나리오의 실제 데이터를 시드로 선별합니다.
- 선별된 시드를 기반으로 VLM(Vision-Language Model) 캡션 → 캡션 리프레이징 → ControlNet 생성의 파이프라인으로 자연스러운 합성 이미지를 생성합니다.
이 접근의 핵심은 일반(Common) 데이터는 실제 데이터를 그대로 유지하고, 모델이 약한 Edge case에만 합성 데이터를 보충한다는 것입니다. 전체 분포가 합성에 의해 과도하게 편향되지 않으므로, Habsburg Collapse를 구조적으로 방지합니다.
6개 산업 정량 검증 결과
식품, 와이어 결함, 절연체 결함, 충치, 케이블 손상, PCB 결함 등 6개 산업에서 RTMDet-Ins-s 모델로 검증한 결과는 다음과 같습니다.
비교 실험 | 학습 비용 | 성능 향상 |
학습량 4배 증가 (real only, 24→96 epoch) | 4x | Cable Damage +4%, PCB Defect 0% (정체) |
합성 데이터 5x 추가 (real + synthetic) | 6x | Cable +13%, PCB +13% |
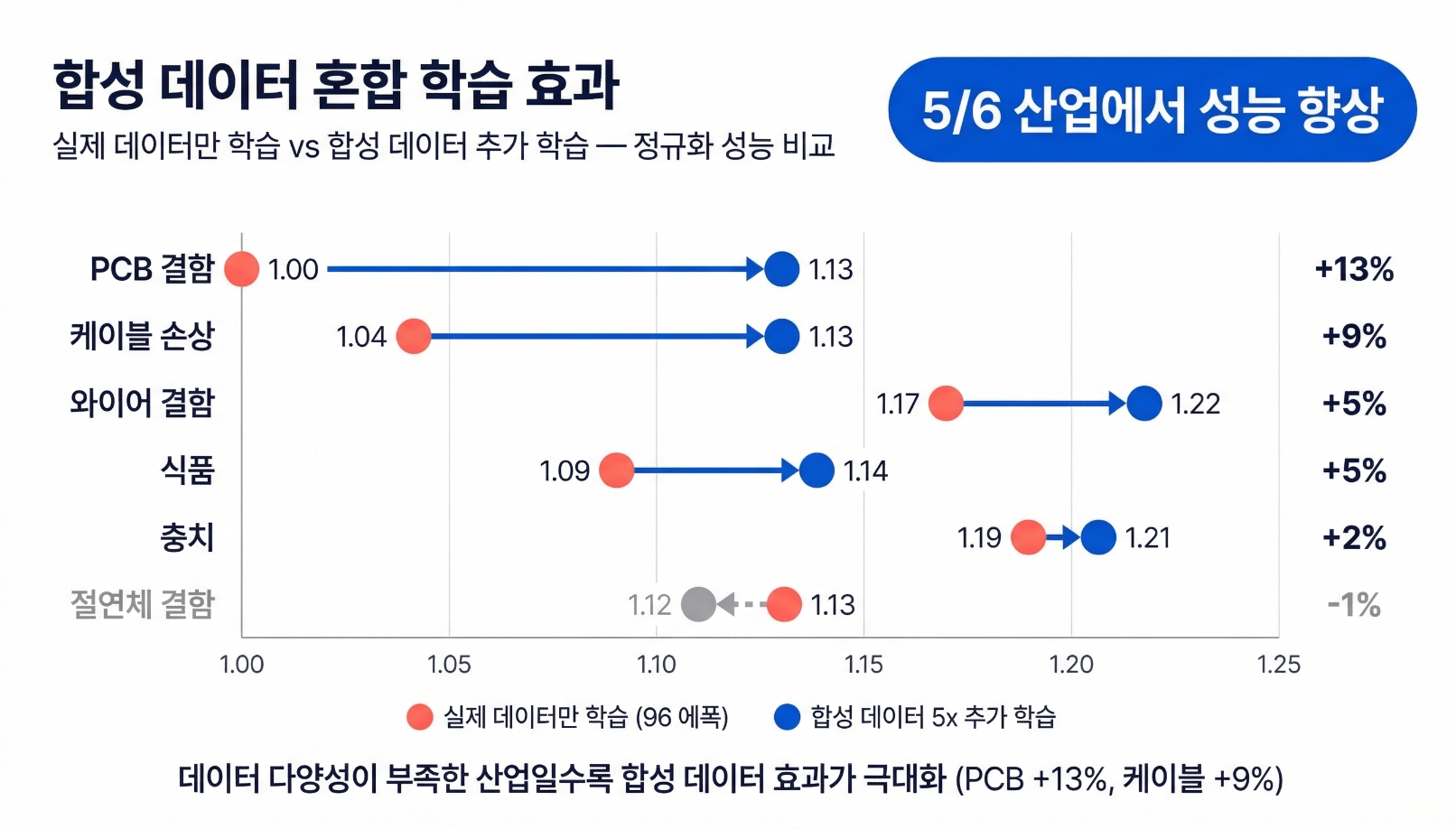
시사점: 학습량(compute) 증가만으로는 데이터 다양성의 한계를 넘을 수 없으며, 합성 데이터가 이 병목을 구조적으로 해소합니다. 6개 산업 중 5개에서 합성 데이터 추가가 학습량 증가보다 효과적이었습니다.
