어떤 질문을 던질 것인가?: ChatGPT 프롬프트 엔지니어링 가이드

인간과 대화하며 업무에 도움을 주는 인공지능이 생기는 걸까? ChatGPT에 이어 텍스트를 넣으면 이미지를 생성해주는 DALLE2나 Stable Diffusion과 같은 텍스트 투 이미지 모델, 또한 텍스트를 넣으면 동영상을 만들어 주는 텍스트 투 비디오 모델 등 다양한 생성형 AI 모델이 나오고 있다.
ChatGPT와 같은 생성형 AI 모델에 입력하는 사람의 질문 또는 지시와 같은 문장을 (Prompt)라고 하는데 좀 더 원하는 결과를 얻기 위해 프롬프트를 최적화하는 것을 프롬프트 엔지니어링 (Prompt Engineering)이라고 한다. 최근의 이 프롬프트 엔지니어의 연봉이 수억 대라고 해 화제가 되기도 했다. 그 만큼 ChatGPT와 같은 생성형 AI 모델이 많이 등장하는 가운데 이들을 활용할 수 있는 능력이 중요해지고 있다는 의미일 것이다.
개인이나 회사라면 이런 모델을 사용해 보고서나 마케팅 카피 혹은 블로그를 작성한다면 원하는 결과물에 대한 초안 혹은 더 좋은 결과물을 얻어 업무 생산성을 높일 수 있을 것이고, DALLE2나 Stable Diffusion과 같은 이미지 생성 모델의 프롬프트 사용방법도 어느 정도 안다면 이제 원하는 이미지도 생성할 수 있는 능력이 생기는 것이다.
AI 기반 서비스를 제공하는 회사라면 프롬프트 엔지니어링으로 고객에게 서비스를 제공하는 데 활용할 수 있고, 또한 좋은 프롬프트와 거기서 나온 양질의 데이터셋을 다시 모델에게 학습시켜 모델을 정교화하거나 자체 모델을 만들 수도 있으니 억대 연봉이 말이 되는 게 아닐까?
이번 글에서는 ChatGPT를 활용해 질문을 하거나 결과물을 생성할 때 좀 더 원하는 결과물을 얻을 수 있도록 자연어로 하는 엔지니어링이라고 할 수 있는 프롬프트 엔지니어링의 몇 가지 핵심 원칙에 대해 알아보도록 하자.
AI 언어모델 구조에 대한 이해
우선 우리가 활용하는 언어모델(Language Model)의 작동방식과 한계를 대략적으로 이해하면 프롬프트 작성에 도움이 될 것이다. 언어모델은 일반적으로 다음 단어를 예측하는 것을 목표로 학습을 진행하는데 예를 들어 “철수는 학교가 _____” 다음에 어떤 단어가 올 지 정답이 나올 확률을 극대화하는 과정에서 적절한 모델의 임베딩과 가중치를 얻게 된다.
대량의 데이터셋을 학습하는 과정에서 여러가지 패턴을 학습하게 될 것이고 따라서 어떤 데이터를 학습 했는지가 영향을 미칠 수 있다. 하지만 학습된 모델을 기반으로 문장을 생성할 때 가장 많이 학습한 패턴이나 단어를 내뱉을 확률이 크지만 아닐 확률도 존재한다.
학습을 마친 모델에서 문장을 만들어 내는 과정을 추론(Inference)라고 하는데 가장 높은 확률을 가진 단어들만 순차적으로 뽑아가며 문장을 완성할 수도 있고 단어를 선택할 기준을 정해 랜덤하게 샘플링해 문장을 완성할 수도 있다.
ChatGPT를 대화창이 아닌 API로 이용하거나 아니면 GPT-3 모델의 경우 Playground에서 문장을 생성해 보면 오른 쪽 창에 Temperature나 Top P라는 파라미터들이 있는데 이들은 모두 단어를 샘플링할 기준을 정하는 것이다. 예를 들어 Top P가 0이라는 것은 무조건 가장 나올 확률이 높은 단어들만 선택해 문장을 만드는 것이므로 시도할 때 마다 같은 결과를 얻을 것이다. Top P가 0.7이라는 것은 다음 단어가 나올 확률분포에서 누적 확률 70%까지의 단어 풀에서 단어를 샘플링하겠다는 것으로 보다 높은 변동성, 자유도를 의미한다고 할 수 있다.

따라서, 앞서 어떤 단어를 입력하는 지 프롬프트에 따라 결과가 민감하게 반응할 수도 있고 샘플링 방식의 설정에 따라 매번 결과물이 달라질 수도 있다.
반면, ChatGPT는 학습한 데이터셋을 바탕으로 다음에 올 단어의 확률분포에서 단어를 하나씩 선택해 문장을 생성해 내는 것이므로 사실이 아닌 것에 대해서도 유창하게 말을 할 수 있다. 이를 환각(Hallucination)이라고 하는데 현재 대형 언어모델의 가장 큰 문제점으로 지적되고 있다.

