언어와 비전 데이터를 함께 학습하는 멀티모달 AI에 대하여


“멀티모달(Multi Modal) AI”
멀티모달 AI는 여러 가지 유형의 데이터 또는 정보를 함께 활용하여 인공 지능 시스템을 구축하는 접근 방식을 나타냅니다. 이러한 다양한 유형의 데이터는 주로 텍스트, 이미지, 음성, 비디오 등이 될 수 있습니다. 멀티모달 AI는 이러한 다양한 데이터를 조합하여 더 풍부하고 유용한 결과를 도출하고자 하는 목적으로 사용됩니다.
여러 모달리티(Modalities)는 서로 다른 감각이나 유형의 정보를 의미합니다. 예를 들어, 텍스트 데이터는 언어적인 정보를 담고 있고, 이미지는 시각적 정보를 제공하며, 음성은 청각적 정보를 전달합니다. 멀티모달 AI는 이러한 다양한 정보를 종합적으로 이해하고 처리하여 보다 풍부하고 복합적인 작업을 수행할 수 있습니다.
비전(Vision) AI에서는 컬러 이미지와 뎁스 이미지 또는 라이다, 레이더 등 각종 센서 데이터를 함께 사용하는 방식이 존재합니다. 여러 센서의 결과를 합쳐 특정 작업을 수행하기 때문에 센서 퓨전이라고 표현하기도 합니다.
오늘은 멀티모달 AI 중에서도 언어-비전(Language-Vision) 분야에 대해 이야기해 보려 합니다. 언어-비전 멀티모달 AI는 주로 텍스트와 이미지 데이터를 동시에 활용하여 작업을 수행하는 인공 지능 시스템을 의미합니다. 이것은 자연어 처리(Natural Language Processing, NLP)와 컴퓨터 비전(Computer Vision) 분야의 기술을 통합하여, 언어적 정보와 시각적 정보를 조합하여 더 풍부하고 유용한 결과를 얻고자 하는 목적으로 사용됩니다.
이러한 멀티모달 AI는 여러 세부 분야로 나뉘게 되는데요. 몇 가지 예시는 다음과 같습니다.
- 이미지 캡션 생성 (Image Captioning): 모델은 이미지의 시각적 특징을 이해하고, 그에 맞는 자연어로 캡션을 생성합니다. 예를 들어, 고양이가 있는 이미지에 대한 설명을 생성할 수 있습니다.
- 시각적 질문 응답 (Visual Question Answering): 이미지와 관련된 질문에 대한 답을 자연어로 생성합니다. 이미지에 대한 질문에 대한 답을 이미지의 내용을 이해한 후에 생성할 수 있습니다.
- 이미지 분류 및 검색 (Image Classification and Retrieval): 이미지에 대한 텍스트 설명이나 태그를 활용하여 이미지를 분류하거나, 특정 텍스트 쿼리에 대한 이미지를 검색합니다.
- 감정 분석 (Emotion Analysis): 이미지와 관련된 얼굴 표정 및 텍스트 데이터를 결합하여 보다 정확한 감정 분석을 수행할 수 있습니다.
이러한 작업을 수행하기 위해서는 텍스트와 이미지 데이터를 통합적으로 이해하고 처리할 수 있는 모델이 필요합니다. 최근에는 대규모 언어 모델과 비전 모델을 결합한 다양한 언어-이미지 멀티모달 아키텍처가 개발되어 있습니다. 이러한 모델은 텍스트와 이미지의 상호 작용을 모델링하며, 사전 학습된 언어 모델과 비전 모델을 파인 튜닝(fine-tuning)하여 특정 작업에 맞게 적용할 수 있습니다.
CLIP (Contrastive Language-Image Pre-Training)
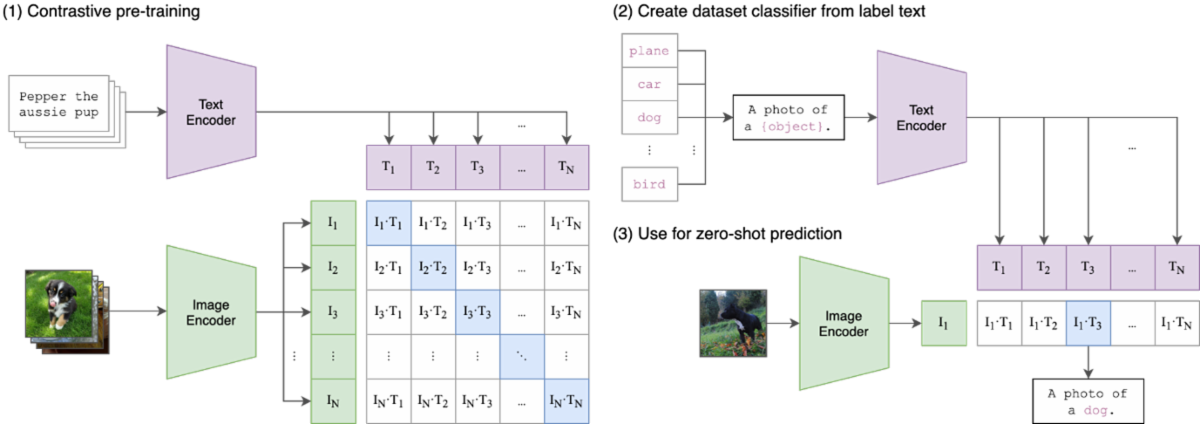
CLIP은 OpenAI에서 개발한 언어-이미지 멀티모달 AI 모델로 대규모 웹 언어-이미지 병렬 데이터셋에서 언어와 이미지 간의 상호 작용을 학습하는 방식으로 구성되어 있습니다. 이 모델은 굉장히 단순한 구조를 가졌지만 Zero-Shot 이미지 분류(Image Classification)과 같은 작업에서 뛰어난 성능을 보이며, 아직까지도 멀티모달 AI 모델에서 대표적인 모델로 손꼽히고 있습니다.