외부 검증 및 사례
- 한화시스템 AI Challenge: 2년 연속 1위. 적외선 데이터 RGB→IR 합성 + pseudo labeling으로 Mask AP 0.320 → 0.362 (약 13% 향상). ICRA 2025 Workshop 논문 발표.

- 공공 안전 P기관 (전기차 화재 감지 AI, 2023~2025 3개년 국책과제): 합성 데이터 + 선별로 mAP 42.2 → 59.2 (+17 p), 100,000장 학습 데이터 구축, Jetson Orin NX16 엣지 배포. 화재 인식률 73.3% (60초 이내 기준, 15개 테스트 영상 중 11개 통과).

- 자율주행 정밀지도 H사 (2025): 6종 희귀 노면 마크(방향화살, 속도카메라, 경고 표지 등)를 SD1.5 + ControlNet으로 합성하여 평균 +12 / 최대 +20 AP 향상. 야간·우천·역광·북미 환경 등 실제 수집이 불가능한 시나리오를 합성으로 돌파한 사례.
- 글로벌 완성차 T사 (Out-of-Domain 검증): 학습 공장에서 테스트 공장으로의 도메인 시프트를 합성 데이터로 해결. 새 고객 현장 투입 시 발생하는 도메인 시프트를 ‘데이터로’ 풀 수 있음을 실증.
- 해외 국방기관 D: FLUX.1-dev + LoKr로 군사차량 합성. 탱크 참조 이미지 단 16장으로 LoRA 학습 후 4,063장 이상의 드론 시점 합성 이미지 생성.
📌 의사결정권자를 위한 How-to
- 합성 데이터 도입의 황금률: "전체 데이터의 ?%를 합성으로 채울 것인가"가 아니라 "어떤 시나리오를 합성으로 보강할 것인가" 를 먼저 정의하십시오.
- 혼합 비율은 자동 탐색에 맡기십시오. 1x 비율이 4x보다 우수한 경우가 존재합니다(과적합 방지). 슈퍼브에이아이의 파이프라인은 최적 혼합 비율을 자동으로 탐색합니다.
- Habsburg Collapse 자가진단 체크리스트: ① 합성 데이터 비율이 50%를 넘는가? ② 합성 데이터 생성에 사용된 모델이 동일 학습 데이터로 학습되었는가? ③ 합성 데이터의 분포 검증(KL divergence 등)을 거쳤는가? — 셋 중 하나라도 해당된다면 즉시 점검이 필요합니다.
❓ FAQ
Q1. 우리 회사는 이미 라벨링 외주 업체를 쓰고 있습니다. Auto Curate를 도입하면 무엇이 달라지나요?
A. 라벨링 외주는 ‘얼마나 많이’ 라벨링할 것인가의 문제이고, Auto Curate는 ‘무엇을’ 라벨링할 것인가의 문제입니다. 둘은 대체재가 아니라 보완재입니다. 다만 큐레이션을 먼저 적용하면 외주에 보낼 데이터의 양 자체가 75% 줄어듭니다. 자율주행 H사의 경우 4억 장 → 200만 장(0.5%)으로 줄어, 라벨링 외주 비용이 동일 비율로 절감되었습니다. 외주 견적을 받기 전 큐레이션을 먼저 적용하는 것이 가장 빠른 ROI 확보 방법입니다.
