초거대언어모델(LLM)과 일반인공지능(AGI)의 탄생 조건


뇌과학이 말하는 일반인공지능의 조건
초거대언어모델(LLM)을 비롯한 생성형 인공지능(Generative AI) 기술의 발전은 인간처럼 의식을 가지고 다방면의 태스크를 지시 없이도 스스로 처리해 내는 일반인공지능(Artificial General Intelligence, AGI)의 실현 가능성에 대한 기대를 한층 끌어올렸다. 이러한 기대는 얼마 전 오픈에이아이가 GPT-4에 이미지 인식이 가능한 멀티 모달(Multi Modal) 기능의 탑재를 발표하면서 점점 더 현실화되고 있는 것처럼 보인다.
그렇다면 현재의 멀티 모달 초거대언어모델 기술로 인간의 지시 없이도 인간처럼 다방면의 일을 스스로 척척해내는 일반인공지능의 개발이 가능할까? 일부 인공지능 연구자와 엔지니어들은 GPT나 LLaMA와 같은 초거대언어모델의 매개변수(Parameter)를 기하급수적으로 늘려나가면 인간과 비슷한 수준의 추론능력을 획득하는 것은 물론이고 인지능력까지 획득하게 되어 일반인공지능의 개발이 가능해질 것이라고 주장하기도 한다.
하지만 뇌과학자들은 현재의 딥러닝 기술을 유지한 채 매개변수와 학습 데이터셋의 크기를 늘리는 방법만으로는 일반인공지능을 실현시킬 수 없을 것이라고 단호히 말한다. 우리 뇌가 사물을 인식하고 학습하는 방식은 딥러닝의 그것과는 매우 다르기 때문이다. 따라서 일반인공지능을 실현하기 위해서는 방대한 양의 학습 데이터에 의존하는 기존의 딥러닝 개발 방식과는 근본적으로 다른 접근 방식이 필요한 것이다.
뇌과학과 인공지능은 매우 밀접하게 연관되어 있으며 일반인공지능 개발을 위해 필수적인 두 개의 바퀴와 같다. 따라서 인공일반지능 개발이 가능할지 여부를 살펴보기 위해서는 인공지능 엔지니어링의 관점뿐 아니라 뇌과학의 관점에서도 우선 우리 뇌의 복잡한 구조를 살펴볼 필요가 있다. 또한 ‘지식 표현 문제’를 통해 컴퓨터가 과연 진짜로 학습 데이터를 이해하고 있는지에 대해 엄밀히 살펴보자.
1. ‘오래된 뇌’의 부재
1952년 뇌 과학자 폴 맥린이 주장한 삼위일체뇌 이론에 따르면, 우리 뇌는 진화의 순서에 따라 세 개의 부분으로 나뉘어 진화했다. 가장 먼저 진화한 것은 흔히 '파충류의 뇌'로 알려진 R복합체인데, 이는 인간의 생존을 위한 부분을 담당한다. 생존의 위협으로부터 스스로를 지키기 위해 무리를 이루어 생활하거나 욕구를 갈망하고 선하거나 악한 의도를 가지게 만들어주는 부분이 바로 이 ‘파충류의 뇌’이다.
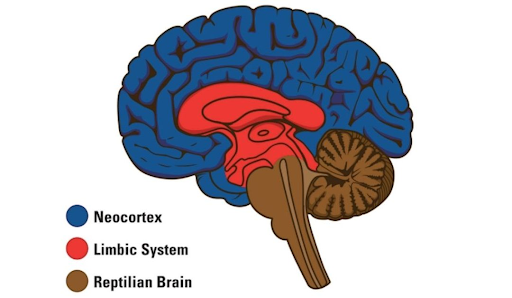
흔히 SF 영화에 등장하는 인공지능은 스스로 판단하여 인간을 공격하거나 감정을 가지고 스스로의 존재를 궁금해하며 고뇌하는 존재로 그려진다. 이러한 행동은 모두 인공지능이 우리 뇌 속에 존재하는 '파충류의 뇌'를 가지고 있다는 가정하에 생겨난다. 그러나 현재의 기술로 구현된 멀티 모달 초거대언어모델은 이러한 파충류의 뇌를 가지고 있지 않기 때문에 주어진 지시와 명령에 따라 태스크를 수행하는 것 외의 활동은 하기 어렵다.
또한 우리 뇌에는 정서적 교감과 모성애 등 감정을 담당하는 변연계라는 부분이 있는데, '포유류의 뇌'라고도 불린다. '파충류의 뇌'와 '포유류의 뇌' 모두 이름에서 알 수 있듯이 인간보다 지능이 떨어지는 여러 동물들에게서도 발견되는 부분이다. 이 두 가지를 가장 최근에 발달한 이성과 지능적인 행위를 담당하는 '새로운 뇌'인 신피질과 구분하기 위해 '오래된 뇌'라고 표현하겠다.
