[3분 알고리즘] XGBoost

![[3분 알고리즘] XGBoost](https://storage.ghost.io/c/73/74/73741b5e-0bdf-4e6f-9161-743bc6f76d78/content/images/size/w2000/2023/05/20230511110248.png)
랜덤포레스트가 한 번에 다양한 데이터셋을 만들어 그 결과를 평균해 다양한 데이터셋에서 안정적 성능을 얻을 수 있는 알고리즘을 만들었다면 그라디언트 부스팅은 오차가 줄어드는 방향으로 계속 학습을 해가며 정확도를 높일 수 있는 알고리즘이였다.
하지만 그라디언트 부스팅은 이전 학습기의 결과를 이어 받아 순차적으로 학습하기에 시간이 많이 걸리는 게 단점이였다. 이번 글에서는 그라디언트 부스팅을 속도와 정확도 면에서 개선한 모델이자 캐글과 같은 머신러닝 대회에서 가장 좋은 성능을 내고 있는 모델 중에 하나인 XGBoost에 대해 알아보도록 하자.
그라디언트 부스팅 보다 빠르게 - 병렬학습
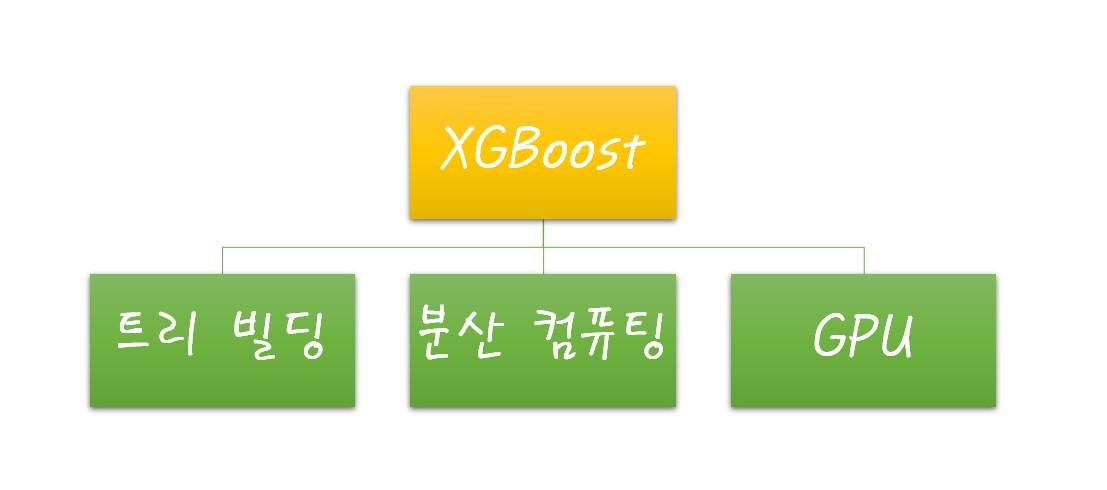
그라디언트 부스팅이 병렬 학습 지원이 되지 않아 순차적으로 데이터를 학습하는 데 시간이 많이 걸린다면 이 알고리즘을 병렬 학습이 지원되도록 구현한 것이 XGBoost이다. XGBoost는 병렬 학습을 위해 다양한 트리빌딩 방법, 분산 컴퓨팅 시스템, 그리고 GPU 등을 지원한다.
먼저 병렬트리 빌딩이다. 그라디언트 부스팅 알고리즘은 분기할 때마다 모든 피처의 모든 데이터 값을 고려해 손실함수, 즉 MSE 혹은 지니계수가 가장 낮아지는 최적의 분기점을 계산해 분할해 나갔다. XGboost의 핵심 아이디어는 각 피처 데이터들을 일정 간격으로 나눠 최적의 분기점을 찾는다는 것이다. 일정 간격으로 나눠진 세브 데이터셋 안에서 최고의 split을 찾는 과정을 병렬 처리할 수 있는 것이다.
- exact : 모든 피처의 모든 데이터 값을 후보군으로 고려하는 바닐라 그라디언트 부스팅 모델. 머신러닝에서 바닐라란 가장 기본적인 모델을 의미한다.