Q2. 합성 데이터로 학습하면 모델이 ‘가짜’를 배우게 되는 것 아닌가요?
A. 무차별적으로 합성 데이터를 투입하면 그 우려가 현실화됩니다(Habsburg Collapse). 그러나 슈퍼브에이아이의 접근은 "모델이 약한 Edge case에만 타겟팅된 합성 데이터를 보충" 하는 방식입니다. Common 케이스는 실제 데이터를 그대로 유지하므로, 전체 분포의 균형이 유지됩니다. 6개 산업 검증에서 5개 산업이 합성 데이터 5x 추가만으로 평균 +13%의 성능 향상을 보였고, 학습량을 단순히 4배로 늘린 경우보다 효과가 컸습니다. ‘합성 데이터의 양’이 아니라 ‘합성 데이터의 사용처’가 중요합니다.
Q3. 우리는 자체 ML 엔지니어가 부족합니다. 이런 도구를 정말 비개발자가 운용할 수 있나요?
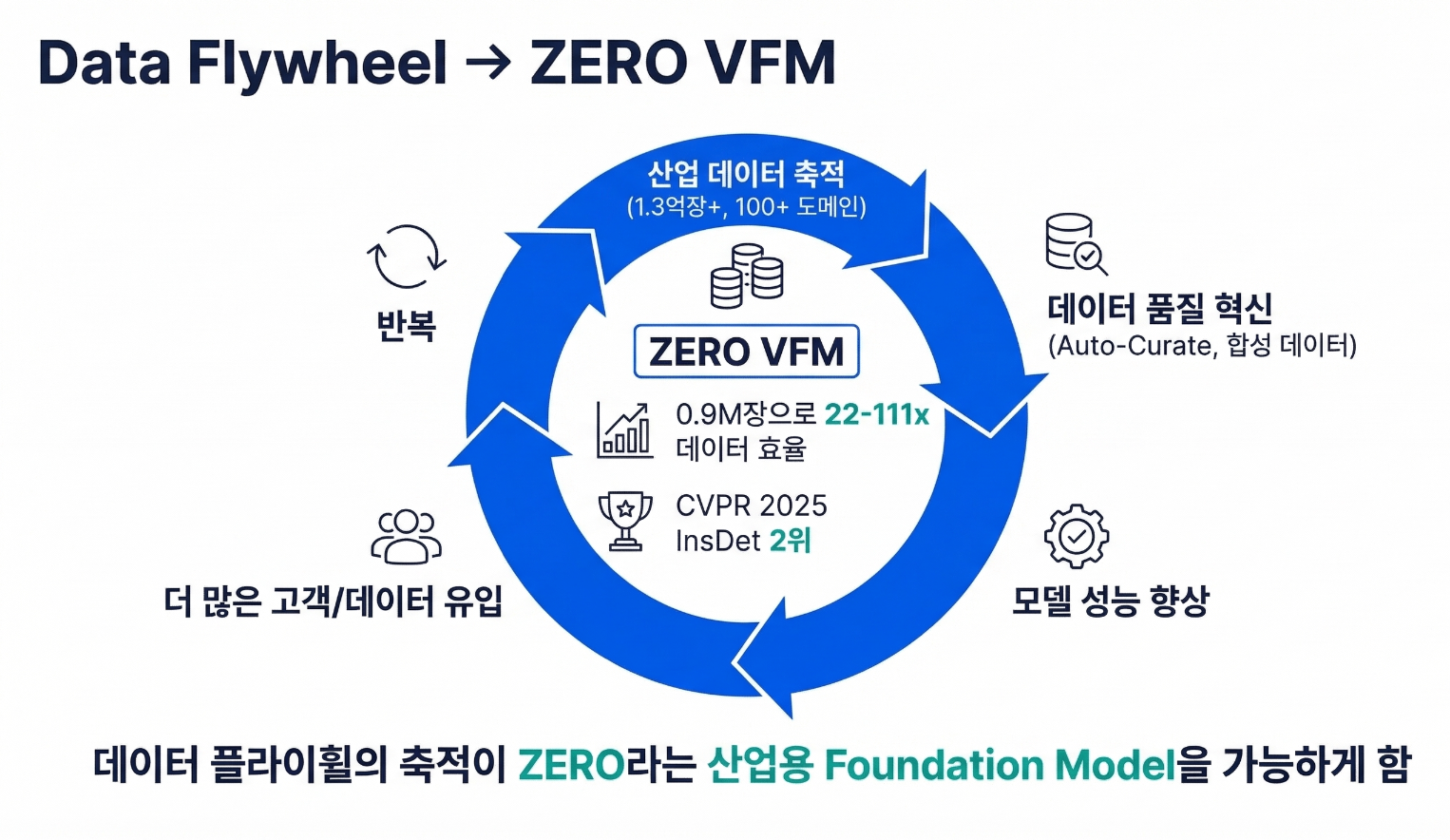
A. Model Diagnosis와 Auto Curate는 처음부터 코딩 없이 시각적으로 운용하도록 설계되었습니다. 현장 엔지니어, PM, 사업 담당자도 "이 모델이 우리 현장에서 잘 동작하는가?"를 직접 검증할 수 있습니다. 실제로 BDD100K 데이터셋에서 비개발자도 '진단 → 큐레이션 → 재학습'의 1 사이클을 3시간 만에 완료하여 mAP 10 p 향상을 달성한 사례가 있습니다. 이것이 슈퍼브에이아이가 강조하는 Data Flywheel의 핵심 — 사람이 매번 개입하지 않아도 데이터가 모델을 개선하고, 개선된 모델이 더 좋은 데이터를 만드는 자기강화 사이클입니다.
데이터 인프라가 곧 AI 경쟁력입니다
산업 현장의 AI는 더 이상 ‘어떤 모델을 쓸 것인가’의 게임이 아닙니다. 오픈소스 모델과 클라우드 GPU가 평준화된 시대에, 진짜 차별화는 "누가 더 좋은 데이터 인프라를 가지고 있는가" 에서 결정됩니다.
