생성형 AI의 핵심원리와 딥러닝


2023년 한 해를 돌아보면 생성형 AI와 초거대언어모델(LLM)의 한 해였다고 해도 과언이 아니다. 챗GPT와 Stable Diffusion을 비롯한 생성형 AI가 일반 사용자들에게 널리 보급된 것은 물론이고, OpenAI의 GPT-4.0을 시작으로 Google의 Bard와 Meta의 LLaMA2까지 빅테크를 중심으로 많은 기업들이 다양한 언어 모델 기반 서비스를 발표했다.
하루가 다르게 쏟아져 나오는 새로운 기술을 따라가지 못하고 뒤처져 있는 듯한 느낌에 불안해하고 있는 독자분들도 많을 것이다. 그러나 전혀 걱정할 필요가 없다. 다양한 종류의 초거대언어모델도 그 핵심 원리만 이해하면 앞으로 어떤 새로운 모델이 나오더라도 충분히 개념을 적용하고 업무와 일상생활에 활용이 가능하기 때문이다.
생성형 AI와 초거대언어모델 그리고 딥러닝은 매우 밀접한 관계를 가지고 있다. 대부분의 생성형 AI와 초거대언어모델은 심층신경학습망(Deep Neural Network)에 기반한 전이학습(Transfer Learning) 모델을 활용한다는 점에서 기본적인 원리는 크게 다르지 않기 때문이다. 지금부터 초거대언어모델(LLM)에 대한 갈증을 시원하게 해결해 줄 딥러닝 핵심 개념들을 소개하도록 하겠다.
생성형 AI의 핵심이 되는 심층신경학습망(Deep Neural Network)이란?
생성형 AI의 핵심 원리를 이해하기 위해서는 우선 심층신경학습망에 대해 이해할 필요가 있다. 심층신경학습망이란 인간의 신경세포에서 아이디어를 얻어서 만든 뉴런(Neuron)을 연결한 인공신경망(Artificial Neural Network)을 통해 데이터의 특성을 파악하고 새로운 데이터가 주어졌을 때 예측해낼 수 있는 인공지능 기술의 하나로, 흔히 딥러닝(Deep Learning)이라고도 알려져 있다.
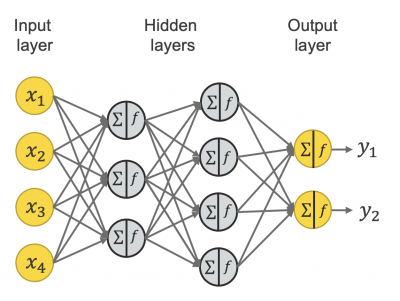
인공지능에 활용되는 신경학습망은 흔히 데이터의 특성(Feature) 학습을 위한 입력층(Input layer)한 개와 여러겹의 은닉층(Hidden layer) 그리고 결과값의 분류(Classification)를 위한 한 개의 출력층(Output layer)로 이루어져 있는데, 이러한 신경학습망 중에서도 여러겹의 은닉층을 가지고 있는 네트워크를 심층신경학습망이라고 한다.
보통 은닉층의 수가 많을수록 계산되는 가중(Weights)과 편향(Biases) 값이 많아지며, 더욱 정교하게 데이터의 특성을 파악할 수 있는 것으로 알려져 있다. 따라서 많은 초거대언어모델은 기본적인 심층신경학습망의 은닉층에 해당하는 부분의 층을 겹겹이 쌓아 매개변수를 증가시키는 방식으로 발전해 왔다.
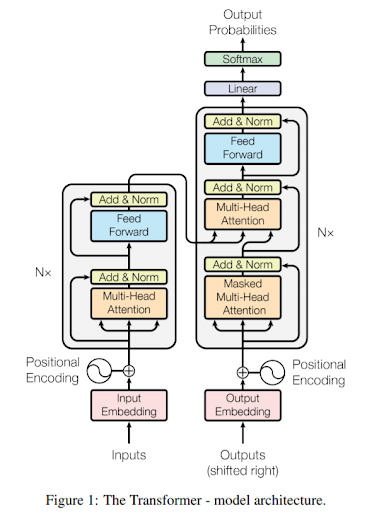
예를 들어 우리에게 친숙한 챗GPT 역시 가장 기초적인 심층신경망 구조와는 조금 다르지만, 은닉층에 해당하는 부분을 늘려가는 방식으로 기하급수적인 성능 개선을 보여줘 왔다. 챗GPT의 극초기 버전인 GPT-1은 처음에 단 12개의 트랜스포머 기반 디코더(Decoder) 구조 레이어를 가지고 있었지만 GPT-2와 GPT-3 등 발전을 거듭하면서 24개, 94개에 이르기까지 점점 더 디코더의 숫자를 늘려가며 사람과 거의 비슷한 수준의 언어 구사 능력을 가지게 된 것이다.
딥러닝 모델은 어떻게 데이터를 학습할까?