Zero-Shot 이미지 분류
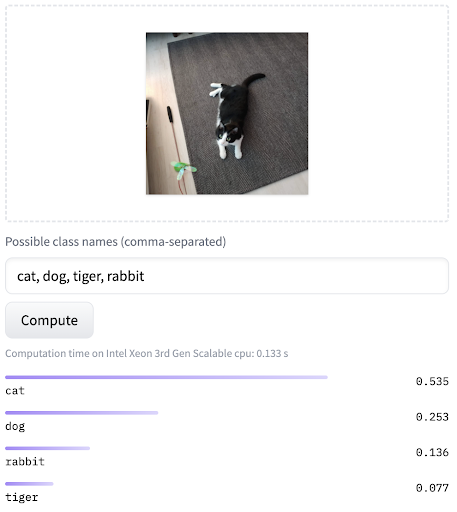
CLIP과 같은 멀티모달 모델은 학습 중에 학습한 언어적 표현과 이미지 특징을 활용하여, 학습 과정에서 보지 않은 클래스에 대한 이미지 분류를 수행할 수 있습니다. 이것이 Zero-Shot Learning의 핵심입니다. 모델이 이미지에 대한 언어적 표현과 이미지 자체의 특징을 고려하여 새로운 클래스에 대한 예측을 수행합니다. 구체적으로는 입력 이미지와 입력 이미지와의 유사도를 측정하고 싶은 텍스트 여러 개를 함께 모델에 입력하여, 해당 이미지와 가장 유사도가 높은 텍스트를 고르는 작업입니다.
VQA (Visual Question Answering)
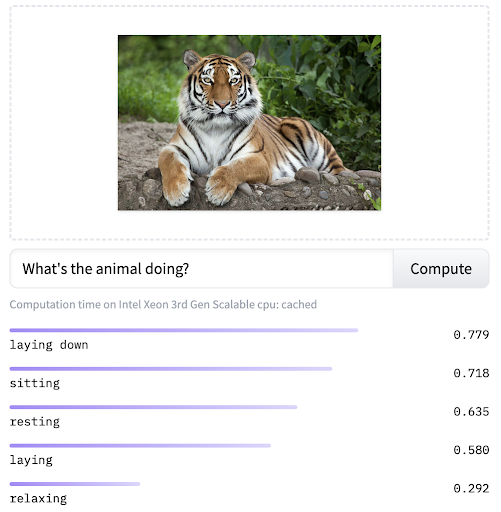
VQA는 입력 이미지와 관련된 질문에 대한 답을 자연어로 출력해 주는 작업입니다. 비전 데이터에 존재하는 객체나 배경에 대한 질문을 할 수도 있고, 인물의 상황과 행동에 관한 질문에 답을 얻을 수도 있습니다.
이미지 캡션 (Image Captioning)
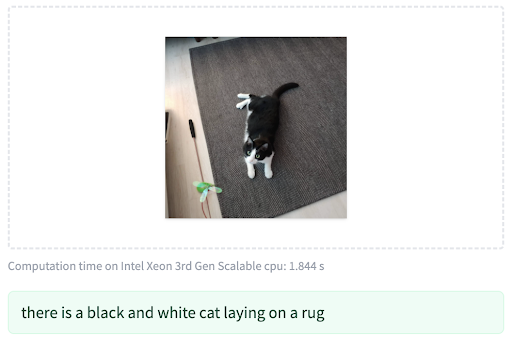
이미지 캡션은 입력 이미지에 대한 자연어 설명을 얻는 작업으로, 앞서 설명한 두 작업과는 달리 입력으로 이미지만 필요합니다. 설명이 필요한 이미지를 모델에 입력하면 위 예시처럼 이미지에 존재하는 객체와 배경에 대한 캡션을 얻을 수 있습니다.