- approx: 분위수(quantile)로 데이터를 나눠 각 그룹별로 최적의 분할 포인트를 찾는 방식, 각 그룹에서 split 했을 때 가장 지니계수가 낮아지는 그룹에서 split이 이뤄지게 된다.
- hist: 분위수가 아니라 히스토그램으로 데이터셋을 나눠 최적의 분할 포인트를 찾는 방식
- gpu_hist: hist의 gpu구현 버전, 다양한 요인이 있을 수 있겠지만 대규모 데이터셋에서 가장 빠를 것으로 예상된다.
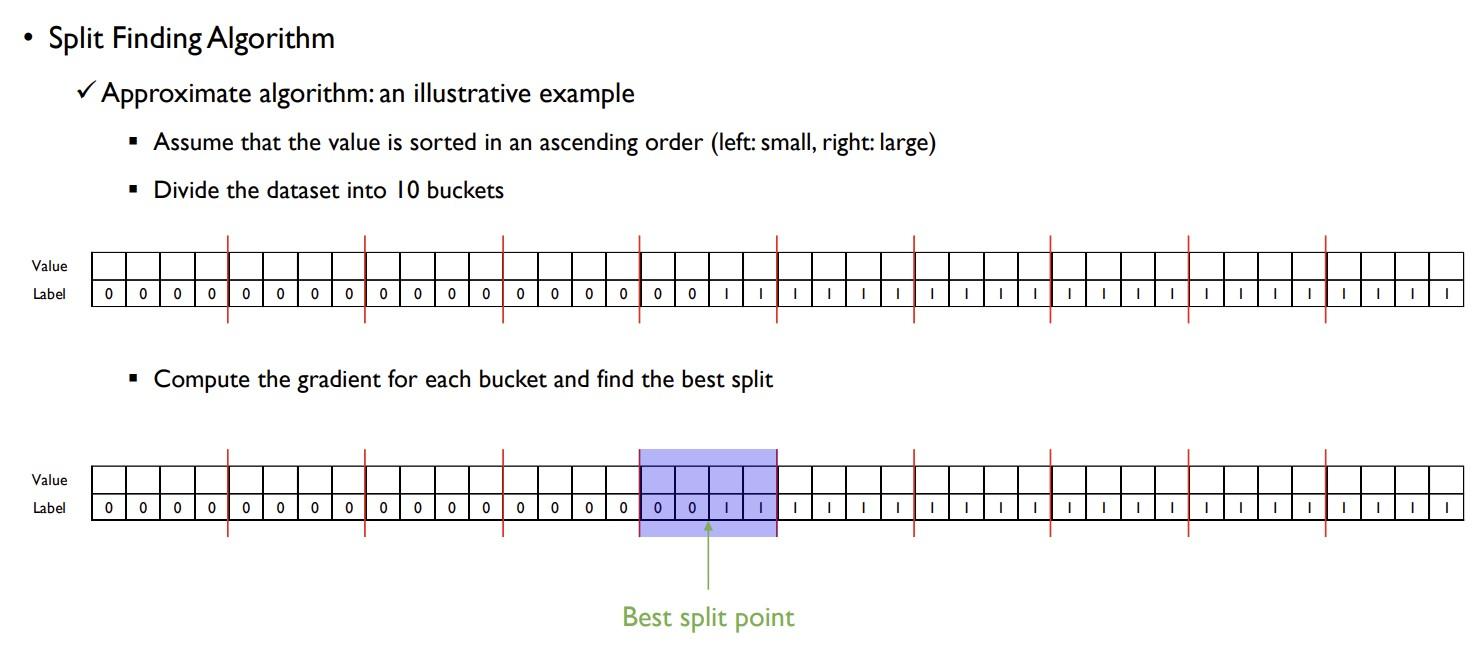
위의 예시에서 exact 방식이라면 40개의 샘플을 오름차순으로 정렬 후 인접한 두 값들의 중앙값을 분할 후보로 한다면 모든 데이터가 유니크 값이라고 가정하면 최대 39번 손실함수가 최소가 되는 분할점을 계산해야 할 것이다. 하지만 그룹(버킷)을 10개로 나눈다면 각 그룹에서 3번의 계산이 총 10개 그룹에서 이뤄짐으로 30번만 계산하면 되고 각 그룹의 계산을 다른 스레드로 처리할 수 있다.