문제는 우리 뇌의 '새로운 부분'인 신피질이 '오래된 뇌'의 지배를 받는다는 사실이다. 한 가지 예로 우리의 신피질은 밤늦게 야식을 먹는 것이 건강에 해롭다는 사실을 알고 있다. 그러나 우리가 꽤나 잦은 빈도로 비이성적인 판단을 내리고 밤늦게 야식을 시켜 먹는 이유는 바로 우리 뇌가 여전히 생존을 위해 에너지를 비축해 두어야 한다는 '오래된 뇌'의 지배를 받기 때문이다.
이처럼 인간의 뇌는 오래된 뇌와 새로운 뇌의 싸움이 매 순간 반복되는 전쟁터다. 인간은 언제나 이성적인 판단을 내리지 않으며 그 이유는 우리의 ‘오래된 뇌’ 때문이다. 따라서 무언가를 끊임없이 배우고, 생존 욕구와 의도를 가진 사람 같은 인공지능을 만들어내기 위해서는 단순히 지능뿐 아니라 스스로 삶의 목적을 가질 수 있는 부분을 구현해 내야 한다. 그러나 많은 사람들이 알고 있듯이 현재로서 이런 기계는 존재하지 않는다.
2. 지식 표현 문제 해결
챗GPT와 같은 초거대언어모델은 '저녁 메뉴 추천'같은 비교적 간단한 테스크부터 '인생의 의미'와 같은 철학적이고 심오한 주제에 이르기까지 다방면의 주제에 대해 훌륭한 답변을 내놓는다. 매우 그럴듯하고 설득력 있는 챗GPT의 답변을 보면서 사람들은 감탄하고 머지않아 인공지능의 지능이 인간을 추월하는 특이점(Singularity)가 올 것을 걱정한다. 그런데 과연 챗GPT는 스스로가 생성해 내는 문장의 의미를 진짜로 이해하면서 대답하는 것일까? 이에 대한 해답은 우리 뇌와 초거대언어모델이 사물을 인식하는 과정을 비교해 보면 찾아낼 수 있다.

인간의 뇌는 실제로 몸을 움직이는 과정을 통해 세상을 모형화하여 데이터를 학습한다. 우리의 뇌가 어떠한 대상을 언어화하기 위해서 우선 설명하고자 하는 대상을 모형화하여 시뮬레이션 하고 이해하는 프로세스가 특히 더 중요하다. 예를 들어 누군가가 운전하는 방법에 대해 설명을 하려고 할 때, 그는 스스로 운전을 하면서 시동을 걸고 기어를 넣고 가속페달을 밟으면서 자동차를 앞으로 나아가게 하면서 자동차의 작동원리를 이해한다. 인간은 이처럼 몸을 움직여 체득한 경험을 지식이라는 형태로 전달하여 사람들에게 언어로 설명한다.
초거대언어모델은 인간과 같이 움직임과 시뮬레이션이라는 과정을 통해 설명하고자 하는 대상에 관한 지식을 체득하지 않는다. 대신에 초거대언어모델은 통계학에 의존하여 마치 낱말 퍼즐을 맞추듯이 질문에 대한 답을 짜깁기하여 생성해낸다. 초거대언어모델의 뼈대가 되는 알고리즘인 언어 모델(Language Model)은 기본적으로 방대한 양의 말뭉치(Corpus)를 사전학습한 뒤에 새로운 문장이나 단어가 주어졌을 때 그것을 예측하는 형태로 작동하는 수학적 모델이다.
이처럼 컴퓨터가 지식을 이해하는 방식에 관한 문제를 '지식 표현 문제'라고 하는데, 이는 현재의 인공지능 언어모델이 초거대언어모델로 진화하기 위해서 반드시 극복해야 할 문제 중 하나다. 인간의 오래된 뇌에 관한 문제에서 살펴보았듯이 실제로 지식의 의미를 이해하는 것은 인간의 개입 없이 스스로의 판단에 의해 행동하기 위한 중요한 요소이기 때문이다. 그러나 인간이 제공하는 방대한 양의 텍스트 데이터를 사전 학습하는 현재의 방식만으로는 인공지능이 진짜로 지식을 가지고 있다고 말할 수 없다.
2010년대 후반부터 이어진 전이학습(Transfer Learning) 기법과 클라우드(Cloud) 기술의 발전은 방대한 양의 데이터를 저장하고 활용할 수 있게 해주었다. 이를 바탕으로 탄생한 초거대언어모델은 산업과 용도에 관계 없이 다양한 분야에서 활발하게 사용되며 우리 생활을 편리하게 해주고 있다. 그러나 위에서 살펴보았듯 인공지능 연구의 궁극적인 목표인 일반인공지능 실현을 위해서는 아직 갈길이 멀다. 기술을 한단계 더 발전시키기 위해서 우리 스스로의 뇌에서 얻은 힌트를 바탕으로 근본적으로 다른 접근이 필요한 것일지도 모른다.
| ||
문과 출신으로 AI 스타트업에서 데이터 사이언티스트로 일하고 있습니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.