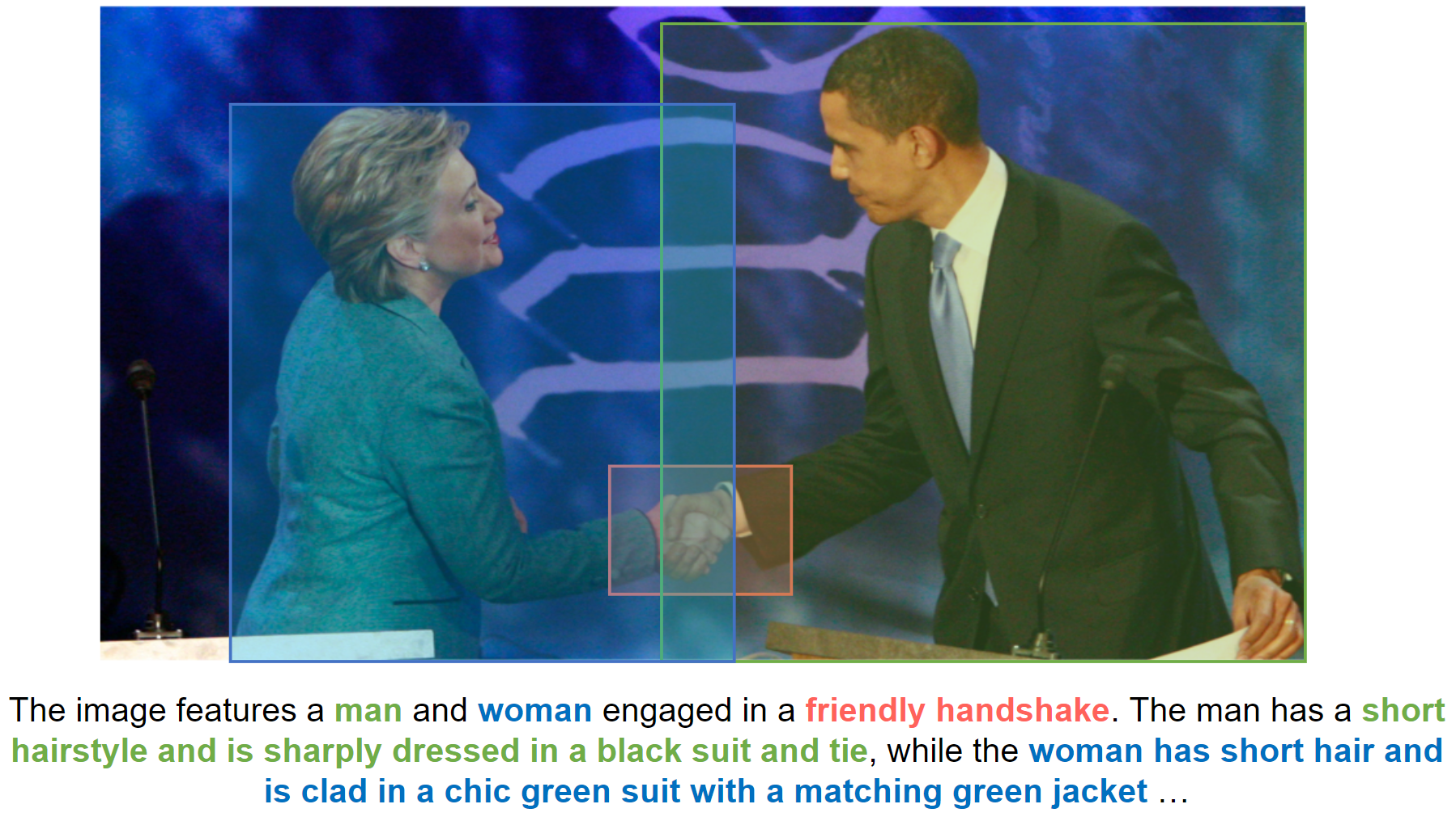
오늘은 언어와 비전 데이터를 함께 학습하는 멀티모달 AI에 대해 살펴봤습니다. AI 서비스가 언어와 비전 간의 경계를 넘나들면서, 멀티모달 기술이 더욱 중요해지고 있는 것 같습니다. 하지만 이러한 모델들은 대개 거대한 규모의 AI 모델이기 때문에, 학습이 쉽지 않다는 한계가 있습니다. 이에 대한 극복이 여전히 필요한 과제로 남아있습니다.
 | ||
이야기와 글쓰기를 좋아하는 컴퓨터비전 엔지니어 콤파스입니다. |
* 슈퍼브 블로그의 외부 기고 콘텐츠는 외부 전문가가 작성한 글로 운영 가이드라인에 따라 작성됩니다. 슈퍼브 블로그에서는 독자분들이 AI에 대한 소식을 더 쉽고 간편하게 이해하실 수 있도록 유용한 팁과 정보를 제공하고 있습니다.