심층신경망에 대해서 논할 때 또 한 가지 빼놓을 수 없는 것이 바로 모델이 데이터를 학습하는 과정일 것이다. 여기서 말하는 학습이란 무엇을 뜻하는 것일까? 인공지능의 학습을 한마디로 정의하면 모델이 데이터의 패턴과 관련된 특징을 인지하고, 오차를 최소화하는 방향으로 스스로를 조정하는 과정을 뜻한다. 이해를 돕기 위해 직접 딥러닝 모델이 학습하는 과정을 살펴보도록 하자.
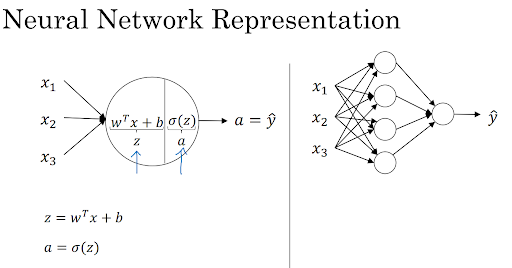
먼저, 데이터가 네트워크의 입력층으로 제공된다. 입력층에서 데이터는 숫자로 구성된 형태로 전환되어 네트워크를 통해 전파된다. 이러한 데이터는 각 은닉층을 통과하면서 가중치와 편향을 조절하고 활성화 함수(Activation Function)를 거치며 다음 층으로 전달된다.
신경망은 데이터를 이해하고 학습하기 위해 각 층의 가중치와 편향을 조정하는 과정을 거친다. 이것이 바로 학습의 핵심이다. 학습 과정에서 신경망은 입력 데이터와 실제 결과 사이의 차이(오차)를 최소화하기 위해 가중치와 편향을 조정하며, 이를 위해 역전파(Backpropagation) 알고리즘이 사용된다.

역전파 알고리즘은 출력층에서부터 시작하여 오차를 다시 역으로 전파하여 각 층의 가중치와 편향을 조정한다. 이러한 과정은 순전파(Forward Propagation)에 사용되었던 수식에 대한 미분 값을 구하여 오차 함수(Loss Function)를 구하여 그 값을 원래 값에 반영해 주는 방식으로 진행되는데, 이를 경사하강법(Gradient Boosting)이라고 한다. 이 과정을 통해 신경망은 데이터 패턴과 관련된 특징을 더 잘 파악하고 예측력을 향상시키게 되는 것이다.
데이터 학습 과정에서는 학습률(Learning Rate)이나 초기값(Initial Value)와 같은 하이퍼 파라미터의 조정이 필수적이다. 하이퍼 파라미터란 쉽게 말해 매개변수를 통제하기 위한 값들이라고 말할 수 있다. 학습률은 가중치 및 편향을 얼마나 빠르게 조정할지를 결정하며, 적절한 학습률은 모델의 학습 효율성과 정확성에 영향을 미치고, 각 학습 과정에서의 초기값을 적절하게 설정하는 과정이 모델의 성능에 직접적인 영향을 미친다.
거대 생성형 AI 모델의 핵심 테크닉, 전이학습이란?
위에서 살펴본 것처럼 딥러닝은 데이터의 특성을 파악하기 위해 매개변수(Parameter)의 수와 방대한 양의 학습 데이터에 의존한다. 그런데 생성형 AI는 그 수와 규모가 상상을 초월할 만큼 많다. 예를 들어 챗GPT의 기반이 되는 GPT-3.5는 약 1750억 개의 매개변수를 가진 것으로 알려져 있고, 학습을 위해 사용한 학습 데이터의 양만해도 무려 45TB에 달하는 천문학적인 양이다.
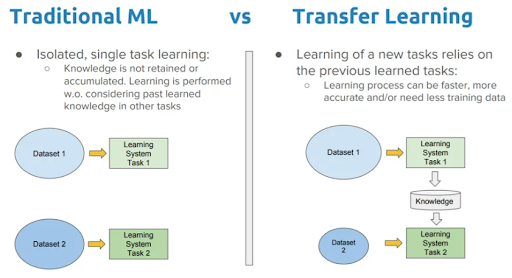
이처럼 방대한 양의 매개변수와 학습 데이터를 여러 모델에 적용하고 활용할 수 있게 해주는 테크닉이 바로 전이학습이다. 전이학습이란 방대한 양의 데이터를 학습해 얻게 된 가중치와 편향 등 정보를 가지고 있는 심층신경학습망 기반 모델을 만들고, 비교적 간단한 추가 커스터마이즈 과정을 더해 다양한 문제를 해결할 수 있도록 설계하는 딥러닝의 학습 방법을 말한다. 따라서 전이학습 모델은 일반적인 데이터를 통한 사전학습(Pre-training)이라는 과정과 용도에 맞게 추가적인 미세조정(Fine-tuning)이라는 두 단계의 과정을 거쳐서 탄생한다.
그렇다면 전이학습 모델은 왜 번거롭게 사전학습과 미세조정이라는 두 가지 과정을 거치는 것일까? 딥러닝 모델은 보통 학습 데이터의 양이 많고 가중치와 편향 등 매개변수의 숫자가 많을수록 성능이 좋은 것으로 알려져 있다. 따라서 글의 서두에 살펴본 Transformer와 그에서 파생된 BERT와 GPT 역시 대표적인 전이학습 모델이라고 할 수 있다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.