다시 정리하면 다음과 같습니다.
- 데이터의 구조적 결함(클래스 불균형, 라벨 노이즈, 도메인 시프트)은 모델 개선으로 해결되지 않습니다.
- Auto Curate는 라벨링 비용을 75% 절감하고, 동일 데이터로 성능을 15% 끌어올립니다.
- Model Diagnosis는 평균 mAP 뒤에 숨은 약점을 시각적으로 드러냅니다.
- 타겟형 합성 데이터는 데이터 수집이 불가능한 시나리오를 돌파하면서도 Habsburg Collapse를 구조적으로 방지합니다.
- 이 네 가지가 결합된 Data Flywheel은, 슈퍼브에이아이가 지난 7년간 1억 3천만 장의 산업 데이터를 축적하며 검증한 검증된 운영 모델입니다.
McKinsey가 분석한 ‘AI 고성과 조직의 공통점’은 명확합니다. 디지털 예산의 20% 이상을 AI에 투입하고, AI 자원의 70%를 사람과 프로세스에 투자하며, 중요 응용 분야에 인간 감독 체계를 갖춘 조직이 ROI를 실현했습니다. 데이터 중심 AI는 이 ‘프로세스 투자’의 가장 구체적인 실행 방안입니다.
🚀 다음 단계
- 30분 인사이트 미팅: 보유 데이터의 분포·라벨 품질·도메인 다양성을 빠르게 진단해드립니다.
- PoC 워크숍: 사내 데이터 1~2만 장으로 Auto Curate와 Model Diagnosis의 효과를 직접 검증해보십시오. 평균 2주 내 결과를 받아보실 수 있습니다.
- Data Flywheel 컨설팅: 단발성 PoC가 아닌, ‘진단 → 큐레이션 → 합성 → 재학습’이 자동으로 순환하는 운영 체계 구축을 지원합니다.
산업 현장에 AI를 도입하려는 의사결정권자라면, 모델 카탈로그를 비교하기 전에 사내 데이터의 상태부터 점검하시길 권합니다. 그것이 AI 프로젝트 실패율 70%의 함정을 피하는 가장 빠른 길입니다.