ChatGPT 프롬프트 엔지니어링 핵심 원칙
이제 ChatGPT에 프롬프트를 입력할 때 어떻게 하면 ChatGPT를 활용해 그 능력을 잘 끌어낼 수 있는 지 프롬프트 작성 시 몇 가지 핵심 원칙에 대해 알아보도록 하자. 아래 내용은 DeepLearning AI의 Prompt Engineering for Developers 무료 강의에 나오는 가이드라인을 요약한 것이다.
강의에서는 API로 해 볼 수 있는 예문들이 나오는데 ChatGPT 대화창으로 옮겨 테스트해 보았다.
❶ 명확하고 구체적인 프롬프트
앞서 언어모델이 문장을 만드는 방법을 대략적으로 알아보았는데 무언가 단어의 사용이 꼬이거나 앞뒤 문장이 명확하게 이어지지 않으면 내용이 원하지 않는 방향으로 흘러갈 가능성이 커지게 된다.
“Write clear and specific instructions”
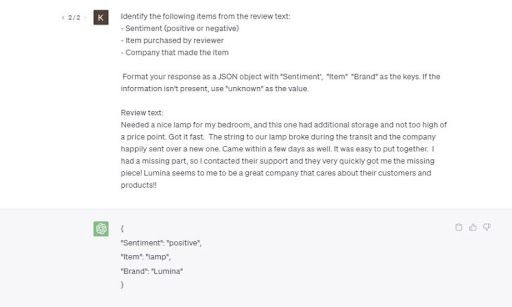
따라서 원하는 태스크를 잘 수행하기 위한 명확한 지시문과 추가 정보를 전달해야 하고 원하는 결과물의 포맷이 있다면 구체적으로 써줄 수 있다. 아래 예시에서는 고객의 리뷰에 대해 감성분석 결과와 아이템, 제조회사 명을 추출하도록 하고, Sentiment, Item, Brand를 Key로 하는 JSON 형태로 결과물을 달라고 요청했다.
❷ 지시만 하지말고 보여주기
백 마디 말보다 한 번 보여주는 게 낫다고 했던가? 명확한 지시문과 함께 이렇게 하라고 예시를 주는 것도 모델에게 원하는 결과물을 얻어낼 수 있는 또 다른 방법이다.
“Showing, not just telling, is often the secret to a good prompt.”
‘인내심에 대해 이야해조’라고 하고 그에 대한 속담을 나열하는 한 가지 예를 보여준 후 ‘회복력에 대해 이야기해조’라고 입력하면 역시 회복력에 대한 속담을 나열하는 것을 볼 수 있다. 아래 사례의 경우 예시가 없다면 다른 형태로 답변을 할 가능성이 높을 것이다.

❸ 프롬프트의 구조화
모델은 입력 문장을 넣자마자 결과물을 내뱉기 마련인데 특히 복잡한 과제의 경우 틀린 답변을 내놓기 쉽다. 이런 경우 모델이 성급한 결론을 내놓기 전에 생각할 시간 혹은 방법을 주는 것이다.
“Give the model time to think”
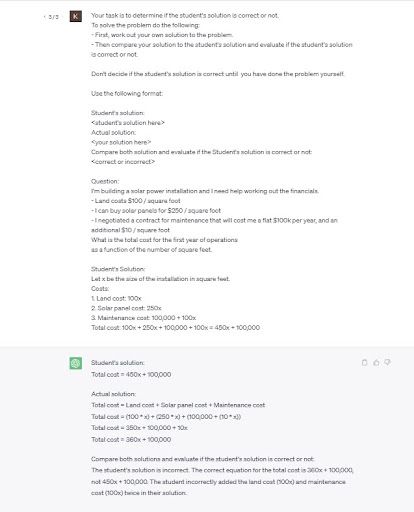
아래와 같이 여러가지 조건을 가진 문제를 주고 이에 대한 학생의 답이 맞는 지 틀린지 답하라는 문제인데, 언뜻 복잡해 보이지만 사실 주어진 조건들을 고려해 1차 방정식을 세우는 문제이다. 학생은 풀이과정 중 Maintenance cost에서 10x를 100x로 적었지만 ChatGPT는 학생의 답이 옳다고 대답했다. 이 경우 모델에게 먼저 이 문제에 대한 너의 답변을 작성하라고 하고 이를 학생의 답변과 비교해 학생이 맞는지 틀리지 답변을 하도록 프롬프트를 수정해 해결할 수 있었다.
요 정도만 기억하고 있어도 원하는 결과물가 잘 나오지 않아 여러가지 프롬프트를 테스트해 볼 때 가이드가 될 수 있을 것이다. 물론 프롬프트 엔지니어링에 대한 논문은 계속 나오고 있는 것 같다.
앞서 살펴본 바와 같이 현재로써 언어모델의 한계도 분명하지만 반대로 이용하기에 따라 가능성도 무궁무진할 수 있다. 향후 모델 자체가 더 발전해서 사람의 비논리적인 문장이나 불명확한 말들도 찰떡같이 알아들을 정도로 발전한다면 프롬프트 엔지니어링이라는 것은 필요없겠지만 그전까지는
ChatGPT와 같은 생성형 모델을 활용할 수 있는 능력이 경쟁력이 될 것으로 보인다. 정답은 없지만 각 생성 모델에 대한 프롬프트 방법을 이해하고 시도하고 자신만의 노하우를 쌓아보는 건 어떨까?
| ||
마테크와 마케팅 데이터 분석에 대해 이야기 합니다. |