approx과 hist 모두 CPU 리소스를 활용하는데 CPU가 하나밖에 없다면 하나의 CPU에서 여러 개 스레드를 처리해야하겠지만, 클라우드 컴퓨팅을 사용하면 멀티 CPU를 활용해 여러 개로 나눠진 스레드들을 처리할 수 있다. XGBoost는 여러 대의 컴퓨터에서 동시에 학습을 할 수 있도록 분산 컴퓨팅을 지원하므로 대규모의 데이터셋이라면 approx 또는 hist 방식과 분산 컴퓨팅 조합으로 학습을 진행할 수 있을 것이다.
하지만 일반적으로 수십 만개 행을 가진 데이터셋의 경우 CPU가 하나 밖에 없다면 GPU를 사용해 트리 빌딩을 효율적으로 병렬화시킬 수 있다. GPU가 있다면 사이킷런 XGBoost 파라미터 가운데 tree_method=’gpu_hist’로, gpu_id에 gpu 번호를 할당하면 된다. 사이킷런의 대부분 머신러닝 라이브러리는 GPU를 지원하지 않지만 XGBoost와 LGBM의 경우 GPU를 활용한 병렬 학습을 지원한다.
그라디언트 부스팅 보다 정확하게 - 규제 (Regularization)
선형회귀 알고리즘에서 모델이 훈련 데이터에 과적합되는 것을 막기 위해 손실함수에 패널티를 부과해 가중치가 커지는 것을 막았다. 가중치가 커지면 훈련 데이터에 과적합될 가능성도 커지기 때문이다. 그래서 가중치들의 절대값의 합이 최소가 되도록 손실함수에 패널티를 준 것이 Lasso 이고 가중치들을 제곱한 값이 최소가 되도록 패널티를 준 것이 Lidge였다.
그라디언트 부스팅에서도 이전 학습기의 잔차를 학습해 나가며 잔차를 줄여나가는 과정에서 훈련 데이터에 과적합되지 않도록 리프 노드들의 가중치들의 절대값의 합 또는 가중치들의 제곱의 합을 손실함수에 더해 학습할 수 있다. XGBoost의 하이퍼 파라미터 가운데 reg_alpha는 가중치들의 수가 많을 때 사용할 수 있는 Lasso(L1 규제)이고, reg_lambda는 가중치 크기를 좀 더 효과적으로 제어할 수 있는 Ligde(L2 규제)이다.
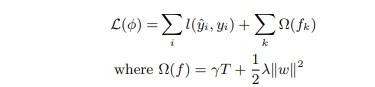
XGBoost의 규제(Regularization)을 추가한 손실함수
- 사이킷런으로 모델링하기
XGBoost는 그라디언트 부스팅 모델을 보완하기 위해 원래 C++ 언어로 제작되었지만 파이썬이나 사이킷런 버전으로도 제작되어 사용할 수 있다. 오리지날 XGBoost를 기반으로 사이킷런으로 랩업 된 버전의 경우 fit, predict와 같은 사이킷런의 함수 뿐만 아니라 모델과 함께 파라미터를 넣으면 하이퍼 파라미터 테스팅과 크로스 밸리데이션을 동시에 진행해 주는 사이킷런 grid search에서도 사용할 수 있어 사이킷런 시스템 상에서 더 원활하게 사용할 수 있다.
분류 문제를 위해 10만 개의 행과 1000개 컬럼을 가진 임의의 데이터를 생성하고 XGboost로 모델을 훈련시켜 보자. tree_method로 hist와 gpu_hist를 사용을 비교하면 gpu_hist를 사용한 경우가 12초로 약 5배 정도 빨랐다. 하루 10시간 이상 종일 학습시켜야 하는 대규모 데이터셋의 경우 gpu를 사용하는 것이 조금 혹은 아주 수고를 덜 수 있는 방법인지 짐작할 수 있을 것이다.

| ||
마테크와 마케팅 데이터 분석에 대해 이야기 합니다. |

* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.